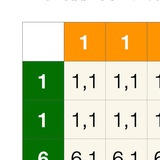
Согласно опросам, больше половины Go-разработчиков используют AI-кодогенерацию через тот или иной инструмент (https://devcrowd.ru/go-2024/skills_06/)
при этом я видел еще такой любопытный график по США (не смог найти, может позже найду), где видно, что с момента появления chatGPT вакансий entry level специалистов всё меньше и меньше в процентах к общему их количеству, уже где-то на треть меньше стало за эти пару лет. Там не только программеры, а в целом.
Какие тут можно сделать выводы. Прогнозы оправдываются: чем объяснять джуниору, как делать простую задачу, иногда проще сгенерить код гопчатом и чуток поправить.
У дизайнеров тоже самое: арт-директор по-прежнему нужен, но проходной говнобуклет для ООО "Ромашка" проще сгенерить. Раньше для этого использовали начинающих фрилансеров.
В общем, если когда-то про замену профессий ИИ - это были лишь рассуждения, то теперь это статистика. Как будут обучаться новые кадры, если тенденция продолжится, я не понимаю.
🫥 Cross Join
⠀
при этом я видел еще такой любопытный график по США (не смог найти, может позже найду), где видно, что с момента появления chatGPT вакансий entry level специалистов всё меньше и меньше в процентах к общему их количеству, уже где-то на треть меньше стало за эти пару лет. Там не только программеры, а в целом.
Какие тут можно сделать выводы. Прогнозы оправдываются: чем объяснять джуниору, как делать простую задачу, иногда проще сгенерить код гопчатом и чуток поправить.
У дизайнеров тоже самое: арт-директор по-прежнему нужен, но проходной говнобуклет для ООО "Ромашка" проще сгенерить. Раньше для этого использовали начинающих фрилансеров.
В общем, если когда-то про замену профессий ИИ - это были лишь рассуждения, то теперь это статистика. Как будут обучаться новые кадры, если тенденция продолжится, я не понимаю.
⠀
Please open Telegram to view this post
VIEW IN TELEGRAM
🤔7😢5❤2😁1
Если раньше у ИИ были галлюцинации, то теперь еще и раздвоение личности
https://habr.com/ru/companies/bothub/news/870510/
TLDR: некоторые модели возможно обучаются на текстах, сгенерированных chatGPT, поэтому результат получается с закидонами
https://habr.com/ru/companies/bothub/news/870510/
TLDR: некоторые модели возможно обучаются на текстах, сгенерированных chatGPT, поэтому результат получается с закидонами
Хабр
Почему новая модель AI от DeepSeek считает себя ChatGPT
На этой неделе DeepSeek, хорошо финансируемая китайская лаборатория AI, выпустила «открытую» модель AI, которая превосходит многих конкурентов по популярным показателям. Модель DeepSeek V3 крупная, но...
👍3
Количество новых вопросов в месяц на StackOverflow сократилось в три с лишним раза с момента появления ChatGPT
Даже не знаю, хорошо это или плохо )
https://gist.github.com/hopeseekr/f522e380e35745bd5bdc3269a9f0b132
Даже не знаю, хорошо это или плохо )
https://gist.github.com/hopeseekr/f522e380e35745bd5bdc3269a9f0b132
😁16🤔8❤2
В одном подкасте слышал такое мнение, что мол любой http-эндпоинт - это лишь функция, которая условно принимает на вход заголовки и json, а выдаёт другие заголовки и json. Поэтому функциональное программирование (речь была про Clojure) максимально подходит для таких задач.
А я вот не понимаю, почему все так молятся на функциональное программирование и чистые функции.
Блин, http-запрос обычно еще порождает запись в базу. А иногда несколько чтений и записей в базу/редис/кафку, там чистыми функциями и не пахло. Например, перевод денег с одного счета на другой с проверкой на наличие средств. Полно побочных эффектов. Да, я знаю про монады и прочие обёртки для эффектов, но по факту это то же самое, что и обычный императивный код, только сложнее читать.
Говорят, что ФП удобнее тестировать, но в чём удобство? Побочные эффекты тестировать также сложно. Можно конечно вынести какую-то логику в отдельные чистые функции и тестировать их без моков. Но основная сложность всё равно в правильной последовательности операций с базой (с учетом параллельных запросов), а это никуда не денется. В итоге тестировать придётся также с моками, только код станет сложнее из-за попыток отделить чистое от нечистого.
А еще много раз видел, даже без Кложи, как вместо одного тупого цикла с двумя понятными ифами строят целый пайплайн из map и прочих функций
А я вот не понимаю, почему все так молятся на функциональное программирование и чистые функции.
Блин, http-запрос обычно еще порождает запись в базу. А иногда несколько чтений и записей в базу/редис/кафку, там чистыми функциями и не пахло. Например, перевод денег с одного счета на другой с проверкой на наличие средств. Полно побочных эффектов. Да, я знаю про монады и прочие обёртки для эффектов, но по факту это то же самое, что и обычный императивный код, только сложнее читать.
Говорят, что ФП удобнее тестировать, но в чём удобство? Побочные эффекты тестировать также сложно. Можно конечно вынести какую-то логику в отдельные чистые функции и тестировать их без моков. Но основная сложность всё равно в правильной последовательности операций с базой (с учетом параллельных запросов), а это никуда не денется. В итоге тестировать придётся также с моками, только код станет сложнее из-за попыток отделить чистое от нечистого.
А еще много раз видел, даже без Кложи, как вместо одного тупого цикла с двумя понятными ифами строят целый пайплайн из map и прочих функций
// Допустим, у нас есть массив заказов и надо посчитать сумму всех
// валидных заказов со скидкой больше 20%
// Императивный подход - простой и понятный:
function calculateTotalSimple(orders: Order[]): number {
let total = 0;
for (const order of orders) {
if (order.status === 'valid' && order.discount > 20) {
total += order.amount;
}
}
return total;
}
// "Функциональный" подход - попытка сделать "красиво":
const calculateTotal = (orders: Order[]): number =>
orders
.filter(order => order.status === 'valid')
.filter(({discount}) => discount > 20)
.map(({amount}) => amount)
.reduce((acc, amount) => acc + amount, 0);
// Или еще "круче":
const isValid = (order: Order): boolean => order.status === 'valid';
const hasHighDiscount = (order: Order): boolean => order.discount > 20;
const getAmount = (order: Order): number => order.amount;
const sum = (a: number, b: number): number => a + b;
const calculateTotalFP = (orders: Order[]): number =>
pipe(
orders,
filter(isValid),
filter(hasHighDiscount),
map(getAmount),
reduce(sum, 0)
);
👍36👎6💊5❤2🔥1
🌐 HTTP QUERY: новый метод для поисковых запросов
В мире HTTP давно существует проблема с передачей сложных поисковых запросов. Когда разработчику нужно передать большой набор параметров для поиска или фильтрации, у него есть два не самых удачных варианта.
Можно использовать GET и передавать всё в URL:
Но URL дефакто имеет ограничения по длине, а кодирование сложных параметров становится громоздким.
Второй вариант — использовать POST и передавать параметры в теле запроса. Однако POST не предназначен для таких операций: он не кэшируется и не является идемпотентным, что усложняет работу с CDN и повторную отправку запросов.
Именно поэтому появился новый метод QUERY. Он позволяет отправлять поисковые параметры в теле запроса:
При этом QUERY сохраняет все преимущества GET: он безопасный, идемпотентный и кэшируемый. Cочетает поддержку тела запроса с возможностью кэширования.
Метод официально получил статус PROPOSED STANDARD, что означает скорое появление поддержки в браузерах и веб-фреймворках.
RFC: https://datatracker.ietf.org/doc/draft-ietf-httpbis-safe-method-w-body/
В мире HTTP давно существует проблема с передачей сложных поисковых запросов. Когда разработчику нужно передать большой набор параметров для поиска или фильтрации, у него есть два не самых удачных варианта.
Можно использовать GET и передавать всё в URL:
GET /feed?q=foo&limit=10&sort=-published&filters[]=status:active&filters[]=type:post
Но URL дефакто имеет ограничения по длине, а кодирование сложных параметров становится громоздким.
Второй вариант — использовать POST и передавать параметры в теле запроса. Однако POST не предназначен для таких операций: он не кэшируется и не является идемпотентным, что усложняет работу с CDN и повторную отправку запросов.
Именно поэтому появился новый метод QUERY. Он позволяет отправлять поисковые параметры в теле запроса:
QUERY /feed
Content-Type: application/json
{
"q": "foo",
"limit": 10,
"sort": "-published",
"filters": ["status:active", "type:post"]
}
При этом QUERY сохраняет все преимущества GET: он безопасный, идемпотентный и кэшируемый. Cочетает поддержку тела запроса с возможностью кэширования.
Метод официально получил статус PROPOSED STANDARD, что означает скорое появление поддержки в браузерах и веб-фреймворках.
RFC: https://datatracker.ietf.org/doc/draft-ietf-httpbis-safe-method-w-body/
3👍64🔥19🤩4
В опросе JetBrains за 2024 год видно, что Go теперь используется бОльшим количеством людей, чем PHP!
Вопрос был "Which programming languages have you used in the last 12 months?"
Кроме того, Go и Rust - языки, которые у людей в планах на изучение. 10% и 11% соответственно. Для сравнения, Python только 6%.
Я думал, что Go уже устаканился и занял свою нишу, но нет, он прёт как на дрожжах
Вопрос был "Which programming languages have you used in the last 12 months?"
Кроме того, Go и Rust - языки, которые у людей в планах на изучение. 10% и 11% соответственно. Для сравнения, Python только 6%.
Я думал, что Go уже устаканился и занял свою нишу, но нет, он прёт как на дрожжах
👍27💩3👎1🤬1
Написал на Хабр статью "Перестаньте молиться на принципы S.O.L.I.D"
https://habr.com/ru/articles/874584/
🫥 Cross Join
https://habr.com/ru/articles/874584/
Please open Telegram to view this post
VIEW IN TELEGRAM
Хабр
Перестаньте молиться на принципы S.O.L.I.D
В мире разработки программного обеспечения существует множество "священных коров" — принципов и практик, которые принимаются как данность и редко подвергаются критическому анализу. Особенно...
3🔥41👍16🥴5🫡3❤2
В Go очень интересно устроен стек. Я раньше не особо интересовался деталями реализации, лишь знал, что стек динамически растёт при необходимости, и можно относительно спокойно использовать рекурсию. На практике это пофиг обычно, как именно всё работает, но тут че-то решил загуглить, стало интересно.
Ведь Go компилируется в машинный код (не байт-код), а процессор при исполнении кода умеет только тупо выполнять инструкции по порядку - он не знает про горутины, и что у них надо что-то там увеличивать. Как это всё работает?
Короче.
Если у нормальных потоков ОС стек - это отдельный сегмент памяти фиксированного размера, то в Go стек горутин лежит в куче.
При создании горутины под стек выделяется 2кб, а потом растет по мере необходимости.
Как я уже говорил, процессор ничего не знает про горутины и псевдостеки, он тупо отрабатывает одну инструкцию за другой, а на стек у него стандартно указывает регистр SP (stack pointer)
Поэтому в скомпилированный код перед каждым вызовом любой функции компилятор Go вставляет проверку, а хватит ли в горутиновом стеке места для вызова этой функции. Если нет, то в куче выделяется новое место в 2 раза больше, копируется всё, обновляются указатели, обновляется регистр проца, указывающий на стек. Макс размер стека - 1Гб.
Ну и при переключении горутин, помимо прочего контекста, переключается и SP.
Сама проверка очень легковесная, практически простое сравнение пары чисел. А вот расширение стека, конечно, намного дороже.
Стек умеет не только расти, но и сжиматься. Если горутина перестаёт использовать большую часть своего стека, то при следующем garbage collection стек может быть "обрезан" до меньшего размера, чтобы освободить память.
В итоге:
Переключение между горутинами происходит быстро (выставляются сохраненные регистры, включая SP и указатель на следующую выполняемую инструкцию + еще пару вещей)
Сложно столкнуться с переполнением (stack overflow).
Горутины экономно жрут память, поэтому их можно делать фиговы тыщи.
🫥 Cross Join
⠀
Ведь Go компилируется в машинный код (не байт-код), а процессор при исполнении кода умеет только тупо выполнять инструкции по порядку - он не знает про горутины, и что у них надо что-то там увеличивать. Как это всё работает?
Короче.
Если у нормальных потоков ОС стек - это отдельный сегмент памяти фиксированного размера, то в Go стек горутин лежит в куче.
При создании горутины под стек выделяется 2кб, а потом растет по мере необходимости.
Как я уже говорил, процессор ничего не знает про горутины и псевдостеки, он тупо отрабатывает одну инструкцию за другой, а на стек у него стандартно указывает регистр SP (stack pointer)
Поэтому в скомпилированный код перед каждым вызовом любой функции компилятор Go вставляет проверку, а хватит ли в горутиновом стеке места для вызова этой функции. Если нет, то в куче выделяется новое место в 2 раза больше, копируется всё, обновляются указатели, обновляется регистр проца, указывающий на стек. Макс размер стека - 1Гб.
Ну и при переключении горутин, помимо прочего контекста, переключается и SP.
Сама проверка очень легковесная, практически простое сравнение пары чисел. А вот расширение стека, конечно, намного дороже.
Стек умеет не только расти, но и сжиматься. Если горутина перестаёт использовать большую часть своего стека, то при следующем garbage collection стек может быть "обрезан" до меньшего размера, чтобы освободить память.
В итоге:
Переключение между горутинами происходит быстро (выставляются сохраненные регистры, включая SP и указатель на следующую выполняемую инструкцию + еще пару вещей)
Сложно столкнуться с переполнением (stack overflow).
Горутины экономно жрут память, поэтому их можно делать фиговы тыщи.
⠀
Please open Telegram to view this post
VIEW IN TELEGRAM
👍48❤2
Наткнулся на статью, которая уверяла, что AI пишет лучше людей, и что достаточно вбить такой промпт, чтобы сделать любой текст вирусным:
"Перепиши этот текст так, чтобы его мог легко понять 15-летний подросток, у которого клиповое мышление и низкий уровень внимания.Используй короткие предложения, мемные аналогии и текстовые приёмы, которые используют топовые блогеры в TikTok и Instagram.Добавь интригу в каждом абзаце, чтобы читатель не ушёл после первых трёх строк. "
В общем, я попробовал так переработать пост про стэк Go, получилось примерно следующее (надеюсь, станет вирусным!):
🔥 ЙОУ! Сейчас расскажу, как Go разрулил тему со стеком, и это просто ОГОНЬ!
😱 ШОКИРУЮЩИЙ ФАКТ: В Go стек работает совсем не так, как ты думаешь!
🧠 Представь, что стек - это твой рюкзак для книг. В обычных языках этот рюкзак фиксированного размера (прям как в школе). Но Go - другое!
🎒 В Go твой рюкзак может МАГИЧЕСКИ увеличиваться, когда нужно больше места! Начинается с малюсеньких 2кб (считай, один учебник), но может вырасти до 1ГБ (целая библиотека!)
🤯 САМОЕ БЕЗУМНОЕ: Процессор вообще не догоняет, что происходит! Он как учитель, который просто следует инструкциям. Но Go такой умный, что перед каждым новым действием проверяет: "Йо, хватит места?"
💡 Если места мало - БАМ! 💥 Go создает новый рюкзак в два раза больше, перекладывает все вещи и продолжает работу. ИМБА!
🔄 А еще Go может УМЕНЬШАТЬ рюкзак, если ты перестал использовать много места. Экономия на максималках!
🏆 В итоге что получаем:
- Работает БЫСТРО как Флэш ⚡
- Памяти жрет как птичка 🐦
- Можно создавать ТОННУ параллельных процессов 🚀
#go #программирование #айтишники #этовамнешутки
P.S. Лайк и подписка, если хочешь больше таких объяснений! 😉
🫥 Cross Join
⠀
"Перепиши этот текст так, чтобы его мог легко понять 15-летний подросток, у которого клиповое мышление и низкий уровень внимания.Используй короткие предложения, мемные аналогии и текстовые приёмы, которые используют топовые блогеры в TikTok и Instagram.Добавь интригу в каждом абзаце, чтобы читатель не ушёл после первых трёх строк. "
В общем, я попробовал так переработать пост про стэк Go, получилось примерно следующее (надеюсь, станет вирусным!):
🔥 ЙОУ! Сейчас расскажу, как Go разрулил тему со стеком, и это просто ОГОНЬ!
😱 ШОКИРУЮЩИЙ ФАКТ: В Go стек работает совсем не так, как ты думаешь!
🧠 Представь, что стек - это твой рюкзак для книг. В обычных языках этот рюкзак фиксированного размера (прям как в школе). Но Go - другое!
🎒 В Go твой рюкзак может МАГИЧЕСКИ увеличиваться, когда нужно больше места! Начинается с малюсеньких 2кб (считай, один учебник), но может вырасти до 1ГБ (целая библиотека!)
🤯 САМОЕ БЕЗУМНОЕ: Процессор вообще не догоняет, что происходит! Он как учитель, который просто следует инструкциям. Но Go такой умный, что перед каждым новым действием проверяет: "Йо, хватит места?"
💡 Если места мало - БАМ! 💥 Go создает новый рюкзак в два раза больше, перекладывает все вещи и продолжает работу. ИМБА!
🔄 А еще Go может УМЕНЬШАТЬ рюкзак, если ты перестал использовать много места. Экономия на максималках!
🏆 В итоге что получаем:
- Работает БЫСТРО как Флэш ⚡
- Памяти жрет как птичка 🐦
- Можно создавать ТОННУ параллельных процессов 🚀
#go #программирование #айтишники #этовамнешутки
P.S. Лайк и подписка, если хочешь больше таких объяснений! 😉
⠀
Please open Telegram to view this post
VIEW IN TELEGRAM
Telegram
Cross Join - канал о разработке
Канал о разработке Антона Околелова. Тимлид Go, живу в Чехии. Мысли, новости, вопросы.
По вопросам рекламы @antonokolelov
По вопросам рекламы @antonokolelov
😁83🥴29👎6🙈6👍5🔥3❤2🤮2😭2🥰1
Как вы знаете, китайская LLM deepseek-R1 работает не хуже chatGPT-o1, но стоит в 20 раз дешевле. А знаете ли вы, что сама модель вообще халявная, её можно скачать себе и запустить на своём железе?
Мне стало интересно, как это делать, можно ли как-то запустить прямо на макбуке, и оказалось, что это делается буквально в два клика (конечно, полная модель на ноут не влезет, но дистиллированная - вполне).
Возможно, все уже это умеют, но я же обещал рубрику #слоупок, так что держите инструкцию
Для этого надо установить ollama, например так:
и запустить
Запустить можно в отдельном окошке, чтобы смотреть логи, или в бекграунд убрать, пофиг. В общем, это некий сервис.
Дальше скачать и запустить модель. Это делается тупо одной командой.
8b - это количество параметров (8 миллиардов). Другие варианты:
1.5b
7b
8b
14b
32b
70b
671b
Но понятно, что 671b на макбук не влезет. Зато 1.5 можно и на мобилу запихнуть.
При запуске этой команды скачивается примерно 5 гигов чего-то и собственно вы уже можете общаться с моделью прямо в олламе.
Но это не очень юзер-френдли, поэтому дополнительно можно запусть web-интерфейс, например в докере одной командой
После чего на http://localhost:3000/ видна морда, похожая на chatgpt.
Прикол китайской модели еще в том, что там показан процесс думания. Его можно посмотреть прямо в этом веб интерфейсе.
Понятно, что это скорее побаловаться - на ноуте влезает только дистиллированная модель и то нещадно тормозит (макбук M1 pro). Для полноценной работы нужно нормальное железо или облако.
P.S.
Это имхо очень круто: если вложиться в железо, можно очень быстро и просто поднять у себя самый топовый чат и не посылать больше свои секреты ни в OpenAI, ни в Китай.
🫥 Cross Join
⠀
Мне стало интересно, как это делать, можно ли как-то запустить прямо на макбуке, и оказалось, что это делается буквально в два клика (конечно, полная модель на ноут не влезет, но дистиллированная - вполне).
Возможно, все уже это умеют, но я же обещал рубрику #слоупок, так что держите инструкцию
Для этого надо установить ollama, например так:
brew install ollama
и запустить
ollama serve
Запустить можно в отдельном окошке, чтобы смотреть логи, или в бекграунд убрать, пофиг. В общем, это некий сервис.
Дальше скачать и запустить модель. Это делается тупо одной командой.
ollama run deepseek-r1:8b
8b - это количество параметров (8 миллиардов). Другие варианты:
1.5b
7b
8b
14b
32b
70b
671b
Но понятно, что 671b на макбук не влезет. Зато 1.5 можно и на мобилу запихнуть.
При запуске этой команды скачивается примерно 5 гигов чего-то и собственно вы уже можете общаться с моделью прямо в олламе.
Но это не очень юзер-френдли, поэтому дополнительно можно запусть web-интерфейс, например в докере одной командой
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
После чего на http://localhost:3000/ видна морда, похожая на chatgpt.
Прикол китайской модели еще в том, что там показан процесс думания. Его можно посмотреть прямо в этом веб интерфейсе.
Понятно, что это скорее побаловаться - на ноуте влезает только дистиллированная модель и то нещадно тормозит (макбук M1 pro). Для полноценной работы нужно нормальное железо или облако.
P.S.
Это имхо очень круто: если вложиться в железо, можно очень быстро и просто поднять у себя самый топовый чат и не посылать больше свои секреты ни в OpenAI, ни в Китай.
⠀
Please open Telegram to view this post
VIEW IN TELEGRAM
1🔥44👍15❤3
Тут такое дело, говорят, что deepseek уже устарел, появилась новая модель от Alibaba Qwen2.5-Max, которая бьёт всех.
Попробовать можно тут: https://chat.qwenlm.ai/
Блог пост от авторов тут: https://qwenlm.github.io/blog/qwen2.5-max/
Кто-нибудь знает детали?
🫥 Cross Join
⠀
Попробовать можно тут: https://chat.qwenlm.ai/
Блог пост от авторов тут: https://qwenlm.github.io/blog/qwen2.5-max/
Кто-нибудь знает детали?
⠀
Please open Telegram to view this post
VIEW IN TELEGRAM
2😁30🔥6👎1
Proposal sync/v2 в Go
После того как пакет math/rand/v2 показал себя с лучшей стороны, команда Go решила двигаться дальше и взяться за обновление ещё одного важного компонента стандартной библиотеки — пакета sync. Ян Лэнс Тейлор предложил создать sync/v2, который должен сделать работу с конкурентностью в Go более удобной благодаря использованию дженериков. При этом команда старается сохранить простоту и высокую производительность.
Что нового предлагается
sync.Map с дженериками
Самые заметные изменения ждут
Это избавит от утомительных проверок типов при получении значений из sync.Map — код станет и читабельнее, и безопаснее, и эффективнее. Вместо старого метода
Одно из доп. улучшений — замена публичного метода
Как жить с двумя версиями
Многих беспокоит, как поддерживать код, где придётся использовать и v1, и v2. Но ситуация не так плоха: типы из пакета sync обычно используются во внутренней реализации, а не в публичных API. Это значит, что переход на новую версию должен быть проще, чем, например, с пакетом net/http.
Хотя некоторые сомневаются, нужны ли вообще пакеты v2, статистика использования math/rand/v2 обнадёживает. Пакету нет ещё и года, а его уже импортируют более 2500 других пакетов. Как отмечает Ян Лэнс Тейлор, это хороший показатель, даже если он пока меркнет на фоне оригинального math/rand.
🫥 Cross Join
После того как пакет math/rand/v2 показал себя с лучшей стороны, команда Go решила двигаться дальше и взяться за обновление ещё одного важного компонента стандартной библиотеки — пакета sync. Ян Лэнс Тейлор предложил создать sync/v2, который должен сделать работу с конкурентностью в Go более удобной благодаря использованию дженериков. При этом команда старается сохранить простоту и высокую производительность.
Что нового предлагается
sync.Map с дженериками
Самые заметные изменения ждут
sync.Map. Теперь она будет поддерживать обобщённые типы:
type Map[K comparable, V any] struct { ... }
Это избавит от утомительных проверок типов при получении значений из sync.Map — код станет и читабельнее, и безопаснее, и эффективнее. Вместо старого метода
Range появится новый метод All(), который будет возвращать итератор. Это должно сделать перебор элементов карты более удобным.sync.Pool тоже получит поддержку дженериков:
type Pool[T any] struct { ... }
Одно из доп. улучшений — замена публичного метода
New на функцию-конструктор NewPool. Это должно решить распространённую проблему, когда разработчики случайно вызывают New напрямую вместо метода Get. Новый дизайн также обещает лучше работать с типами вроде []byte — должно быть меньше ненужных аллокаций памяти.Как жить с двумя версиями
Многих беспокоит, как поддерживать код, где придётся использовать и v1, и v2. Но ситуация не так плоха: типы из пакета sync обычно используются во внутренней реализации, а не в публичных API. Это значит, что переход на новую версию должен быть проще, чем, например, с пакетом net/http.
Хотя некоторые сомневаются, нужны ли вообще пакеты v2, статистика использования math/rand/v2 обнадёживает. Пакету нет ещё и года, а его уже импортируют более 2500 других пакетов. Как отмечает Ян Лэнс Тейлор, это хороший показатель, даже если он пока меркнет на фоне оригинального math/rand.
Please open Telegram to view this post
VIEW IN TELEGRAM
GitHub
proposal: sync/v2: new package · Issue #71076 · golang/go
Proposal Details The math/rand/v2 package has been successful. Let's consider another v2 package: sync/v2. This is an update of #47657. Background The current sync package provides Map and Pool...
👍17
Кто-нибудь понимает в нейминге моделей chatGPT?
Почему нельзя было их называть v1, v2, v3? Почему новые модели щас назвали o3-mini и o3-mini-high, блин?
Ну что за дичь?
gpt-3.5
gpt-4
o1-mini
o1-preview
gpt4o
gpt4o-mini
o3-mini
o3-mini-high чтоб я сдох
это звучит как "большой-мелкий озон"
Я совсем потерялся
🫥 Cross Join
Почему нельзя было их называть v1, v2, v3? Почему новые модели щас назвали o3-mini и o3-mini-high, блин?
Ну что за дичь?
gpt-3.5
gpt-4
o1-mini
o1-preview
gpt4o
gpt4o-mini
o3-mini
o3-mini-high чтоб я сдох
это звучит как "большой-мелкий озон"
Я совсем потерялся
Please open Telegram to view this post
VIEW IN TELEGRAM
Telegram
Cross Join - канал о разработке
Канал о разработке Антона Околелова. Тимлид Go, живу в Чехии. Мысли, новости, вопросы.
По вопросам рекламы @antonokolelov
По вопросам рекламы @antonokolelov
💯39😁12❤1
Решил тут разобраться, как работает RSA-шифрование, и как квантовые компьютеры его ломают. Я не настоящий сварщик, так что если допустил неточность, поправьте.
По сути всё делается примерно так:
1) Выбираются два больших простых числа, назовём их p и q.
2) Вычисляется их произведение n = p * q. Это n является частью открытого ключа.
3) Вычисляется φ(n) = (p-1) × (q-1)
4) Выбирается некое число e (т.н. "экспонента"), которое не имеет общих делителей с φ(n) (наибольший общий делитель = 1).
e тоже является частью открытого ключа
5) вычисляется секретная экспонента d, такая, чтобы остаток от деления (e*d) на φ(n) был 1
Таким образом, мы имеем ключи:
открытый ключ - числа n и e
закрытый ключ - числа n и d
Шифрование
Для шифрования сообщение сначала преобразуется в число (например, путем конвертации текста в байты), назовём его m. Важный момент: число m должно быть меньше n. Если сообщение получается больше n, его разбивают на блоки подходящего размера и шифруют каждый блок отдельно.
Шифрованное сообщение будет
с = m^e mod n
Расшифровка
Расшифровать с можно так:
m = c^d mod n
В реальных системах используются простые числа размером в тысячи бит, что даёт огромное значение n и позволяет шифровать большие блоки данных. Например, при длине ключа 2048 бит (это стандартный размер для RSA сегодня), n будет числом примерно из 617 десятичных цифр.
Вот простой пример на Go, демонстрирующий работу RSA (числа взяты маленькие для наглядности, в реальности они должны быть намного больше):
Безопасность RSA основана на сложности факторизации (разложения на множители) больших чисел. Зная только открытый ключ (n,e), практически невозможно вычислить закрытый ключ d без знания p и q.
Прикол в том, что квантовые компьютеры способны эффективно раскладывать числа на множители с помощью алгоритма Шора. Получив p и q, можно легко вычислить φ(n) и все остальные компоненты для взлома шифра.
🫥 Cross Join
⠀
По сути всё делается примерно так:
1) Выбираются два больших простых числа, назовём их p и q.
2) Вычисляется их произведение n = p * q. Это n является частью открытого ключа.
3) Вычисляется φ(n) = (p-1) × (q-1)
4) Выбирается некое число e (т.н. "экспонента"), которое не имеет общих делителей с φ(n) (наибольший общий делитель = 1).
e тоже является частью открытого ключа
5) вычисляется секретная экспонента d, такая, чтобы остаток от деления (e*d) на φ(n) был 1
Таким образом, мы имеем ключи:
открытый ключ - числа n и e
закрытый ключ - числа n и d
Шифрование
Для шифрования сообщение сначала преобразуется в число (например, путем конвертации текста в байты), назовём его m. Важный момент: число m должно быть меньше n. Если сообщение получается больше n, его разбивают на блоки подходящего размера и шифруют каждый блок отдельно.
Шифрованное сообщение будет
с = m^e mod n
Расшифровка
Расшифровать с можно так:
m = c^d mod n
В реальных системах используются простые числа размером в тысячи бит, что даёт огромное значение n и позволяет шифровать большие блоки данных. Например, при длине ключа 2048 бит (это стандартный размер для RSA сегодня), n будет числом примерно из 617 десятичных цифр.
Вот простой пример на Go, демонстрирующий работу RSA (числа взяты маленькие для наглядности, в реальности они должны быть намного больше):
package main
import (
"fmt"
"math/big"
)
func main() {
// В реальности числа должны быть намного больше
p := big.NewInt(61)
q := big.NewInt(53)
// Вычисляем n = p * q
n := new(big.Int).Mul(p, q)
// Вычисляем φ(n) = (p-1) * (q-1)
p1 := new(big.Int).Sub(p, big.NewInt(1))
q1 := new(big.Int).Sub(q, big.NewInt(1))
phi := new(big.Int).Mul(p1, q1)
// Выбираем e (взаимно простое с φ(n))
e := big.NewInt(17)
// Находим d (мультипликативное обратное к e по модулю φ(n))
d := new(big.Int)
d.ModInverse(e, phi)
fmt.Printf("Открытый ключ (n=%v, e=%v)\n", n, e)
fmt.Printf("Закрытый ключ (n=%v, d=%v)\n", n, d)
// Пример шифрования сообщения
message := big.NewInt(129)
// Проверяем, что сообщение меньше модуля
if message.Cmp(n) >= 0 {
fmt.Printf("\nОшибка: сообщение %v больше или равно модулю %v\n", message, n)
fmt.Printf("В этом примере сообщение должно быть меньше %v\n", n)
return
}
fmt.Printf("\nИсходное сообщение: %v\n", message)
// Шифруем: c = m^e mod n
encrypted := new(big.Int).Exp(message, e, n)
fmt.Printf("Зашифрованное сообщение: %v\n", encrypted)
// Расшифровываем: m = c^d mod n
decrypted := new(big.Int).Exp(encrypted, d, n)
fmt.Printf("Расшифрованное сообщение: %v\n", decrypted)
}
Безопасность RSA основана на сложности факторизации (разложения на множители) больших чисел. Зная только открытый ключ (n,e), практически невозможно вычислить закрытый ключ d без знания p и q.
Прикол в том, что квантовые компьютеры способны эффективно раскладывать числа на множители с помощью алгоритма Шора. Получив p и q, можно легко вычислить φ(n) и все остальные компоненты для взлома шифра.
⠀
Please open Telegram to view this post
VIEW IN TELEGRAM
1👍25🔥5🤩4💯2❤1
Вышел Go 1.24 (интерактивные примеры тут)
Производительность
Снижение нагрузки на CPU на 2-3% благодаря:
- Новой реализации встроенных map на основе Swiss Tables
- Более эффективному выделению памяти для малых объектов
- Новой внутренней реализации mutex в runtime
Обобщенные псевдонимы типов
Теперь можно создавать параметризованные псевдонимы типов, например:
Слабые указатели
Добавлен новый пакет weak, который предоставляет weak pointers – указатели, которые не препятствуют сборке мусора. Это полезно для реализации кэшей и других структур данных, где нужно избежать утечек памяти.
Улучшенные финализаторы
Представлена новая функция runtime.AddCleanup, которая является более гибкой и эффективной альтернативой runtime.SetFinalizer. Она позволяет:
- Прикреплять несколько функций очистки к одному объекту
- Работать с внутренними указателями
- Избегать утечек памяти при циклических ссылках
Ограниченный доступ к файловой системе
Новый тип os.Root позволяет ограничить файловые операции определенной директорией, что полезно для безопасной работы с файлами.
Улучшения для тестирования
Добавлен метод testing.B.Loop, который предоставляет более простой и надежный способ написания бенчмарков:
Новый пакет testing/synctest позволяет тестировать код с временными операциями, используя синтетические часы вместо реального времени.
Зависимости инструментов
Теперь модули Go могут отслеживать зависимости исполняемых файлов с помощью директив tool в go.mod.
Чтобы добавить зависимость инструмента, используйте go get -tool:
Это добавляет зависимость tool с директивой require в go.mod:
Теперь команда go tool может запускать эти инструменты в дополнение к инструментам, поставляемым с дистрибутивом Go:
Криптография
Добавлены новые криптографические пакеты:
crypto/sha3 - реализация SHA-3
crypto/hkdf - реализация HKDF
crypto/pbkdf2 - реализация PBKDF2
Работа с JSON
Добавлена новая опция omitzero для тегов структур, которая позволяет пропускать нулевые значения при сериализации в JSON. В отличие от omitempty, она работает корректно с time.Time и другими типами, имеющими метод IsZero().
Инструментарий
Go модули теперь могут отслеживать зависимости от исполняемых файлов с помощью директив tool в go.mod. Команды go build, go install и go test получили флаг -json для вывода результатов в формате JSON.
🫥 Cross Join
⠀
Производительность
Снижение нагрузки на CPU на 2-3% благодаря:
- Новой реализации встроенных map на основе Swiss Tables
- Более эффективному выделению памяти для малых объектов
- Новой внутренней реализации mutex в runtime
Обобщенные псевдонимы типов
Теперь можно создавать параметризованные псевдонимы типов, например:
type Set[T comparable] = map[T]bool
Слабые указатели
Добавлен новый пакет weak, который предоставляет weak pointers – указатели, которые не препятствуют сборке мусора. Это полезно для реализации кэшей и других структур данных, где нужно избежать утечек памяти.
Улучшенные финализаторы
Представлена новая функция runtime.AddCleanup, которая является более гибкой и эффективной альтернативой runtime.SetFinalizer. Она позволяет:
- Прикреплять несколько функций очистки к одному объекту
- Работать с внутренними указателями
- Избегать утечек памяти при циклических ссылках
Ограниченный доступ к файловой системе
Новый тип os.Root позволяет ограничить файловые операции определенной директорией, что полезно для безопасной работы с файлами.
// Пример использования os.Root
root, err := os.OpenRoot("/path/to/dir")
if err != nil {
log.Fatal(err)
}
// Операции ограничены директорией
f, err := root.Open("file.txt")
if err != nil {
log.Fatal(err)
}
Улучшения для тестирования
Добавлен метод testing.B.Loop, который предоставляет более простой и надежный способ написания бенчмарков:
func BenchmarkMyFunc(b *testing.B) {
// Вместо for i := 0; i < b.N; i++
for b.Loop() {
// код бенчмарка
}
}
Новый пакет testing/synctest позволяет тестировать код с временными операциями, используя синтетические часы вместо реального времени.
Зависимости инструментов
Теперь модули Go могут отслеживать зависимости исполняемых файлов с помощью директив tool в go.mod.
Чтобы добавить зависимость инструмента, используйте go get -tool:
go get -tool golang.org/x/tools/cmd/stringer
Это добавляет зависимость tool с директивой require в go.mod:
module mymod
go 1.24
tool golang.org/x/tools/cmd/stringer
require (
golang.org/x/mod v0.22.0 // indirect
golang.org/x/sync v0.10.0 // indirect
golang.org/x/tools v0.29.0 // indirect
)
Теперь команда go tool может запускать эти инструменты в дополнение к инструментам, поставляемым с дистрибутивом Go:
go tool stringer
Криптография
Добавлены новые криптографические пакеты:
crypto/sha3 - реализация SHA-3
crypto/hkdf - реализация HKDF
crypto/pbkdf2 - реализация PBKDF2
Работа с JSON
Добавлена новая опция omitzero для тегов структур, которая позволяет пропускать нулевые значения при сериализации в JSON. В отличие от omitempty, она работает корректно с time.Time и другими типами, имеющими метод IsZero().
Инструментарий
Go модули теперь могут отслеживать зависимости от исполняемых файлов с помощью директив tool в go.mod. Команды go build, go install и go test получили флаг -json для вывода результатов в формате JSON.
⠀
Please open Telegram to view this post
VIEW IN TELEGRAM
1👍32❤1
Если вы еще не пробовали Cursor AI, то советую потыкать (у них есть бесплатная триалка)
Я попробовал поковырять на нём тестовую папочку с фронтендом, чтобы изучить возможности. Работает очень круто. Еще вчера мне казалось, что это хайповое говно, но, попробовав, я теперь уверен, что за этим будущее. И IDE, которые не будут поддерживать такой режим, просто уйдут с рынка.
Это не просто автокомплит (github copliot) или отдельный чат (пусть даже с программерскими штучками как в claude). Здесь ты можешь сказать: вот в этих файлах надо переделать (режим "composer" с выбором файлов), допустим, в форму добавить поле, и оно должно валидироваться так-то, на сервер уходить так-то.
И оно само всё делает сразу в нескольких файлах, выдает тебе результат на код ревью. Там же можно подсказать, чтобы по-другому сделал, упростил и т.д.. Потом жмёшь apply и всё, собственно - вы великолепны.
Понятно, что это та же невросеть, поэтому возможны неточности и глюки. На практике, если код пошел совсем не туда, получается быстрее всё снести и попросить заново сделать в чистом чате. Но это редко, чаще всего с первого раза получается примерно то, что нужно, плюс небольшие "доработки" словами.
Еще можно поговорить со всем кодом проекта сразу, спросить, где у меня, допустим, кнопка красная была, не могу найти. Можно прямо в весь проект сказать, без указания файлов, "поправь то-то и то-то". Но почему-то когда указываешь конкретные файлы в режиме composer, работает намного лучше. Наверное это стандартный косяк LLM - с большим контекстом они все работают плохо, даже если он у них формально и влезает.
В общем, ждём, когда jetbrains такое сделает, потому что cursor сделан на основе vscode, а я его не очень люблю (чисто эстетически).
И хотелось бы голосовой интерфейс (сам не верю, что это пишу, но было бы полезно).
Ну и да - попрежнему о замене программистов и речи не идёт, ибо нужно четко понимать, что ты делаешь.
🫥 Cross Join
⠀
Я попробовал поковырять на нём тестовую папочку с фронтендом, чтобы изучить возможности. Работает очень круто. Еще вчера мне казалось, что это хайповое говно, но, попробовав, я теперь уверен, что за этим будущее. И IDE, которые не будут поддерживать такой режим, просто уйдут с рынка.
Это не просто автокомплит (github copliot) или отдельный чат (пусть даже с программерскими штучками как в claude). Здесь ты можешь сказать: вот в этих файлах надо переделать (режим "composer" с выбором файлов), допустим, в форму добавить поле, и оно должно валидироваться так-то, на сервер уходить так-то.
И оно само всё делает сразу в нескольких файлах, выдает тебе результат на код ревью. Там же можно подсказать, чтобы по-другому сделал, упростил и т.д.. Потом жмёшь apply и всё, собственно - вы великолепны.
Понятно, что это та же невросеть, поэтому возможны неточности и глюки. На практике, если код пошел совсем не туда, получается быстрее всё снести и попросить заново сделать в чистом чате. Но это редко, чаще всего с первого раза получается примерно то, что нужно, плюс небольшие "доработки" словами.
Еще можно поговорить со всем кодом проекта сразу, спросить, где у меня, допустим, кнопка красная была, не могу найти. Можно прямо в весь проект сказать, без указания файлов, "поправь то-то и то-то". Но почему-то когда указываешь конкретные файлы в режиме composer, работает намного лучше. Наверное это стандартный косяк LLM - с большим контекстом они все работают плохо, даже если он у них формально и влезает.
В общем, ждём, когда jetbrains такое сделает, потому что cursor сделан на основе vscode, а я его не очень люблю (чисто эстетически).
И хотелось бы голосовой интерфейс (сам не верю, что это пишу, но было бы полезно).
Ну и да - попрежнему о замене программистов и речи не идёт, ибо нужно четко понимать, что ты делаешь.
⠀
Please open Telegram to view this post
VIEW IN TELEGRAM
👍31🤡3🤔2
Поступил вопрос в коментах, зачем нужно писать много кода нейросетями
"Такое впечатление, что вы пишите тонны кода в день. Зачем? Даже на стадии написания с нуля несколько сот строк это ужа стахановец- бракодел. Программирование не беспощадное нажимание клавиш, как машинистка, а постояннве размышления о декомпозиции связности, повторном использовании, тестируемости и, главное - соответствии требованиям.
Реальная продуктивность разработчика - десятки строк в день, большого смысла при этом пользоваться генераторами кода на базе нейросетей нет."
Я отвечу зачем. Дело не в количестве даже. Зачем, например, вообще пользоваться IDE и автокомплитом? Можно ведь выучить все функции стандартной библиотеки и вводить их по буковке. А если переименовал класс - пойти и лично заменить название в каждом месте, где он используется. Так раньше и делали кстати, я помню эти времена.
Короче, есть куча рутинных задач, там где и думать-то не надо. Очевидные действия. Зачем мне писать это вручную? Ну так вот, нейросети - это тот же автокомплит/функции IDE, только чуть выше уровнем.
Добавить еще одно поле в форму, проверив что оно обязательное, и его длина от 1 до 10, и добавить это в запрос к серверу. Я сделаю это за секунды с нейросетью, причем с вероятностью 99% с первого раза правильно. При этом голова будет загружена более общими задачами (бизнес-смыслом), "мыслетопливо" не тратится на бессмысленное прописывание буковок. При этом нейросеть еще и делает делает в нужном стиле, более менее так же, как в других местах твоего кода.
И таких задач много. Написать тест (хотя бы рыбу), например. Убрать дублирование в коде двух функций. Разбить жирный React-компонент на три логические части.
Или, к примеру, я слишком расслабился, и класс (на котлине в пет-проекте) получился слишком запутанный. Я просто сказал "упрости так-то и так-то", и (после третьей попытки) оно упростило прям идеально. Т.е. одно дело придумать, а другое дело всё это скорпулёзно вбить в код. Придумать как - получить удовольствие от решения задачи, прописать по придуманному решению - тривиальная задача, трата ресурсов.
На вопрос "зачем вы пишете столько кода", у меня такой же вопрос: а зачем кучу очевидной душнины писать вручную, когда можно вместо этого за секунду избавиться от рутины. Работа становится интереснее, более верхнеуровневой. Особенно, если я плохо знаю/недолюбливаю реакт, мне проще его вообще не трогать руками, просто смотреть, что более менее норм получилось 🙂
Понятно, что есть задачи, где решение не доверить никому. Это не панацея. Ну и хер с ним, там можно и нужно вручную (с простым автокомплитом или copilot). Иногда задачи такие, что проверить чужой код может оказаться сложнее, чем самому написать.
Короче, это просто инструмент - видишь, что тут можно сэкономить время - экономишь. Нет - нет.
Ну и еще куча всяких полезных плюшек, типа:
- "перепиши более идеоматично для языка" - быстрее учишься новым фичам плохо знакомого языка, код становится лучше
- поиск багов. Кидаешь в чат текст ошибки, и получаешь версии того, что могло поломаться, сразу с фиксом. Не всегда, опять же угадывает, но если да, то экономит время, устраняя рутинный дебаг
- и тысячи других применений
Короче, нейросети в целом хороши для экономии времени и ресурса мозга, увеличения мотивационной отдачи от работы.
🫥 Cross Join
⠀
"Такое впечатление, что вы пишите тонны кода в день. Зачем? Даже на стадии написания с нуля несколько сот строк это ужа стахановец- бракодел. Программирование не беспощадное нажимание клавиш, как машинистка, а постояннве размышления о декомпозиции связности, повторном использовании, тестируемости и, главное - соответствии требованиям.
Реальная продуктивность разработчика - десятки строк в день, большого смысла при этом пользоваться генераторами кода на базе нейросетей нет."
Я отвечу зачем. Дело не в количестве даже. Зачем, например, вообще пользоваться IDE и автокомплитом? Можно ведь выучить все функции стандартной библиотеки и вводить их по буковке. А если переименовал класс - пойти и лично заменить название в каждом месте, где он используется. Так раньше и делали кстати, я помню эти времена.
Короче, есть куча рутинных задач, там где и думать-то не надо. Очевидные действия. Зачем мне писать это вручную? Ну так вот, нейросети - это тот же автокомплит/функции IDE, только чуть выше уровнем.
Добавить еще одно поле в форму, проверив что оно обязательное, и его длина от 1 до 10, и добавить это в запрос к серверу. Я сделаю это за секунды с нейросетью, причем с вероятностью 99% с первого раза правильно. При этом голова будет загружена более общими задачами (бизнес-смыслом), "мыслетопливо" не тратится на бессмысленное прописывание буковок. При этом нейросеть еще и делает делает в нужном стиле, более менее так же, как в других местах твоего кода.
И таких задач много. Написать тест (хотя бы рыбу), например. Убрать дублирование в коде двух функций. Разбить жирный React-компонент на три логические части.
Или, к примеру, я слишком расслабился, и класс (на котлине в пет-проекте) получился слишком запутанный. Я просто сказал "упрости так-то и так-то", и (после третьей попытки) оно упростило прям идеально. Т.е. одно дело придумать, а другое дело всё это скорпулёзно вбить в код. Придумать как - получить удовольствие от решения задачи, прописать по придуманному решению - тривиальная задача, трата ресурсов.
На вопрос "зачем вы пишете столько кода", у меня такой же вопрос: а зачем кучу очевидной душнины писать вручную, когда можно вместо этого за секунду избавиться от рутины. Работа становится интереснее, более верхнеуровневой. Особенно, если я плохо знаю/недолюбливаю реакт, мне проще его вообще не трогать руками, просто смотреть, что более менее норм получилось 🙂
Понятно, что есть задачи, где решение не доверить никому. Это не панацея. Ну и хер с ним, там можно и нужно вручную (с простым автокомплитом или copilot). Иногда задачи такие, что проверить чужой код может оказаться сложнее, чем самому написать.
Короче, это просто инструмент - видишь, что тут можно сэкономить время - экономишь. Нет - нет.
Ну и еще куча всяких полезных плюшек, типа:
- "перепиши более идеоматично для языка" - быстрее учишься новым фичам плохо знакомого языка, код становится лучше
- поиск багов. Кидаешь в чат текст ошибки, и получаешь версии того, что могло поломаться, сразу с фиксом. Не всегда, опять же угадывает, но если да, то экономит время, устраняя рутинный дебаг
- и тысячи других применений
Короче, нейросети в целом хороши для экономии времени и ресурса мозга, увеличения мотивационной отдачи от работы.
⠀
Please open Telegram to view this post
VIEW IN TELEGRAM
50👍39💯7❤4🍌2🌭1
Миллионокубитные процессоры становятся реальностью: Microsoft представила революционный чип Majorana 1
Microsoft совершила прорыв в квантовых вычислениях, представив первый в мире процессор Majorana 1 с топологической архитектурой.
• Разработан принципиально новый тип материала - топопроводник, который создает особое состояние материи (не твердое, не жидкое и не газообразное, а топологическое). В этом состоянии возникают и поддаются контролю частицы Майораны - экзотические частицы, предсказанные теоретически еще в 1937 году, но никогда ранее не наблюдавшиеся в природе. Они способны защищать квантовую информацию от помех, делая кубиты более стабильными
• Архитектура процессора открывает путь к размещению миллиона кубитов на чипе размером с ладонь. Такое количество кубитов необходимо для решения сложнейших задач квантовой химии и материаловедения, недоступных для классических компьютеров
• Инженеры Microsoft создали материал атом за атомом, комбинируя арсенид индия и алюминий. В этом материале при сверхнизких температурах возникают условия для появления частиц Майораны, что делает квантовые вычисления более надежными
На данный момент на чипе размещено 8 топологических кубитов. Это первая демонстрация работоспособности технологии. Архитектура чипа спроектирована так, что позволяет масштабирование до миллиона кубитов без фундаментальных изменений дизайна - как слова из кубиков-букв, можно просто добавлять новые элементы по отработанной схеме.
Потенциальные применения включают:
- Разработку катализаторов для разложения микропластика
- Создание самовосстанавливающихся материалов для мостов, самолетов и смартфонов
- Проектирование новых ферментов для медицины и сельского хозяйства
- Точное моделирование химических реакций и молекулярных взаимодействий
Результаты 20-летней работы Microsoft над этой технологией получили подтверждение в научном журнале Nature. Компания утверждает, что их подход позволит создать практически применимые квантовые компьютеры за годы, а не десятилетия.
🫥 Cross Join
⠀
Microsoft совершила прорыв в квантовых вычислениях, представив первый в мире процессор Majorana 1 с топологической архитектурой.
• Разработан принципиально новый тип материала - топопроводник, который создает особое состояние материи (не твердое, не жидкое и не газообразное, а топологическое). В этом состоянии возникают и поддаются контролю частицы Майораны - экзотические частицы, предсказанные теоретически еще в 1937 году, но никогда ранее не наблюдавшиеся в природе. Они способны защищать квантовую информацию от помех, делая кубиты более стабильными
• Архитектура процессора открывает путь к размещению миллиона кубитов на чипе размером с ладонь. Такое количество кубитов необходимо для решения сложнейших задач квантовой химии и материаловедения, недоступных для классических компьютеров
• Инженеры Microsoft создали материал атом за атомом, комбинируя арсенид индия и алюминий. В этом материале при сверхнизких температурах возникают условия для появления частиц Майораны, что делает квантовые вычисления более надежными
На данный момент на чипе размещено 8 топологических кубитов. Это первая демонстрация работоспособности технологии. Архитектура чипа спроектирована так, что позволяет масштабирование до миллиона кубитов без фундаментальных изменений дизайна - как слова из кубиков-букв, можно просто добавлять новые элементы по отработанной схеме.
Потенциальные применения включают:
- Разработку катализаторов для разложения микропластика
- Создание самовосстанавливающихся материалов для мостов, самолетов и смартфонов
- Проектирование новых ферментов для медицины и сельского хозяйства
- Точное моделирование химических реакций и молекулярных взаимодействий
Результаты 20-летней работы Microsoft над этой технологией получили подтверждение в научном журнале Nature. Компания утверждает, что их подход позволит создать практически применимые квантовые компьютеры за годы, а не десятилетия.
⠀
Please open Telegram to view this post
VIEW IN TELEGRAM
Microsoft
Microsoft’s Majorana 1 chip carves new path for quantum computing
Majorana 1, the first quantum chip powered by a new Topological Core architecture .
🔥18🤯7👍4🤷♀3😱3