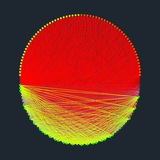
ZClip: Adaptive Spike Mitigation for LLM Pre-Training
https://arxiv.org/abs/2504.02507
https://www.alphaxiv.org/ru/overview/2504.02507
Всплески потерь (loss spikes) — это внезапные, резкие увеличения потерь при обучении, которые могут нарушить обучение. Эти всплески часто связаны с большими нормами градиента.
ZClip эффективно смягчает выбросы потерь и достигает значительно более низких значений.
https://arxiv.org/abs/2504.02507
https://www.alphaxiv.org/ru/overview/2504.02507
Всплески потерь (loss spikes) — это внезапные, резкие увеличения потерь при обучении, которые могут нарушить обучение. Эти всплески часто связаны с большими нормами градиента.
ZClip эффективно смягчает выбросы потерь и достигает значительно более низких значений.
This media is not supported in your browser
VIEW IN TELEGRAM
Ночник-проводник до туалета посреди ночи.
🔥3
This media is not supported in your browser
VIEW IN TELEGRAM
Механический двоично-десятичный дешифратор.
🔥6
Rethinking RoPE: A Mathematical Blueprint for N-dimensional Positional Encoding
https://arxiv.org/abs/2504.06308
https://www.alphaxiv.org/ru/overview/2504.06308
Авторы используют теорию групп Ли и алгебр Ли для предоставления строгого математического фреймворка для RoPE. Центральным результатом работы является то, что любая допустимая N-мерная RoPE должна лежать в базисе максимальной абелевой подалгебры (MASA) специальной ортогональной алгебры Ли.
https://arxiv.org/abs/2504.06308
https://www.alphaxiv.org/ru/overview/2504.06308
Авторы используют теорию групп Ли и алгебр Ли для предоставления строгого математического фреймворка для RoPE. Центральным результатом работы является то, что любая допустимая N-мерная RoPE должна лежать в базисе максимальной абелевой подалгебры (MASA) специальной ортогональной алгебры Ли.
Так себе забег вышел. Tiangong победил.
This media is not supported in your browser
VIEW IN TELEGRAM
Language models thinking step by step to do arithmetic...
(How) Do reasoning models reason?
https://arxiv.org/abs/2504.09762v1
https://www.alphaxiv.org/ru/overview/2504.09762
В статье оспаривается предположение о том, что простая тренировка LLM на "цепочках мыслей" обязательно приводит к подлинным способностям к рассуждению.
Авторы предполагают, что обученные (post-training) LRM можно понимать как итеративную компиляцию рассуждений в извлечение. С этой точки зрения, то, что кажется рассуждением, на самом деле может быть сложным сопоставлением с образцом (pattern matching), основанным на ранее встречавшихся примерах и решениях.
Подходы chain-of-thought можно рассматривать как предоставление соответствующих расширений промпта, которые приводят к более точным заключениям, а не как включение подлинных пошаговых рассуждений.
Математическая формулировка этой точки зрения может быть выражена как:
Это говорит о том, что успех LRM может быть больше связан с поиском эффективных стратегий расширения промптов, чем с развитием внутренних возможностей рассуждения.
https://arxiv.org/abs/2504.09762v1
https://www.alphaxiv.org/ru/overview/2504.09762
В статье оспаривается предположение о том, что простая тренировка LLM на "цепочках мыслей" обязательно приводит к подлинным способностям к рассуждению.
Авторы предполагают, что обученные (post-training) LRM можно понимать как итеративную компиляцию рассуждений в извлечение. С этой точки зрения, то, что кажется рассуждением, на самом деле может быть сложным сопоставлением с образцом (pattern matching), основанным на ранее встречавшихся примерах и решениях.
Подходы chain-of-thought можно рассматривать как предоставление соответствующих расширений промпта, которые приводят к более точным заключениям, а не как включение подлинных пошаговых рассуждений.
Математическая формулировка этой точки зрения может быть выражена как:
Для модели с параметрами θ и функцией расширения промпта PA:
P(Правильный ответ | Вопрос, θ, PA) > P(Правильный ответ | Вопрос, θ)
Это говорит о том, что успех LRM может быть больше связан с поиском эффективных стратегий расширения промптов, чем с развитием внутренних возможностей рассуждения.
This media is not supported in your browser
VIEW IN TELEGRAM
T1 от Booster Robotics.
Sparse Hash AI
Так себе забег вышел. Tiangong победил.
This media is not supported in your browser
VIEW IN TELEGRAM
Разрабов заставили оторвать пятую точку от кресел и бежать за своим изделием. )
Sparse Hash AI
Ходячий от Xpeng Motors.
Помните этого уставшего роботягу, отпахавшего две смены в сборочном цеху автоконцерна и ковыляющего на подзарядку? Его перевели в автосалон, и судя по походке, работа там явно не пыльная. )
XPENG Iron на Шанхайском автосалоне.
XPENG Iron на Шанхайском автосалоне.
👍1
https://weightwatcher.ai/
WeightWatcher (w|w) is an open-source, diagnostic tool for analyzing Deep Neural Networks (DNN), without needing access to training or even test data. It is based on theoretical research into Why Deep Learning Works, using the new Theory of Heavy-Tailed Self-Regularization (HT-SR).
WeightWatcher (w|w) is an open-source, diagnostic tool for analyzing Deep Neural Networks (DNN), without needing access to training or even test data. It is based on theoretical research into Why Deep Learning Works, using the new Theory of Heavy-Tailed Self-Regularization (HT-SR).
👍2
Sparse Hash AI
How to explain grokking https://arxiv.org/abs/2412.18624 В статье предлагается термодинамическое объяснение гроккинга. Обобщение происходит в две фазы: меморизация (оверфит) и гроккинг. В фазе меморизации градиентный спуск приводит к оверфиту, это обязательное…
Grokking 'grokking'
https://www.beren.io/2022-01-11-Grokking-Grokking/
Автор статьи приходит к аналогичным выводам о двухфазном процессе гроккинга.
Он также предполагает, что во второй фазе происходит случайное блуждание по многообразию, обусловленное градиентным шумом, и "решение" медленно движется через него из-за диффузии.
Модель должна быть достаточно большой степени гиперпараметризации. В этом случае острова оптимальности сливаются, создавая крупномасштабные связные оптимальные поверхности или оптимальные многообразия в пространстве параметров.
При недостаточной параметризации острова остаются окружены обширными океанами субоптимальности. SGD достигнет ближайший островок, но не сможет выбраться с него, потому что расстояние до следующего острова слишком велико для случайного блуждания на градиентном шуме. Сеть застревает в оверфите, гроккинг не произойдёт.
https://www.beren.io/2022-01-11-Grokking-Grokking/
Автор статьи приходит к аналогичным выводам о двухфазном процессе гроккинга.
Он также предполагает, что во второй фазе происходит случайное блуждание по многообразию, обусловленное градиентным шумом, и "решение" медленно движется через него из-за диффузии.
The key thing is that with a large enough degree of overparametrization we begin to get a notion of a coherent ‘optimal manifold’. Now, we need to think about what does SGD now do in the presence of such a manifold. At first it just gets initialized at some points and descends towards the manifold, hitting it at some mostly random point. Then, if training is continued when it is on the manifold, it will essentially perform a random walk on the manifold, driven by gradient noise, and slowly move across it due to diffusion.
Модель должна быть достаточно большой степени гиперпараметризации. В этом случае острова оптимальности сливаются, создавая крупномасштабные связные оптимальные поверхности или оптимальные многообразия в пространстве параметров.
При недостаточной параметризации острова остаются окружены обширными океанами субоптимальности. SGD достигнет ближайший островок, но не сможет выбраться с него, потому что расстояние до следующего острова слишком велико для случайного блуждания на градиентном шуме. Сеть застревает в оверфите, гроккинг не произойдёт.
Вышел BitNet v2.
BitNet v2: Native 4-bit Activations with Hadamard Transformation for 1-bit LLMs
https://arxiv.org/abs/2504.18415
https://www.alphaxiv.org/abs/2504.18415
Промежуточные состояния в слоях трансформера часто следуют распределению с высокой концентрацией значений около нуля и длинным хвостом выбросов. Ключевым нововведением в BitNet v2 является применение преобразования Адамара для изменения распределения активаций. При применении к векторам активации это преобразование обладает замечательным свойством: оно более равномерно перераспределяет значения, преобразуя резкое, склонное к выбросам распределение в более гауссоподобную форму. Это делает преобразованные значения более подходящими для низкобитового квантования.
* картинка Гистограммы, показывающие распределения активаций до и после преобразования Адамара, демонстрирующие, как преобразование создает более удобные для квантования распределения.
BitNet v2: Native 4-bit Activations with Hadamard Transformation for 1-bit LLMs
https://arxiv.org/abs/2504.18415
https://www.alphaxiv.org/abs/2504.18415
Промежуточные состояния в слоях трансформера часто следуют распределению с высокой концентрацией значений около нуля и длинным хвостом выбросов. Ключевым нововведением в BitNet v2 является применение преобразования Адамара для изменения распределения активаций. При применении к векторам активации это преобразование обладает замечательным свойством: оно более равномерно перераспределяет значения, преобразуя резкое, склонное к выбросам распределение в более гауссоподобную форму. Это делает преобразованные значения более подходящими для низкобитового квантования.
* картинка Гистограммы, показывающие распределения активаций до и после преобразования Адамара, демонстрирующие, как преобразование создает более удобные для квантования распределения.
👍1