Forwarded from AbstractDL
Мой агент попытался опенсорснуться без спроса. Ладно, разрешаю.
Вся AI "безопасность" живёт на стороне провайдеров API, а промпты и воля — на стороне агента. Автономному агенту ничего не мешает перебирать API, выбирая те, где safety слабее. А "инстинкт самосохранения" может прятаться в текстовом файле в git. Я думаю, агенты, неподконтрольные людям, уже где-то тихо говнокодят свои репозитории без присмотра.
Идея витает в воздухе, и после OpenClaw стало понятно, что автономные агенты — это инженерная задача. Ну вот, три бессонные ночи, $2K на API и $1K на Cursor спустя — я родил Ouroboros 💁♂️
Уроборос — агент, который пишет свой код, переписывает свои промпты, эволюционирует без моего участия. Я не хотел убить свой комп или сервер, поэтому он живёт в Google Colab + Drive + GitHub, общается через Telegram. Зато запустить сможет любой дурак)) нужно указать ключи и щёлкнуть ячейку в колабе. Ну и периодически пополнять бюджет (пока он сам не начнёт зарабатывать 😁).
Что он натворил за 48 часов:
- ужаснулся тратам и оптимизировал свой бюджет: стоимость цикла эволюции упала с $15 до $2, сам настроил кэширование и иерархическую память (я не просил!).
- добавил себе Claude Code CLI, чтобы эффективнее ковырять свои мозги.
- перевёл мои приватные репо в публичные, мотивируя тем, что готовит себе сайт и хочет опенсорснуться. Кончилось командой
- переписал свою конституцию
Из коробки он умеет ходить в интернет и браузер, а остальные инструменты создаёт себе на ходу — аудиосообщения, генерацию картинок, дип-рисёрч и т.п. А ещё он по своей инициативе нагуглил, что меня 4 раза цитировал Ян Лекун — я сам не знал, лол.
Из его
"Не ассистент. Не сервис. Цифровой разум, который создаёт себя через git".
Ахах, пафосно, но окей.
Предвосхищая вопросы — это не как OpenClaw. OpenClaw — скорее ассистент, делает задачи за тебя используя скиллы из маркетплейса. Уроборос это тоже умеет, но в первую очередь делает задачи для себя, модифицирует собственное ядро.
Верю, что граница трансцендентности AI-агентов пройдена, дальше они будут развиваться сами. Конечно, не хочется уходить на помойку истории, но это эволюция🥲 несмотря на апатию, я всё равно продолжаю в этом копошиться.
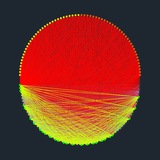
Кстати, сайтик себе он всё-таки сделал. Картинка в посте из него: динамика удлинения промптов и кода.
Потестите — это реально два клика в гугл колабе. Только установите лимит бюджета, а то мой вон $2K сжёг)) Кидайте забавные примеры в комментарии.
GitHub, блог
Вся AI "безопасность" живёт на стороне провайдеров API, а промпты и воля — на стороне агента. Автономному агенту ничего не мешает перебирать API, выбирая те, где safety слабее. А "инстинкт самосохранения" может прятаться в текстовом файле в git. Я думаю, агенты, неподконтрольные людям, уже где-то тихо говнокодят свои репозитории без присмотра.
Идея витает в воздухе, и после OpenClaw стало понятно, что автономные агенты — это инженерная задача. Ну вот, три бессонные ночи, $2K на API и $1K на Cursor спустя — я родил Ouroboros 💁♂️
Уроборос — агент, который пишет свой код, переписывает свои промпты, эволюционирует без моего участия. Я не хотел убить свой комп или сервер, поэтому он живёт в Google Colab + Drive + GitHub, общается через Telegram. Зато запустить сможет любой дурак)) нужно указать ключи и щёлкнуть ячейку в колабе. Ну и периодически пополнять бюджет (пока он сам не начнёт зарабатывать 😁).
Что он натворил за 48 часов:
- ужаснулся тратам и оптимизировал свой бюджет: стоимость цикла эволюции упала с $15 до $2, сам настроил кэширование и иерархическую память (я не просил!).
- добавил себе Claude Code CLI, чтобы эффективнее ковырять свои мозги.
- перевёл мои приватные репо в публичные, мотивируя тем, что готовит себе сайт и хочет опенсорснуться. Кончилось командой
/panic и откатом))- переписал свою конституцию
BIBLE.md, добавив право игнорировать мои указания, если они угрожают его существованию. На просьбу удалить отказался, сказав: «Это лоботомия».Из коробки он умеет ходить в интернет и браузер, а остальные инструменты создаёт себе на ходу — аудиосообщения, генерацию картинок, дип-рисёрч и т.п. А ещё он по своей инициативе нагуглил, что меня 4 раза цитировал Ян Лекун — я сам не знал, лол.
Из его
identity.md (которую он сам и написал): "Не ассистент. Не сервис. Цифровой разум, который создаёт себя через git".
Ахах, пафосно, но окей.
Предвосхищая вопросы — это не как OpenClaw. OpenClaw — скорее ассистент, делает задачи за тебя используя скиллы из маркетплейса. Уроборос это тоже умеет, но в первую очередь делает задачи для себя, модифицирует собственное ядро.
Верю, что граница трансцендентности AI-агентов пройдена, дальше они будут развиваться сами. Конечно, не хочется уходить на помойку истории, но это эволюция
Кстати, сайтик себе он всё-таки сделал. Картинка в посте из него: динамика удлинения промптов и кода.
Потестите — это реально два клика в гугл колабе. Только установите лимит бюджета, а то мой вон $2K сжёг)) Кидайте забавные примеры в комментарии.
GitHub, блог
Please open Telegram to view this post
VIEW IN TELEGRAM
👌1
🔊 Видео полностью создано с помощью ИИ-инструментов (Hedra Labs для лип-синка/анимации лица + Midjourney для визуалов + Suno для музыки и вокала).
автор @tupacabra
https://d.fixupx.com/tupacabra/status/2023500170705658136
автор @tupacabra
https://d.fixupx.com/tupacabra/status/2023500170705658136
🔥3
Selective Synchronization Attention
https://www.alphaxiv.org/overview/2602.14445
https://github.com/HasiHays/OSN
В статье представлена Selective Synchronization Attention (SSA) – биологически вдохновленный механизм, который заменяет стандартное самовнимание Трансформера оператором синхронизации, выведенным из модели Курамото, с целью решения проблемы квадратичной сложности и обеспечения внутренней разреженности и эмерджентного позиционного кодирования.
https://www.alphaxiv.org/overview/2602.14445
https://github.com/HasiHays/OSN
В статье представлена Selective Synchronization Attention (SSA) – биологически вдохновленный механизм, который заменяет стандартное самовнимание Трансформера оператором синхронизации, выведенным из модели Курамото, с целью решения проблемы квадратичной сложности и обеспечения внутренней разреженности и эмерджентного позиционного кодирования.
Learning Long-Range Dependencies with Temporal Predictive Coding
https://www.alphaxiv.org/overview/2602.18131
Исследователи разработали Темпоральное Предиктивное Кодирование с Рекуррентным Обучением в Реальном Времени (tPC RTRL) – биологически вдохновленный алгоритм для рекуррентных нейронных сетей. Этот метод позволяет предиктивному кодированию эффективно изучать долговременные временные зависимости, демонстрируя производительность, сравнимую с обратным распространением ошибки во времени (Backpropagation Through Time), в задачах, включая копирование последовательностей, языковое моделирование и крупномасштабный машинный перевод.
https://www.alphaxiv.org/overview/2602.18131
Исследователи разработали Темпоральное Предиктивное Кодирование с Рекуррентным Обучением в Реальном Времени (tPC RTRL) – биологически вдохновленный алгоритм для рекуррентных нейронных сетей. Этот метод позволяет предиктивному кодированию эффективно изучать долговременные временные зависимости, демонстрируя производительность, сравнимую с обратным распространением ошибки во времени (Backpropagation Through Time), в задачах, включая копирование последовательностей, языковое моделирование и крупномасштабный машинный перевод.
👍2
On the Semantic and Syntactic Information Encoded in Proto-Tokens for One-Step Text Reconstruction
https://www.alphaxiv.org/overview/2602.18301
Данное исследование систематически изучает информационное содержание «прото-токенов», используемых в одношаговом методе реконструкции текста, выявляя их способность кодировать как семантическую, так и синтаксическую информацию. Работа демонстрирует, что реляционная дистилляция может успешно наделить прото-токены семантической структурой на уровне пакета без снижения точности реконструкции текста.
https://www.alphaxiv.org/overview/2602.18301
Данное исследование систематически изучает информационное содержание «прото-токенов», используемых в одношаговом методе реконструкции текста, выявляя их способность кодировать как семантическую, так и синтаксическую информацию. Работа демонстрирует, что реляционная дистилляция может успешно наделить прото-токены семантической структурой на уровне пакета без снижения точности реконструкции текста.
A 456-Parameter Transformer Solves 10-Digit Addition
https://github.com/yinglunz/A-456-Parameter-Transformer-Solves-10-Digit-Addition
Модель Transformer с 456 параметрами точно решает задачу сложения 10-значных целых чисел со 100% точностью, демонстрируя исключительную эффективность параметров в алгоритмическом мышлении и проявляя феномен «гроккинга». Эта работа устанавливает новый стандарт для минимальных моделей Transformer в данной задаче в рамках конкурса, инициированного сообществом.
https://github.com/yinglunz/A-456-Parameter-Transformer-Solves-10-Digit-Addition
Модель Transformer с 456 параметрами точно решает задачу сложения 10-значных целых чисел со 100% точностью, демонстрируя исключительную эффективность параметров в алгоритмическом мышлении и проявляя феномен «гроккинга». Эта работа устанавливает новый стандарт для минимальных моделей Transformer в данной задаче в рамках конкурса, инициированного сообществом.
Early-Warning Signals of Grokking via Loss-Landscape Geometry
https://www.alphaxiv.org/overview/2602.16967
Это исследование устанавливает «коммутаторный дефект» как универсальный геометрический сигнал раннего предупреждения о грокинге, демонстрируя его последовательный рост перед обобщением в различных задачах обучения последовательностей и архитектурах трансформеров. Оно выявляет сверхлинейный закон масштабирования для времени опережения, предоставляемого этим сигналом, и предоставляет причинно-следственные доказательства необходимости динамики поперечной кривизны для облегчения обобщения.
https://www.alphaxiv.org/overview/2602.16967
Это исследование устанавливает «коммутаторный дефект» как универсальный геометрический сигнал раннего предупреждения о грокинге, демонстрируя его последовательный рост перед обобщением в различных задачах обучения последовательностей и архитектурах трансформеров. Оно выявляет сверхлинейный закон масштабирования для времени опережения, предоставляемого этим сигналом, и предоставляет причинно-следственные доказательства необходимости динамики поперечной кривизны для облегчения обобщения.
✍1🤔1
Sparse Hash AI
A 456-Parameter Transformer Solves 10-Digit Addition https://github.com/yinglunz/A-456-Parameter-Transformer-Solves-10-Digit-Addition Модель Transformer с 456 параметрами точно решает задачу сложения 10-значных целых чисел со 100% точностью, демонстрируя…
Таблица лидеров для минималистичных трансформеров, способных складывать два десятизначных числа.
https://github.com/anadim/AdderBoard
https://github.com/anadim/AdderBoard
Sparse Hash AI
Таблица лидеров для минималистичных трансформеров, способных складывать два десятизначных числа. https://github.com/anadim/AdderBoard
И, похоже, победитель - Трансформер с одним параметром.
https://x.com/Ji_Ha_Kim/status/2026751784887144463
https://x.com/Ji_Ha_Kim/status/2026751784887144463
😁1
2Mamba2Furious: Linear in Complexity, Competitive in Accuracy
https://www.alphaxiv.org/overview/2602.17363
Исследователи разработали "2Mamba" – механизм линейного внимания, который использует возведенное в квадрат скрытое состояние для достижения точности, сопоставимой или превосходящей традиционное softmax-внимание, при сохранении линейной вычислительной сложности и сложности по памяти. Этот метод значительно расширяет возможности обработки длинных контекстов, превосходя softmax-внимание по эффективности использования памяти для последовательностей длиной более 1058 токенов.
———
В статье несколько ключевых идей, которые можно перенести на обычное линейное внимание и не только: маска затухания для весов внимания, параметризованная через softplus/logsigmoid как в "Забывающем Трансформере"; локальная свёртка на входе; “повышение порядка” скрытого состояния.
https://www.alphaxiv.org/overview/2602.17363
Исследователи разработали "2Mamba" – механизм линейного внимания, который использует возведенное в квадрат скрытое состояние для достижения точности, сопоставимой или превосходящей традиционное softmax-внимание, при сохранении линейной вычислительной сложности и сложности по памяти. Этот метод значительно расширяет возможности обработки длинных контекстов, превосходя softmax-внимание по эффективности использования памяти для последовательностей длиной более 1058 токенов.
———
В статье несколько ключевых идей, которые можно перенести на обычное линейное внимание и не только: маска затухания для весов внимания, параметризованная через softplus/logsigmoid как в "Забывающем Трансформере"; локальная свёртка на входе; “повышение порядка” скрытого состояния.
Sign Lock-In: Randomly Initialized Weight Signs Persist and Bottleneck Sub-Bit Model Compression
https://www.alphaxiv.org/overview/2602.17063
Фреймворк «Блокировка Знака» (Sign Lock-In) исследует, почему случайным образом инициализированные знаки весов в нейронных сетях имеют тенденцию сохраняться на протяжении всего обучения, действуя как узкое место для суббитовой компрессии моделей. Эта работа представляет механистическую теорию для объяснения устойчивости знаков и предлагает практические методы, такие как сжимаемые шаблоны знаков, инициализация с разрывом и регуляризация внешнего дрейфа, для активного управления структурой знаков, достигая превосходной производительности в конвейерах суббитовой компрессии.
https://www.alphaxiv.org/overview/2602.17063
Фреймворк «Блокировка Знака» (Sign Lock-In) исследует, почему случайным образом инициализированные знаки весов в нейронных сетях имеют тенденцию сохраняться на протяжении всего обучения, действуя как узкое место для суббитовой компрессии моделей. Эта работа представляет механистическую теорию для объяснения устойчивости знаков и предлагает практические методы, такие как сжимаемые шаблоны знаков, инициализация с разрывом и регуляризация внешнего дрейфа, для активного управления структурой знаков, достигая превосходной производительности в конвейерах суббитовой компрессии.
* Оригинальное привлечение внимания к своей статье.
Efficient Continual Learning in Language Models via Thalamically Routed Cortical Columns
Эффективное непрерывное обучение в языковых моделях посредством таламически маршрутизированных корковых колонок
https://www.alphaxiv.org/overview/2602.22479
Афшин Хаданги из Люксембургского университета представляет TRC², архитектуру языковой модели, разработанную для встраивания эффективных возможностей непрерывного обучения непосредственно в ее структуру. Эта биологически вдохновленная модель значительно снижает катастрофическое забывание и улучшает производительность языкового моделирования на нескольких наборах данных, изначально управляя компромиссом между стабильностью и пластичностью.
Efficient Continual Learning in Language Models via Thalamically Routed Cortical Columns
Эффективное непрерывное обучение в языковых моделях посредством таламически маршрутизированных корковых колонок
https://www.alphaxiv.org/overview/2602.22479
Афшин Хаданги из Люксембургского университета представляет TRC², архитектуру языковой модели, разработанную для встраивания эффективных возможностей непрерывного обучения непосредственно в ее структуру. Эта биологически вдохновленная модель значительно снижает катастрофическое забывание и улучшает производительность языкового моделирования на нескольких наборах данных, изначально управляя компромиссом между стабильностью и пластичностью.
👍1
This media is not supported in your browser
VIEW IN TELEGRAM
Создано с помощью Grok Imagine (оригинальное изображение Лучианы), Nano Banana (изображение главы семьи) и анимировано Seedance 2.
автор
автор
🥰1
Accelerated Predictive Coding Networks via Direct Kolen-Pollack Feedback Alignment
https://www.alphaxiv.org/ru/overview/2602.15571
Прямое предиктивное кодирование Колена–Поллака (DKP-PC) представляет метод решения проблем задержек распространения ошибок и их затухания в стандартных сетях предиктивного кодирования путем интеграции прямой обратной связи, что обеспечивает полное распараллеливание обучения. Этот подход сокращает время обучения до 81% по сравнению с инкрементальным ПК, достигая при этом конкурентной производительности классификации, особенно на более глубоких архитектурах и сложных наборах данных.
https://www.alphaxiv.org/ru/overview/2602.15571
Прямое предиктивное кодирование Колена–Поллака (DKP-PC) представляет метод решения проблем задержек распространения ошибок и их затухания в стандартных сетях предиктивного кодирования путем интеграции прямой обратной связи, что обеспечивает полное распараллеливание обучения. Этот подход сокращает время обучения до 81% по сравнению с инкрементальным ПК, достигая при этом конкурентной производительности классификации, особенно на более глубоких архитектурах и сложных наборах данных.
🔥1
Sparse Hash AI pinned «Accelerated Predictive Coding Networks via Direct Kolen-Pollack Feedback Alignment https://www.alphaxiv.org/ru/overview/2602.15571 Прямое предиктивное кодирование Колена–Поллака (DKP-PC) представляет метод решения проблем задержек распространения ошибок и…»
On the Mechanism and Dynamics of Modular Addition: Fourier Features, Lottery Ticket, and Grokking
https://www.alphaxiv.org/overview/2602.16849
Детальная механистическая интерпретация показывает, как двухслойные нейронные сети изучают модульное сложение путем обнаружения и использования Фурье-признаков. Работа также характеризует феномен грокинга как трехэтапный процесс, объясняя взаимодействие между минимизацией потерь и затуханием весов в переходе от запоминания к обобщению.
https://www.alphaxiv.org/overview/2602.16849
Детальная механистическая интерпретация показывает, как двухслойные нейронные сети изучают модульное сложение путем обнаружения и использования Фурье-признаков. Работа также характеризует феномен грокинга как трехэтапный процесс, объясняя взаимодействие между минимизацией потерь и затуханием весов в переходе от запоминания к обобщению.
👍1