This media is not supported in your browser
VIEW IN TELEGRAM
MCP-серверы могут предоставлять богатые UI-возможности
MCP-серверы в Claude/Cursor пока не предлагают никакого UI, например, графики. Это просто текст/JSON.
mcp-ui позволяет добавлять в вывод интерактивные веб-компоненты, которые может отрендерить MCP-клиент.
Забираем с GitHub
👉 @DataSciencegx
MCP-серверы в Claude/Cursor пока не предлагают никакого UI, например, графики. Это просто текст/JSON.
mcp-ui позволяет добавлять в вывод интерактивные веб-компоненты, которые может отрендерить MCP-клиент.
Забираем с GitHub
Please open Telegram to view this post
VIEW IN TELEGRAM
❤4
Годный проект с GitHub, который предоставляет единое sandbox-окружение для разработки AI-агентов. Он объединяет браузер, терминал, файловую систему, VS Code и Jupyter в одном Docker-контейнере, готовый к использованию "из коробки".
Все компоненты работают с общей файловой системой: файл, скачанный в браузере, сразу доступен в терминале или коде.
В контейнер также предустановлены несколько MCP-серверов, благодаря чему AI Agent может напрямую вызывать различные возможности без дополнительной сложной настройки окружения.
Есть поддержка Chrome DevTools Protocol для программного управления браузером, а также встроенный порт-форвардинг и мониторинг сервисов для удобного предпросмотра и отладки веб-приложений.
Предоставляются SDK для Python, TypeScript и Golang, запуск возможен в один клик через Docker.
GitHub: AIO Sandbox
👉 @DataSciencegx
Все компоненты работают с общей файловой системой: файл, скачанный в браузере, сразу доступен в терминале или коде.
В контейнер также предустановлены несколько MCP-серверов, благодаря чему AI Agent может напрямую вызывать различные возможности без дополнительной сложной настройки окружения.
Есть поддержка Chrome DevTools Protocol для программного управления браузером, а также встроенный порт-форвардинг и мониторинг сервисов для удобного предпросмотра и отладки веб-приложений.
Предоставляются SDK для Python, TypeScript и Golang, запуск возможен в один клик через Docker.
GitHub: AIO Sandbox
Please open Telegram to view this post
VIEW IN TELEGRAM
👍3❤2👎1
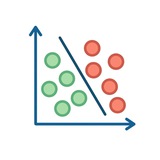
Генеративные vs. дискриминативные модели в ML
(популярный вопрос на собеседованиях по ML)
👉 @DataSciencegx
(популярный вопрос на собеседованиях по ML)
Please open Telegram to view this post
VIEW IN TELEGRAM
❤7👍1
Эта статья Себастьяна Рашки пошагово проводит через реализацию self-attention с нуля, далее расширяя разбор до multi-head и cross-attention, с понятными объяснениями и примерами кода на PyTorch.
Обязательное чтение, если хотите глубоко разобраться в трансформерах. Читайте здесь
👉 @DataSciencegx
Обязательное чтение, если хотите глубоко разобраться в трансформерах. Читайте здесь
Please open Telegram to view this post
VIEW IN TELEGRAM
❤3👍1
Forwarded from IT Portal
Стенфорд запустил бесплатный курс по Deep Learning, который ведёт основатель Coursera — Эндрю Ын
Программа охватывает всё: от базовых принципов нейросетей до LLM, RL, агентов, RAG и мультимодальных моделей
Первая лекция здесь. Материалы и расписание здесь
@IT_Portal
Программа охватывает всё: от базовых принципов нейросетей до LLM, RL, агентов, RAG и мультимодальных моделей
Первая лекция здесь. Материалы и расписание здесь
@IT_Portal
❤11👍5🤔1
Когда мы говорим про RAG, обычно думают так: проиндексировал документ → потом извлёк тот же самый документ.
Но индексация ≠ извлечение.
Данные, которые ты индексируешь, не обязаны быть теми же данными, которые ты подаёшь в LLM во время генерации.
Вот 4 умных способа индексировать данные:
1) Chunk Indexing (индексация чанков)
🔹 Самый распространённый подход.
🔹 Документ разбивается на чанки, затем каждый чанк преобразуется в эмбеддинг и сохраняется в векторную БД.
🔹 При запросе извлекаются ближайшие чанки по косинусному сходству (или другому метрике).
Просто и эффективно, но слишком большие или «шумные» чанки могут снизить точность.
2) Sub-chunk Indexing (индексация под-чанков)
🔹 Берём исходные чанки и дополнительно разбиваем их на более мелкие под-чанки.
🔹 Индексируем именно эти мелкие фрагменты.
🔹 При извлечении всё ещё возвращаем более крупный чанк для контекста.
Этот подход полезен, если документ содержит несколько разных концепций в одном разделе - повышается шанс точного совпадения с запросом.
3) Query Indexing (индексация по запросам)
🔹 Вместо того чтобы индексировать сырой текст, генерируются гипотетические вопросы, на которые, по мнению LLM, данный чанк может ответить.
🔹 Эти вопросы эмбеддятся и сохраняются.
🔹 При реальном запросе пользователя поиск происходит по этим «синтетическим» вопросам.
🔹 Похожая идея используется в HyDE, но там сопоставляется гипотетический ответ с реальными чанками.
Отличный вариант для систем вопрос–ответ (QA), поскольку он сокращает семантический разрыв между пользовательским запросом и индексированными данными.
4) Summary Indexing (индексация по суммаризации)
🔹 Используется LLM, чтобы сгенерировать краткое семантическое представление (summary) для каждого чанка.
🔹 В индекс попадает именно summary, а не исходный текст.
🔹 При извлечении возвращается оригинальный чанк для контекста.
Особенно эффективно для плотных или структурированных данных (например, CSV или таблиц), где эмбеддинги сырого текста не дают осмысленных результатов.
👉 @DataSciencegx
Но индексация ≠ извлечение.
Данные, которые ты индексируешь, не обязаны быть теми же данными, которые ты подаёшь в LLM во время генерации.
Вот 4 умных способа индексировать данные:
1) Chunk Indexing (индексация чанков)
Просто и эффективно, но слишком большие или «шумные» чанки могут снизить точность.
2) Sub-chunk Indexing (индексация под-чанков)
Этот подход полезен, если документ содержит несколько разных концепций в одном разделе - повышается шанс точного совпадения с запросом.
3) Query Indexing (индексация по запросам)
Отличный вариант для систем вопрос–ответ (QA), поскольку он сокращает семантический разрыв между пользовательским запросом и индексированными данными.
4) Summary Indexing (индексация по суммаризации)
Особенно эффективно для плотных или структурированных данных (например, CSV или таблиц), где эмбеддинги сырого текста не дают осмысленных результатов.
Please open Telegram to view this post
VIEW IN TELEGRAM
❤7👍3
3 ключевые свойства следа матрицы в Deep Learning
1. L2-регуляризация: Квадрат нормы Фробениуса,
2. Вычисление градиентов: Циклическое свойство следа,
3. Инвариантность: След инвариантен к замене базиса,
👉 @DataSciencegx
1. L2-регуляризация: Квадрат нормы Фробениуса,
||W||² = tr(WᵀW), используется для штрафования больших весов и предотвращения переобучения.2. Вычисление градиентов: Циклическое свойство следа,
tr(AB) = tr(BA), упрощает вывод матричных производных при обратном распространении ошибки (backpropagation).3. Инвариантность: След инвариантен к замене базиса,
tr(P⁻¹AP) = tr(A); это свойство используется при поиске нового, более удобного базиса в PCA.Please open Telegram to view this post
VIEW IN TELEGRAM
❤6👍1
This media is not supported in your browser
VIEW IN TELEGRAM
На GitHub есть репозиторий free-programming-books, где собрано более 4000 бесплатных книг, 2000 курсов и других полезных ресурсов по программированию
Для удобства поиска можно использовать этот инструмент
Этот проект - яркий пример силы опенсорс сообщества, который из клона списка со StackOverflow стал одним из самых популярных на GitHub✌️
🔸 Русскоязычная версия ресурсов
👉 @DataSciencegx
Для удобства поиска можно использовать этот инструмент
Этот проект - яркий пример силы опенсорс сообщества, который из клона списка со StackOverflow стал одним из самых популярных на GitHub
Please open Telegram to view this post
VIEW IN TELEGRAM
❤12👍2🤔1
Эндрю Ын анонсировал новый бесплатный курс: Agentic AI
Здесь учат собирать LLM-агентов с нуля, без фреймворков, на чистом Python. Всё чётко, с разбором того, как устроены агенты под капотом.
Что внутри:
- Reflection — агент сам анализирует свои ответы и улучшает их;
- Tool use — учим LLM вызывать функции: искать в вебе, слать письма, писать код;
- Planning — разбиваем задачи на подзадачи и строим план выполнения;
- Multi-agent collaboration — создаём несколько специализированных агентов, которые работают вместе, как команда.
Плюс отдельный блок про evals и анализ ошибок
В итоге соберёте исследовательского агента, который сам ищет, анализирует и пишет отчёты.
Проходится в своём темпе, подходит всем, кто знаком с Python и немного с LLM. Забираем здесь
👉 @DataSciencegx
Здесь учат собирать LLM-агентов с нуля, без фреймворков, на чистом Python. Всё чётко, с разбором того, как устроены агенты под капотом.
Что внутри:
- Reflection — агент сам анализирует свои ответы и улучшает их;
- Tool use — учим LLM вызывать функции: искать в вебе, слать письма, писать код;
- Planning — разбиваем задачи на подзадачи и строим план выполнения;
- Multi-agent collaboration — создаём несколько специализированных агентов, которые работают вместе, как команда.
Плюс отдельный блок про evals и анализ ошибок
В итоге соберёте исследовательского агента, который сам ищет, анализирует и пишет отчёты.
Проходится в своём темпе, подходит всем, кто знаком с Python и немного с LLM. Забираем здесь
Please open Telegram to view this post
VIEW IN TELEGRAM
❤8👍1👀1
Я никогда не использую метод
Skimpy — гораздо более удобная (и опенсорс) альтернатива, которая предоставляет расширенное описание данных: форму датасета, типы данных по колонкам, статистику, графики распределений и т.д.
👉 @DataSciencegx
describe из PandasSkimpy — гораздо более удобная (и опенсорс) альтернатива, которая предоставляет расширенное описание данных: форму датасета, типы данных по колонкам, статистику, графики распределений и т.д.
Please open Telegram to view this post
VIEW IN TELEGRAM
❤12🤔5👍3
Один из лучших ресурсов, если хочешь выучить SQL на практике и с нуля 👍
Это интерактивные уроки прямо в браузере, без регистрации и бесплатно. Всё подается шаг за шагом: от базовых запросов до более сложных тем, таких как JOIN и агрегации
Весь процесс строится на упражнениях, так что теорию сразу применяешь на практике
Всем, кто хочет научиться SQL с нуля, рекомендую заценить: https://sqlbolt.com/
👉 @DataSciencegx
Это интерактивные уроки прямо в браузере, без регистрации и бесплатно. Всё подается шаг за шагом: от базовых запросов до более сложных тем, таких как JOIN и агрегации
Весь процесс строится на упражнениях, так что теорию сразу применяешь на практике
Всем, кто хочет научиться SQL с нуля, рекомендую заценить: https://sqlbolt.com/
Please open Telegram to view this post
VIEW IN TELEGRAM
❤8🔥1🤔1
Бесплатный курс по изучению концепций глубокого обучения
Концептуальное и архитектурное путешествие по моделям компьютерного зрения в глубоком обучении, прослеживающее эволюцию от LeNet и AlexNet до ResNet, EfficientNet и Vision Transformers.
Курс объясняет принципы проектирования, лежащие в основе skip-соединений, bottleneck-блоков, сохранения тождества, компромиссов глубины/ширины и attention.
Каждая глава сочетает наглядные иллюстрации, исторический контекст и сравнения «бок о бок», чтобы показать, почему архитектуры выглядят именно так и как они обрабатывают информацию.
Забираем на YouTube
👉 @DataSciencegx
Концептуальное и архитектурное путешествие по моделям компьютерного зрения в глубоком обучении, прослеживающее эволюцию от LeNet и AlexNet до ResNet, EfficientNet и Vision Transformers.
Курс объясняет принципы проектирования, лежащие в основе skip-соединений, bottleneck-блоков, сохранения тождества, компромиссов глубины/ширины и attention.
Каждая глава сочетает наглядные иллюстрации, исторический контекст и сравнения «бок о бок», чтобы показать, почему архитектуры выглядят именно так и как они обрабатывают информацию.
Забираем на YouTube
Please open Telegram to view this post
VIEW IN TELEGRAM
❤5🤔1
Находка: репозиторий, где куча туториалов по созданию AI-агентов, готовых к продакшену и с реальными кейсами использования
Весь код в открытом доступе и есть объяснение, как их развернуть. GitHub: agents-towards-production
👉 @DataSciencegx
Весь код в открытом доступе и есть объяснение, как их развернуть. GitHub: agents-towards-production
Please open Telegram to view this post
VIEW IN TELEGRAM
❤1
This media is not supported in your browser
VIEW IN TELEGRAM
Наконец-то в Python 3.14 можно отключить GIL
Это большое событие, потому что раньше, даже если ты писал многопоточный код, Python всё равно выполнял только один поток за раз, без какого-либо прироста производительности.
А теперь Python действительно может выполнять твой многопоточный код параллельно.
И uv полностью это поддерживает!
👉 @DataSciencegx
Это большое событие, потому что раньше, даже если ты писал многопоточный код, Python всё равно выполнял только один поток за раз, без какого-либо прироста производительности.
А теперь Python действительно может выполнять твой многопоточный код параллельно.
И uv полностью это поддерживает!
Please open Telegram to view this post
VIEW IN TELEGRAM
❤18👍2🔥1
This media is not supported in your browser
VIEW IN TELEGRAM
AI Engineering Hub
Комплексный ресурс для изучения и разработки решений на базе AI. Здесь вы найдёте:
- 93+ продакшн-готовых проектов для любого уровня
- подробные туториалы по LLM, RAG, агентам и многому другому
- реальные примеры применения AI-агентов
- готовые примеры для внедрения, адаптации и масштабирования в ваших проектах
Забираем на GitHub
👉 @DataSciencegx
Комплексный ресурс для изучения и разработки решений на базе AI. Здесь вы найдёте:
- 93+ продакшн-готовых проектов для любого уровня
- подробные туториалы по LLM, RAG, агентам и многому другому
- реальные примеры применения AI-агентов
- готовые примеры для внедрения, адаптации и масштабирования в ваших проектах
Забираем на GitHub
Please open Telegram to view this post
VIEW IN TELEGRAM
❤7👍2🔥1
Все почему-то игнорируют эту новую OCR-модель. Chandra от Datalab заняла топовые позиции в независимых бенчмарках и обошла предыдущего лидера dots-ocr.
Поддерживает более 40 языков
Без проблем обрабатывает текст, таблицы и формулы
Я протестировал её на рукописном письме Рамануджана 1913 года.
Полностью опенсорс: GitHub
👉 @DataSciencegx
Поддерживает более 40 языков
Без проблем обрабатывает текст, таблицы и формулы
Я протестировал её на рукописном письме Рамануджана 1913 года.
Полностью опенсорс: GitHub
Please open Telegram to view this post
VIEW IN TELEGRAM
Please open Telegram to view this post
VIEW IN TELEGRAM
❤10🔥5
This media is not supported in your browser
VIEW IN TELEGRAM
RAG vs. CAG, понятное объяснение
RAG хорош, но у него есть серьёзная проблема
Каждый запрос бьёт по векторной БД. Даже ради статической информации, которая не менялась месяцами.
Это дорого, медленно и лишнее.
Cache-Augmented Generation (CAG) решает эту проблему, позволяя модели «помнить» статическую информацию прямо в своей key-value (KV) памяти.
Ещё лучше? Можно комбинировать RAG и CAG и получить лучшее из обоих подходов.
Как это работает:
RAG + CAG делит вашу базу знаний на два слоя:
↳ Статические данные (политики, документация) один раз кэшируются в KV-памяти модели
↳ Динамические данные (свежие апдейты, «живые» документы) подтягиваются через ретривал
Результат? Более быстрый инференс, меньше затрат, меньше избыточности.
Хитрость в том, чтобы избирательно кэшировать.
Кэшируйте только статичные, ценные знания, которые редко меняются. Если закэшируете всё, упрётесь в лимиты контекста. Разделение «cold» (кэшируемые) и «hot» (получаемые через ретривал) данных делает систему надёжной.
Можно начинать уже сегодня. OpenAI и Anthropic уже поддерживают кэширование промптов в своих API.
Вот ссылка на гайд OpenAI по кэшированию промптов: https://x.com/akshay_pachaar/status/1985690138756989286
Вы уже пробовали CAG в проде?
👉 @DataSciencegx
RAG хорош, но у него есть серьёзная проблема
Каждый запрос бьёт по векторной БД. Даже ради статической информации, которая не менялась месяцами.
Это дорого, медленно и лишнее.
Cache-Augmented Generation (CAG) решает эту проблему, позволяя модели «помнить» статическую информацию прямо в своей key-value (KV) памяти.
Ещё лучше? Можно комбинировать RAG и CAG и получить лучшее из обоих подходов.
Как это работает:
RAG + CAG делит вашу базу знаний на два слоя:
↳ Статические данные (политики, документация) один раз кэшируются в KV-памяти модели
↳ Динамические данные (свежие апдейты, «живые» документы) подтягиваются через ретривал
Результат? Более быстрый инференс, меньше затрат, меньше избыточности.
Хитрость в том, чтобы избирательно кэшировать.
Кэшируйте только статичные, ценные знания, которые редко меняются. Если закэшируете всё, упрётесь в лимиты контекста. Разделение «cold» (кэшируемые) и «hot» (получаемые через ретривал) данных делает систему надёжной.
Можно начинать уже сегодня. OpenAI и Anthropic уже поддерживают кэширование промптов в своих API.
Вот ссылка на гайд OpenAI по кэшированию промптов: https://x.com/akshay_pachaar/status/1985690138756989286
Вы уже пробовали CAG в проде?
Please open Telegram to view this post
VIEW IN TELEGRAM
❤8👍2
Введение в системы машинного обучения
Создано профессором Гарварда Виджаем Джанапа Редди. Это открытый учебник, который учит тебя строить реальные, работающие AI-системы: от edge-устройств до облака.
Он выводит обучение за пределы простого “тренируем модель” и показывает, как заставить модель действительно работать - cтабильно, эффективно и с высокой производительностью.
PDF-ка и онлайн версия доступны здесь, репозиторий тут
👉 @DataSciencegx
Создано профессором Гарварда Виджаем Джанапа Редди. Это открытый учебник, который учит тебя строить реальные, работающие AI-системы: от edge-устройств до облака.
Он выводит обучение за пределы простого “тренируем модель” и показывает, как заставить модель действительно работать - cтабильно, эффективно и с высокой производительностью.
PDF-ка и онлайн версия доступны здесь, репозиторий тут
Please open Telegram to view this post
VIEW IN TELEGRAM
❤11👍2
This media is not supported in your browser
VIEW IN TELEGRAM
XBOW привлекла $117 млн для разработки AI-агентов-хакеров
А теперь кто-то выложил аналог с открытым исходным кодом, бесплатно.
Strix — это автономные AI-агенты, которые действуют как реальные хакеры: они динамически выполняют ваш код, находят уязвимости и подтверждают их реальными proof-of-concept-эксплойтами.
Почему это важно:
Главная проблема классического security-тестирования - оно не успевает за скоростью разработки.
Strix решает это, интегрируясь прямо в ваш рабочий процесс:
↳ Запускайте его в CI/CD, чтобы ловить уязвимости до продакшена
↳ Получайте реальные PoC, а не ложные срабатывания от статического анализа
↳ Тестируйте всё: инъекции, контроль доступа, ошибки бизнес-логики
И самое крутое:
Вам не нужно быть экспертом по безопасности. Strix включает полный набор инструментов хакера: HTTP-прокси, автоматизацию браузера и Python runtime для разработки эксплойтов.
Это как если бы у вас была команда безопасности, работающая с той же скоростью, что и ваш CI/CD pipeline.
К тому же инструмент запускается локально в Docker-контейнерах, ваш код никогда не покидает ваше окружение.
Начать очень просто:
Укажите путь к вашему коду: приложению, репозиторию или директории.
Ссылка на GitHub-репозиторий: strix
👉 @DataSciencegx
А теперь кто-то выложил аналог с открытым исходным кодом, бесплатно.
Strix — это автономные AI-агенты, которые действуют как реальные хакеры: они динамически выполняют ваш код, находят уязвимости и подтверждают их реальными proof-of-concept-эксплойтами.
Почему это важно:
Главная проблема классического security-тестирования - оно не успевает за скоростью разработки.
Strix решает это, интегрируясь прямо в ваш рабочий процесс:
↳ Запускайте его в CI/CD, чтобы ловить уязвимости до продакшена
↳ Получайте реальные PoC, а не ложные срабатывания от статического анализа
↳ Тестируйте всё: инъекции, контроль доступа, ошибки бизнес-логики
И самое крутое:
Вам не нужно быть экспертом по безопасности. Strix включает полный набор инструментов хакера: HTTP-прокси, автоматизацию браузера и Python runtime для разработки эксплойтов.
Это как если бы у вас была команда безопасности, работающая с той же скоростью, что и ваш CI/CD pipeline.
К тому же инструмент запускается локально в Docker-контейнерах, ваш код никогда не покидает ваше окружение.
Начать очень просто:
pipx install strix-agentУкажите путь к вашему коду: приложению, репозиторию или директории.
Ссылка на GitHub-репозиторий: strix
Please open Telegram to view this post
VIEW IN TELEGRAM
🔥7❤5
Please open Telegram to view this post
VIEW IN TELEGRAM
🔥4👍3❤2👎1