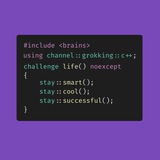
Передача владения
#новичкам
Захотелось совсем немного развить тему предыдущего поста.
В целом, мув семантика она не столько про оптимизацию(для этого есть например rvo/nrvo), сколько про передачу владения объектами. И то, что std::move ничего не мувает(а пытается сделать каст к rvalue reference) хорошо укладывается в эту концепцию. Данные не перемещаются, но вы говорите, что передаете владение этими данными.
Здесь мы передаем владение вектором из foo в bar. Заметьте, что bar оперирует правой ссылкой, то есть никакие перемещающие конструкторы не вызывались. Но такая сигнатура говорит о главном: bar ожидает эксклюзивного права владения над этим вектором. Вы должны явно мувнуть объект, чтобы вызвать bar. И не важно, что он дальше bar с этим вектором делает. Может ничего не сделает, а может и использует как-то данные. Но так решил автор кода: вызов bar предполагает передачу ему владения вектором.
Другой пример:
Функция double_elements принимает вектор по значению и возвращает набор из удвоенных элементов.
Функция foo 2 раза вызывает удвоение значений элементов. По логике функции foo, ей еще нужен vec в целости и сохранности(нужно доложить в него элемент). Поэтому она и передает в первый раз vec в double_elements по значению. Но после второго вызова вектор ей больше не нужен. Поэтому можно передать владение им в double_elements: возможно он им распорядится лучше.
Еще одна вещь, которая подчеркивает передачу владения: moved-from объект практически никак в общем случае нельзя безопасно использовать, кроме как безопасно разрушить или переприсвоить(в комментах под прошлым постом более конкретно обсуждали этот момент). Даже если функция принимает rvalue reference, это не значит, что она не изменяет объект: возможно внутренние вызовы это делают.
Поэтому можно принять за правило, что, передав владение, вы больше физически не имеете права пользоваться объектом. Это как продав компанию, вы бы продолжили иметь то же влияние на нее. Нетушки. Либо крестик снимите, либо трусы наденьте. Либо передали владение и забыли, либо скопировали и дальше попользовались.
Give away what you don't need. Stay cool.
#cppcore #cpp11
#новичкам
Захотелось совсем немного развить тему предыдущего поста.
В целом, мув семантика она не столько про оптимизацию(для этого есть например rvo/nrvo), сколько про передачу владения объектами. И то, что std::move ничего не мувает(а пытается сделать каст к rvalue reference) хорошо укладывается в эту концепцию. Данные не перемещаются, но вы говорите, что передаете владение этими данными.
void bar(std::vector<int>&& vec) {
// do nothing
}
void foo() {
std::vector<int> vec = {1, 2, 3};
bar(std::move(vec));
}Здесь мы передаем владение вектором из foo в bar. Заметьте, что bar оперирует правой ссылкой, то есть никакие перемещающие конструкторы не вызывались. Но такая сигнатура говорит о главном: bar ожидает эксклюзивного права владения над этим вектором. Вы должны явно мувнуть объект, чтобы вызвать bar. И не важно, что он дальше bar с этим вектором делает. Может ничего не сделает, а может и использует как-то данные. Но так решил автор кода: вызов bar предполагает передачу ему владения вектором.
Другой пример:
std::vector<int> double_elements(std::vector<int> vec) {
for (auto& elem: vec) {
elem *= 2;
}
return vec;
}
void foo() {
std::vector<int> vec = {1, 2, 3};
{
auto doubled = double_elements(vec);
std::println("{}", doubled);
}
vec.push_back(4);
{
auto doubled = double_elements(std::move(vec));
std::println("{}", doubled);
}
}
Функция double_elements принимает вектор по значению и возвращает набор из удвоенных элементов.
Функция foo 2 раза вызывает удвоение значений элементов. По логике функции foo, ей еще нужен vec в целости и сохранности(нужно доложить в него элемент). Поэтому она и передает в первый раз vec в double_elements по значению. Но после второго вызова вектор ей больше не нужен. Поэтому можно передать владение им в double_elements: возможно он им распорядится лучше.
Еще одна вещь, которая подчеркивает передачу владения: moved-from объект практически никак в общем случае нельзя безопасно использовать, кроме как безопасно разрушить или переприсвоить(в комментах под прошлым постом более конкретно обсуждали этот момент). Даже если функция принимает rvalue reference, это не значит, что она не изменяет объект: возможно внутренние вызовы это делают.
Поэтому можно принять за правило, что, передав владение, вы больше физически не имеете права пользоваться объектом. Это как продав компанию, вы бы продолжили иметь то же влияние на нее. Нетушки. Либо крестик снимите, либо трусы наденьте. Либо передали владение и забыли, либо скопировали и дальше попользовались.
Give away what you don't need. Stay cool.
#cppcore #cpp11
❤18👍13🔥6
Оборачиваем вспять байты
#новичкам
Когда мы низкоуровнево работаем с сетью, то надо понимать, что в данных, полученных по сети, нужно реверсировать порядок байтов, чтобы правильно интерпретировать значения. Также реверсировать порядок нужно при отправке данных по сети. Это происходит из-за того, что в стеке протоколов TCP/IP принят порядок Big-endian - старший байт хранится по младшему адресу. А на большинстве хостов(десктопов и серверов) - Little-endian: младший байт хранится по младшему адресу.
Соответственно нужны функции для реверсирования байтов. Обычно для этого используют либо компиляторные интринсики:
Либо системное апи:
Либо какое-нибудь библиотечное решение:
Но в С++23 появилась стандартная функция для разворачивания порядка байтов!
Работает она только для интегральных типов и вот ее возможная реализация:
Результат у нее собственно ровно тот, который и ожидается:
Как всегда стандарт запаздывает лет на 10-15-20, но хорошо, что все-таки завезли эту полезную функцию, которую можно кроссплатформенно использовать.
Use standard solutions. Stay cool.
#cpp23
#новичкам
Когда мы низкоуровнево работаем с сетью, то надо понимать, что в данных, полученных по сети, нужно реверсировать порядок байтов, чтобы правильно интерпретировать значения. Также реверсировать порядок нужно при отправке данных по сети. Это происходит из-за того, что в стеке протоколов TCP/IP принят порядок Big-endian - старший байт хранится по младшему адресу. А на большинстве хостов(десктопов и серверов) - Little-endian: младший байт хранится по младшему адресу.
Соответственно нужны функции для реверсирования байтов. Обычно для этого используют либо компиляторные интринсики:
### GCC/Clang
uint16_t swapped16 = __builtin_bswap16(value);
uint32_t swapped32 = __builtin_bswap32(value);
uint64_t swapped64 = __builtin_bswap64(value);
### MSVC:
uint16_t swapped16 = _byteswap_ushort(value);
uint32_t swapped32 = _byteswap_ulong(value);
uint64_t swapped64 = _byteswap_uint64(value);
Либо системное апи:
#include <arpa/inet.h> // Linux/macOS
// или
#include <winsock2.h> // Windows
uint16_t network_to_host16 = ntohs(value);
uint16_t host_to_network16 = htons(value);
uint32_t network_to_host32 = ntohl(value);
uint32_t host_to_network32 = htonl(value);
uint64_t network_to_host64 = ntohll(value);
uint64_t host_to_network64 = htonll(value);
Либо какое-нибудь библиотечное решение:
#include <boost/endian/conversion.hpp>
uint32_t value = 0x12345678;
uint32_t swapped = boost::endian::endian_reverse(value);
uint32_t to_big = boost::endian::native_to_big(value);
uint32_t to_little = boost::endian::native_to_little(value);
Но в С++23 появилась стандартная функция для разворачивания порядка байтов!
template< class T >
constexpr T byteswap( T n ) noexcept;
Работает она только для интегральных типов и вот ее возможная реализация:
template<std::integral T>
constexpr T byteswap(T value) noexcept
{
static_assert(std::has_unique_object_representations_v<T>,
"T may not have padding bits");
auto value_representation = std::bit_cast<std::array<std::byte, sizeof(T)>>(value);
std::ranges::reverse(value_representation);
return std::bit_cast<T>(value_representation);
}
Результат у нее собственно ровно тот, который и ожидается:
template<std::integral T>
void dump(T v, char term = '\n')
{
std::cout << std::hex << std::uppercase << std::setfill('0')
<< std::setw(sizeof(T) * 2) << v << " : ";
for (std::size_t i{}; i != sizeof(T); ++i, v >>= 8)
std::cout << std::setw(2) << static_cast<unsigned>(T(0xFF) & v) << ' ';
std::cout << std::dec << term;
}
int main()
{
static_assert(std::byteswap('a') == 'a');
std::cout << "byteswap for U16:\n";
constexpr auto x = std::uint16_t(0xCAFE);
dump(x);
dump(std::byteswap(x));
std::cout << "\nbyteswap for U32:\n";
constexpr auto y = std::uint32_t(0xDEADBEEFu);
dump(y);
dump(std::byteswap(y));
std::cout << "\nbyteswap for U64:\n";
constexpr auto z = std::uint64_t{0x0123456789ABCDEFull};
dump(z);
dump(std::byteswap(z));
}
// OUTPUT
// byteswap for U16:
// CAFE : FE CA
// FECA : CA FE
// byteswap for U32:
// DEADBEEF : EF BE AD DE
// EFBEADDE : DE AD BE EF
// byteswap for U64:
// 0123456789ABCDEF : EF CD AB 89 67 45 23 01
// EFCDAB8967452301 : 01 23 45 67 89 AB CD EF
Как всегда стандарт запаздывает лет на 10-15-20, но хорошо, что все-таки завезли эту полезную функцию, которую можно кроссплатформенно использовать.
Use standard solutions. Stay cool.
#cpp23
❤28👍13😁8🔥5
Атрибуты лямбды
#опытным
В прошлом посте код с картинки реально компилируется и, если вы не поняли, что это за чертовщина, то следующие несколько постов будут для вас.
В С++11 у нас появилась возможность указывать атрибуты для функции. Например:
Вы можете, например, пометить возвращаемое значение функции, как то, которое нельзя игнорировать, и компилятор даст вам по сопатке, если вы его все же заигнорите.
Ну это функции. А как же лямбды? Хочется и для них указывать атрибуты.
И атрибуты для возвращаемого значения лямбды завезли в С++23. Выглядит это так:
После скобок для захвата вы указываете список атрибутов в квадратных скобках. Выглядит интересно. Не очень элегантно, но интересно.
Одни скажут: "усложнение синтаксиса!". Другие скажут, что давно пора лямбды подтягивать ко всем возможностям обычных функций.
Тут как бы все просто: не хотите - не используйте. У лямбды и так полно опциональных обвесок, одним больше, одним меньше. Можно определить шаблонную лямбду и обвесить ее всякими концептами с trailing return type. И это будет страшный зверь. Можно сделать отдельный пост, как может выглядеть ультимативная лямбда.
Ну а если вы хотите немного больше синтаксически говорить кодом, то теперь можете использовать атрибуты для лямбд.
Don't ignore. Stay cool.
#cpp23
#опытным
В прошлом посте код с картинки реально компилируется и, если вы не поняли, что это за чертовщина, то следующие несколько постов будут для вас.
В С++11 у нас появилась возможность указывать атрибуты для функции. Например:
[[nodiscard]] int ComplicatedCompute() {
return 2*2;
}
ComplicatedCompute();
// warning: ignoring return value of 'int ComplicatedCompute()',
// declared with attribute nodiscardВы можете, например, пометить возвращаемое значение функции, как то, которое нельзя игнорировать, и компилятор даст вам по сопатке, если вы его все же заигнорите.
Ну это функции. А как же лямбды? Хочется и для них указывать атрибуты.
И атрибуты для возвращаемого значения лямбды завезли в С++23. Выглядит это так:
auto complicated_compute = [] [[nodiscard]] () { return 2 * 2; };
complicated_compute();
// warning: ignoring return value of 'main()::<lambda()>',
// declared with attribute 'nodiscard'После скобок для захвата вы указываете список атрибутов в квадратных скобках. Выглядит интересно. Не очень элегантно, но интересно.
Одни скажут: "усложнение синтаксиса!". Другие скажут, что давно пора лямбды подтягивать ко всем возможностям обычных функций.
Тут как бы все просто: не хотите - не используйте. У лямбды и так полно опциональных обвесок, одним больше, одним меньше. Можно определить шаблонную лямбду и обвесить ее всякими концептами с trailing return type. И это будет страшный зверь. Можно сделать отдельный пост, как может выглядеть ультимативная лямбда.
Ну а если вы хотите немного больше синтаксически говорить кодом, то теперь можете использовать атрибуты для лямбд.
Don't ignore. Stay cool.
#cpp23
❤22👍10🔥8😁3
Атрибуты везде
#опытным
Используют атрибуты функций не только лишь все, мало кто знает, куда их можно пихать.
Есть на самом деле 3 легальных места для навешивания атрибутов на функцию.
1️⃣ Перед типом возвращаемого значения:
Тогда он работает при непосредственном использовании функции.
2️⃣ После имени функции:
В таком виде атрибут тоже применяется к самой функции.
3️⃣ После параметров:
Тогда атрибут применяется к типу функции, а не к самой функции. Разница вот в чем:
Обычный вызов функции прекрасно компилируется. Но вот использование типа функции через decltype помечается как устаревшее.
Причем gcc и clang по-разному интерпретируют эту ситуацию. Clang говорит, что gnu::deprecated нельзя применять к типам и игнорирует атрибут. Вот ссылка на годболт для интересующихся.
Соответственно, в лямбде в тех же местах можно ставить атрибуты:
Признавайтесь, знали?)
Have your own opinion. Stay cool.
#cppcore
#опытным
Используют атрибуты функций не только лишь все, мало кто знает, куда их можно пихать.
Есть на самом деле 3 легальных места для навешивания атрибутов на функцию.
1️⃣ Перед типом возвращаемого значения:
[[deprecated]] int foo() { return 42; }Тогда он работает при непосредственном использовании функции.
foo();
// warning: 'int foo()' is deprecated
2️⃣ После имени функции:
int foo [[deprecated]] () { return 42; }В таком виде атрибут тоже применяется к самой функции.
3️⃣ После параметров:
int foo() [[gnu::deprecated]] { return 42; }Тогда атрибут применяется к типу функции, а не к самой функции. Разница вот в чем:
int foo() [[gnu::deprecated]] { return 42; }
int main() {
foo(); // no warnings
using FuncType = decltype(foo); // use of type is deprecated
}Обычный вызов функции прекрасно компилируется. Но вот использование типа функции через decltype помечается как устаревшее.
Причем gcc и clang по-разному интерпретируют эту ситуацию. Clang говорит, что gnu::deprecated нельзя применять к типам и игнорирует атрибут. Вот ссылка на годболт для интересующихся.
Соответственно, в лямбде в тех же местах можно ставить атрибуты:
auto complicated_compute = [] [[nodiscard]] () [[gnu::deprecated]] {
return 2 * 2;
};Признавайтесь, знали?)
Have your own opinion. Stay cool.
#cppcore
👍25🤯20❤10🔥6
Атрибуты параметров функции
#новичкам
Атрибуты можно также применять к параметрам функции. Это помогает чуть полнее в коде функции аннотировать некоторые свойства параметров.
Вы определили какой-то интерфейс с методом, принимающим один параметр. И в какой-то момент появилась необходимость создать наследника, реализующего этот интерфейс, однако реализации не нужен параметр param. Возможно Implementation - это какой-то мок, у которого в принципе пустая реализация.
Если вы активно используете варнинги компилятора и прочие линтеры, при попытке собрать такой код вы скорее всего увидите предупреждение/ошибку компиляции. Чтобы стало все чётенько, стоит пометить
Однако из стандартных атрибутов по сути имеет смысл использовать только этот самый maybe_unused.
Но атрибуты - это не только средство общения с компилятором. Это еще и средство налаживания коммуникации между автором кода и его пользователями/читателями.
Например:
Вы поместили в хэдэр такое объявление, тем самым явно сказав пользователю и компилятору, что указатели не должны быть нулевыми. Если компилятор докажет в compile-time, что в функцию передали nullptr, то он выкинет предупреждение. Ну а пользователь четко по сигнатуре видит, что функция не ожидает нулевой указатель и как порядочный гражданин не будет его передавать.
Annotate your code. Stay cool.
#cppcore
#новичкам
Атрибуты можно также применять к параметрам функции. Это помогает чуть полнее в коде функции аннотировать некоторые свойства параметров.
class Interface {
public:
virtual void method(int param) = 0;
};
class Implementation : public Interface {
public:
void method(int param) override {
// this implementation doesn't use param so mark it
}
};Вы определили какой-то интерфейс с методом, принимающим один параметр. И в какой-то момент появилась необходимость создать наследника, реализующего этот интерфейс, однако реализации не нужен параметр param. Возможно Implementation - это какой-то мок, у которого в принципе пустая реализация.
Если вы активно используете варнинги компилятора и прочие линтеры, при попытке собрать такой код вы скорее всего увидите предупреждение/ошибку компиляции. Чтобы стало все чётенько, стоит пометить
param атрибутом maybe_unused, тем самым явно указав компилятору, что параметр не используется намеренно. И проблема исчезнет.Однако из стандартных атрибутов по сути имеет смысл использовать только этот самый maybe_unused.
Но атрибуты - это не только средство общения с компилятором. Это еще и средство налаживания коммуникации между автором кода и его пользователями/читателями.
Например:
size_t safe_strcpy(
[[gnu::nonnull]] char* dest,
[[gnu::nonnull]] const char* src,
size_t dest_size
);
Вы поместили в хэдэр такое объявление, тем самым явно сказав пользователю и компилятору, что указатели не должны быть нулевыми. Если компилятор докажет в compile-time, что в функцию передали nullptr, то он выкинет предупреждение. Ну а пользователь четко по сигнатуре видит, что функция не ожидает нулевой указатель и как порядочный гражданин не будет его передавать.
Annotate your code. Stay cool.
#cppcore
❤21🔥16👍9🤯1
Множество атрибутов
#опытным
Если вы хотите указать несколько атрибутов для вашей функции, вы можете использовать следующий синтаксис:
1️⃣ Списочный. Внутри одних скобок перечисляете все атрибуты:
2️⃣ Многоскобочный. Для больших любителей распиленных квадратов. Очень больших:
Больше квадратных скобок!
Также если вы используете несколько атрибутов из какого-то одного неймспейса, то можете использовать директиву using:
Но тогда котлеты отдельно, мухи отдельно. Все атрибуты одного неймспейса нужно уносить в отдельные скобки. Это фича С++17.
Что интересно, вы можете написать полную чупуху:
И это скомпилируется! Стандарт поддерживает любые implementation-defined атрибуты. Причем неизвестные атрибуты просто игнорируются. Правда игнор спровождается варнингами, которые тем не менее можно скрыть опциями, подобным -Wno-attributes.
Таким образом, если ваш код компилируется под разные системы, то вы можете не стесняясь использовать дублирующие атрибуты, предоставляемые разными компиляторами. Так на любой платформе можно получить одинаковое поведение.
Love squares. Stay cool.
#cppcore #cpp17
#опытным
Если вы хотите указать несколько атрибутов для вашей функции, вы можете использовать следующий синтаксис:
1️⃣ Списочный. Внутри одних скобок перечисляете все атрибуты:
[[gnu::always_inline, gnu::const, gnu::hot, nodiscard]] int f();
2️⃣ Многоскобочный. Для больших любителей распиленных квадратов. Очень больших:
[[gnu::always_inline]] [[gnu::hot]] [[gnu::const]] [[nodiscard]] int f();
Больше квадратных скобок!
Также если вы используете несколько атрибутов из какого-то одного неймспейса, то можете использовать директиву using:
[[using gnu : always_inline, const, hot]] [[nodiscard]] int f();
Но тогда котлеты отдельно, мухи отдельно. Все атрибуты одного неймспейса нужно уносить в отдельные скобки. Это фича С++17.
Что интересно, вы можете написать полную чупуху:
[[rust, will, replace, cpp]] int f();
И это скомпилируется! Стандарт поддерживает любые implementation-defined атрибуты. Причем неизвестные атрибуты просто игнорируются. Правда игнор спровождается варнингами, которые тем не менее можно скрыть опциями, подобным -Wno-attributes.
Таким образом, если ваш код компилируется под разные системы, то вы можете не стесняясь использовать дублирующие атрибуты, предоставляемые разными компиляторами. Так на любой платформе можно получить одинаковое поведение.
Love squares. Stay cool.
#cppcore #cpp17
🔥22❤13👍10👎1
Парсим ужас
#новичкам
Вот мы и рассмотрели все необходимые компоненты, чтобы понять, что написано здесь:
Если включить clang-format, то код преобразится во что-то такое:
Давайте посмотрим, откуда так много скобок:
1️⃣ Перед типом возвращаемого значения main определены 2 пустые области для указания атрибутов функции main.
2️⃣ Перед телом функции main определена пустая область для атрибутов, применяемых к типу функции main.
3️⃣ После блока захвата лямбды определена пустая область для атрибутов, применяемых к самой лямбде.
4️⃣ Внутри списка параметров лямбды определена пустая область для атрибутов, применяемых к единственному параметру лямбды.
5️⃣ Сама лямбда является generic и принимает массив неизвестного типа.
6️⃣ Перед телом лямбды определены 2 пустые области для атрибутов, применяемых к типу лямбды.
7️⃣ Вызываем лямбду с помощью указателя на функцию main.
8️⃣ Ну и разбавили это дело несколькими лишними скоупами по пути.
Не так уж и сложно оказалось)
Так, новичковая часть закончилась.
#опытным
Интересно, что этот код компилируется на gcc, но не на clang.
cppinsights показывает, что лямбда раскрывается во что-то такое:
То есть по факту мы имеем шаблонный оператор с auto параметром.
Как интерпретировать эту штуку - дело нетривиальное и по ходу компиляторы это делают по-разному. Видимо gcc при попытке инстанцировать шаблон с параметром int() выводит auto как тот же самый тип функции int() и в итоге лямбда принимает указатель на функцию. А clang при попытке инстанцировать шаблон выводит тип параметра функции как массив функций int() и не может принять main в качестве такого параметра.
Пишите ваше мнение, кто прав, кто виноват)
Deal with horrible things step by step. Stay cool.
#cppcore #compiler
#новичкам
Вот мы и рассмотрели все необходимые компоненты, чтобы понять, что написано здесь:
[[]][[]]int main()[[]]{{[][][[]][[]]{{{}}}(main);}}Если включить clang-format, то код преобразится во что-то такое:
/*1*/[[]][[]] int main()/*2*/[[]] {
{
[]/*3*/[[]](/*4*/[[]] /*5*/auto [])/*6*/[[]][[]] {
{
{}
}
}/*7*/(main);
}
}Давайте посмотрим, откуда так много скобок:
1️⃣ Перед типом возвращаемого значения main определены 2 пустые области для указания атрибутов функции main.
2️⃣ Перед телом функции main определена пустая область для атрибутов, применяемых к типу функции main.
3️⃣ После блока захвата лямбды определена пустая область для атрибутов, применяемых к самой лямбде.
4️⃣ Внутри списка параметров лямбды определена пустая область для атрибутов, применяемых к единственному параметру лямбды.
5️⃣ Сама лямбда является generic и принимает массив неизвестного типа.
6️⃣ Перед телом лямбды определены 2 пустые области для атрибутов, применяемых к типу лямбды.
7️⃣ Вызываем лямбду с помощью указателя на функцию main.
8️⃣ Ну и разбавили это дело несколькими лишними скоупами по пути.
Не так уж и сложно оказалось)
Так, новичковая часть закончилась.
#опытным
Интересно, что этот код компилируется на gcc, но не на clang.
cppinsights показывает, что лямбда раскрывается во что-то такое:
class __lambda_5_17 {
public:
template <class type_parameter_0_0>
inline /*constexpr */ auto operator()(auto *) const {
{ {}; };
}
private:
template <class type_parameter_0_0>
static inline /*constexpr */ auto __invoke(auto *__param0) {
return __lambda_5_17{}.operator()<type_parameter_0_0>(__param0);
}
public:
// /*constexpr */ __lambda_5_17() = default;
};То есть по факту мы имеем шаблонный оператор с auto параметром.
Как интерпретировать эту штуку - дело нетривиальное и по ходу компиляторы это делают по-разному. Видимо gcc при попытке инстанцировать шаблон с параметром int() выводит auto как тот же самый тип функции int() и в итоге лямбда принимает указатель на функцию. А clang при попытке инстанцировать шаблон выводит тип параметра функции как массив функций int() и не может принять main в качестве такого параметра.
Пишите ваше мнение, кто прав, кто виноват)
Deal with horrible things step by step. Stay cool.
#cppcore #compiler
Telegram
Грокаем C++
И это все компилируется!
Сможете сказать, откуда каждая скобка взялась?)
Сможете сказать, откуда каждая скобка взялась?)
❤🔥24😁13❤11👍3🔥3
Мок собеседования
#новичкам #опытным
Представьте, что вы вкатун в АйТишку плюсовую. Прочитали несколько книжек, прошли кучу бесплатных курсов и дописали свой первыйвелосипед пет-проект.
Пора бы попробовать устроиться на работу. Но учеба и учебные проекты - это одно, а собеседования - это совсем другое. Надо знать, как их проходить, это отдельная наука.
Но как узнать, как проходить собесы, если никогда их не проходил?(оставим за скобками вопрос, как вообще добраться до собеса, это то еще шаманство)
Для этого существуют мок-собеседования. То есть дословно "имитация" собеседования.
В идеале его проводить с живым человеком, например вашим ментором или любым другим опытным чуваком, который изъявляет желание.
Но если вы стеснительный волк-одиночка, к тому же еще и бедный(за занятия с ментором нужно платить), то и для вас есть вариант.
В сети лежит куча готовых мок-собеседований по С++ на позиции разных уровней.
На самом деле видео мок-собесов - не бомже-вариант, а маст хэв для любого человека, неуверенного в своих скиллах прохождения собеседований. Весь из себя сеньор, выходивший на рынок 10 лет назад, тоже скорее всего для себя что-то подчерпнет.
Даже в русскоязычном пространстве можно найти много таких видосов. Основные мок-интервьюеры у нас это:
- Ambushed raccoon
- Владимир Балун
Ну а мы за вас собрали подборку всех(или почти всех) мок-собесов на русском языке по С++ и разбили их по уровням.
Junior:
- https://www.youtube.com/watch?v=_-EkLLZ5svk
- https://www.youtube.com/watch?v=H1mIHJxnm9E
- https://www.youtube.com/watch?v=PQ1C_0EAHFI
- https://www.youtube.com/watch?v=BCpHj698D8U
- https://youtu.be/7g8HufwNa0g?si=XVKRsuoHN20MJx3i
- https://youtu.be/a18qTcWn-II?si=OttfqKh0bHLjueOY
- https://www.youtube.com/live/rLOgkn6xVQA?si=lFqwGf_Wsr8IohHo
- https://youtu.be/VfoxaNLVtmQ?si=elt-OyZWB5tXp5hI
Middle:
- https://www.youtube.com/watch?v=nMdNehH8-Ss
- https://www.youtube.com/watch?v=Ed37R0FvkQ8
- https://www.youtube.com/watch?v=IDqMy4_xkb4
- https://www.youtube.com/watch?v=BOUEbS5L4-8
- https://www.youtube.com/watch?v=PwVMcxCBIkg
- https://www.youtube.com/watch?v=Np6UrKN6ZbA
- https://www.youtube.com/watch?v=1Ez3kbK_3bI
- https://www.youtube.com/watch?v=s6BXbEPaw5g
- https://www.youtube.com/watch?v=yfoFtu28n4o
- https://www.youtube.com/watch?v=cT3fonCyxJk
- https://www.youtube.com/watch?v=xwb2FAKxCUo
- https://www.youtube.com/watch?v=bOgz4K-ARzQ
- https://www.youtube.com/watch?v=wR4VRCp_BYo
- https://youtu.be/5enBKMwOST0?si=i-5mdyrxeeFiZKo1
Senior:
- https://www.youtube.com/watch?v=OwMEK_W8Ysw
- https://www.youtube.com/watch?v=dZpe58HKX-8
Просто вопросы и задачи с собесов:
- https://www.youtube.com/watch?v=boYk6gFg84E
- https://www.youtube.com/watch?v=ViHNB0_1j90
- https://www.youtube.com/watch?v=aYM7lksQ8yg
- https://www.youtube.com/watch?v=UdY_YMFx7SY
- https://www.youtube.com/watch?v=PStQ4jhhz08
- https://www.youtube.com/watch?v=wMYfg_iPqMQ
Просмотрев эти видосы(возможно по нескольку раз) и переписав ответы на все вопросы себе в тетрадочку или файлик, вы будете знать ответы на 95% устных вопросов, которые вам будут задавать в условной компании Х.
Возможно вы не все будете до конца понимать, но уж очень глупых ошибок точно не совершите.
Ну а для любителем native english есть канал Кодингового Иисуса. Он постоянно у себя на стримах спрашивает у людей за плюсы. В основном люди валятся на простых вопросах, но иногда попадаются качественные собеседники. По крайней мере практика языка вам будет точно обеспечена.
Еще раз. Смотреть эти видосы можно(и почти нужно) примерно всем, кто задумывается о смене работы. Кому-то вспомнить, кому-то заполнить пробелы, кому-то понять, что все совсем плохо и садиться учить базу. Каждый найдет себе занятие по душе.
Practice makes perfect. Stay cool.
#interview
#новичкам #опытным
Представьте, что вы вкатун в АйТишку плюсовую. Прочитали несколько книжек, прошли кучу бесплатных курсов и дописали свой первый
Пора бы попробовать устроиться на работу. Но учеба и учебные проекты - это одно, а собеседования - это совсем другое. Надо знать, как их проходить, это отдельная наука.
Но как узнать, как проходить собесы, если никогда их не проходил?(оставим за скобками вопрос, как вообще добраться до собеса, это то еще шаманство)
Для этого существуют мок-собеседования. То есть дословно "имитация" собеседования.
В идеале его проводить с живым человеком, например вашим ментором или любым другим опытным чуваком, который изъявляет желание.
Но если вы стеснительный волк-одиночка, к тому же еще и бедный(за занятия с ментором нужно платить), то и для вас есть вариант.
В сети лежит куча готовых мок-собеседований по С++ на позиции разных уровней.
На самом деле видео мок-собесов - не бомже-вариант, а маст хэв для любого человека, неуверенного в своих скиллах прохождения собеседований. Весь из себя сеньор, выходивший на рынок 10 лет назад, тоже скорее всего для себя что-то подчерпнет.
Даже в русскоязычном пространстве можно найти много таких видосов. Основные мок-интервьюеры у нас это:
- Ambushed raccoon
- Владимир Балун
Ну а мы за вас собрали подборку всех(или почти всех) мок-собесов на русском языке по С++ и разбили их по уровням.
Junior:
- https://www.youtube.com/watch?v=_-EkLLZ5svk
- https://www.youtube.com/watch?v=H1mIHJxnm9E
- https://www.youtube.com/watch?v=PQ1C_0EAHFI
- https://www.youtube.com/watch?v=BCpHj698D8U
- https://youtu.be/7g8HufwNa0g?si=XVKRsuoHN20MJx3i
- https://youtu.be/a18qTcWn-II?si=OttfqKh0bHLjueOY
- https://www.youtube.com/live/rLOgkn6xVQA?si=lFqwGf_Wsr8IohHo
- https://youtu.be/VfoxaNLVtmQ?si=elt-OyZWB5tXp5hI
Middle:
- https://www.youtube.com/watch?v=nMdNehH8-Ss
- https://www.youtube.com/watch?v=Ed37R0FvkQ8
- https://www.youtube.com/watch?v=IDqMy4_xkb4
- https://www.youtube.com/watch?v=BOUEbS5L4-8
- https://www.youtube.com/watch?v=PwVMcxCBIkg
- https://www.youtube.com/watch?v=Np6UrKN6ZbA
- https://www.youtube.com/watch?v=1Ez3kbK_3bI
- https://www.youtube.com/watch?v=s6BXbEPaw5g
- https://www.youtube.com/watch?v=yfoFtu28n4o
- https://www.youtube.com/watch?v=cT3fonCyxJk
- https://www.youtube.com/watch?v=xwb2FAKxCUo
- https://www.youtube.com/watch?v=bOgz4K-ARzQ
- https://www.youtube.com/watch?v=wR4VRCp_BYo
- https://youtu.be/5enBKMwOST0?si=i-5mdyrxeeFiZKo1
Senior:
- https://www.youtube.com/watch?v=OwMEK_W8Ysw
- https://www.youtube.com/watch?v=dZpe58HKX-8
Просто вопросы и задачи с собесов:
- https://www.youtube.com/watch?v=boYk6gFg84E
- https://www.youtube.com/watch?v=ViHNB0_1j90
- https://www.youtube.com/watch?v=aYM7lksQ8yg
- https://www.youtube.com/watch?v=UdY_YMFx7SY
- https://www.youtube.com/watch?v=PStQ4jhhz08
- https://www.youtube.com/watch?v=wMYfg_iPqMQ
Просмотрев эти видосы(возможно по нескольку раз) и переписав ответы на все вопросы себе в тетрадочку или файлик, вы будете знать ответы на 95% устных вопросов, которые вам будут задавать в условной компании Х.
Возможно вы не все будете до конца понимать, но уж очень глупых ошибок точно не совершите.
Ну а для любителем native english есть канал Кодингового Иисуса. Он постоянно у себя на стримах спрашивает у людей за плюсы. В основном люди валятся на простых вопросах, но иногда попадаются качественные собеседники. По крайней мере практика языка вам будет точно обеспечена.
Еще раз. Смотреть эти видосы можно(и почти нужно) примерно всем, кто задумывается о смене работы. Кому-то вспомнить, кому-то заполнить пробелы, кому-то понять, что все совсем плохо и садиться учить базу. Каждый найдет себе занятие по душе.
Practice makes perfect. Stay cool.
#interview
❤55🔥20👍13❤🔥4🙏4
Как запустить cpp файл из консоли?
Да, да, именно запустить файл. Берете bash, берете файл. Как одно воткнуть в другое и получить результат работы программы?
Следите за пальцами:
Есть ли мы попытаемся запустить файл с этим содержимым через терминал, то будет выполняться следующая последовательность шагов:
1️⃣ Ядро смотрит на первые 2 байта файла и пытается найти там шебанг -
2️⃣ Если шебанга нет и файл не является исполняемым(как у нас), то файл считается shell-скриптом и исполняется с помощью текущего командного интерпретатора.
3️⃣ Для shell-скриптов символ # обозначает начало однострочного комментария, поэтому первая строчка игнорируется.
4️⃣ Интерпретатор встречает команду компиляции и выполняет ее.
5️⃣ Теперь мы пытаемся реально скомпилировать этот файл с помощью g++. На этапе препроцессинга ветка условия
6️⃣ После компиляции интерпретатор запускает исполняемый файл и завершает работу на инструкции
Напишите в терминале
И увидите заветные слова.
Дожили! Превратили С++ в питон...
PS: Большое спасибо за идею и материалы Даниилу @dkay7.
Have a fun. Stay cool.
#fun
Да, да, именно запустить файл. Берете bash, берете файл. Как одно воткнуть в другое и получить результат работы программы?
Следите за пальцами:
#if 0
g++ test.cpp -o test && ./test
exit 0
#endif
#include <iostream>
int main() {
std::cout << "Hello, World!" << std::endl;
}
Есть ли мы попытаемся запустить файл с этим содержимым через терминал, то будет выполняться следующая последовательность шагов:
1️⃣ Ядро смотрит на первые 2 байта файла и пытается найти там шебанг -
#!. Если нашла, то в этой строчке будет указан путь до нужного интерпретатора.2️⃣ Если шебанга нет и файл не является исполняемым(как у нас), то файл считается shell-скриптом и исполняется с помощью текущего командного интерпретатора.
3️⃣ Для shell-скриптов символ # обозначает начало однострочного комментария, поэтому первая строчка игнорируется.
4️⃣ Интерпретатор встречает команду компиляции и выполняет ее.
5️⃣ Теперь мы пытаемся реально скомпилировать этот файл с помощью g++. На этапе препроцессинга ветка условия
#if 0 выбросится из текста файла и компилироваться будет только реально С++ код.6️⃣ После компиляции интерпретатор запускает исполняемый файл и завершает работу на инструкции
exit 0. Остальной С++ код он уже не увидит.Напишите в терминале
chmod +x test.cpp
./test.cpp
И увидите заветные слова.
Дожили! Превратили С++ в питон...
PS: Большое спасибо за идею и материалы Даниилу @dkay7.
Have a fun. Stay cool.
#fun
10❤58🔥21👍18😁14🤯12👀3🗿3🐳1
Bootstrap
#новичкам
Если вы когда-нибудь заходили в исходники своего компилятора, то могли заметить, что его исходный код написан на С++.
Также возможно вы слышали, что компилятор java написан на java.
Если вдуматься в эти факты, то невольно задаешься вопросом: а как это вообще возможно? Нельзя же себя поднять за волосы из болота.
Вообще-то барон Мюнхгаузен смог и мы сможем!
Нужно лишь немного опоры. Чуть-чуть оттолкнуться.
Давайте пройдем весь процесс от и до.
1️⃣ Вы решили написать свой язык самый лучший язык во всей вселенной GOAT. Разработали синтаксис и правила языка, пару раз пооргазмировали от его крутости.
2️⃣ Дальше вам нужно уметь конвертировать код на новом языке в программу. Выхода нет: вы быстренько пишите простой компилятор или интерпретатор GOAT на уже существующем языке. Пусть для определенности вы написали компилятор на С. Компилируете его каким-нибудь gcc и у вас появляется первый компилятор языка GOAT. Это так называемый компилятор начальной загрузки или bootstrap компилятор.
Отлично! Вы можете писать программы на новом языке!
3️⃣ Но компилятор - это же тоже программа. Теперь вы можете на GOAT написать компилятор GOAT и скомпилировать его bootstrap компилятором. В итоге у вас получится рабочий компилятор GOAT, написанный на языке GOAT! Вот яйцо и родило яйцо.
4️⃣ В дальнейшем вы можете развивать компилятор, используя сам язык GOAT и перекомпилируя его самим собой.
Весь этот процесс называется bootstrapping.
Первый компилятор и jvm были написаны на С. Первый компилятор С был написан на ассемблере. Pascal'я - на Fortran.
Интересно, что clang изначально был написан на урезанной версии С++, которая компилировалась и на gcc, и на msvc. Поэтому clang можно использовать на винде.
Преимущества бутстраппинга:
👉🏿 Демонстрирует зрелость и самодостаточность языка. Можно развиваться самостоятельно и не зависеть от других технологий.
👉🏿 Разработчики компилятора могут использовать все возможности языка, для которого они пишут компилятор.
👉🏿 Тестирование возможностей языка. Если вам недостаточно инструментов в языке, чтобы написать компилятор, значит язык нужно дорабатывать.
👉🏿 Упрощается разработка компилятора. Не нужно знать несколько языков.
А вот как бутстрапился С++ разберем в следующем посте.
Be self-sufficient. Stay cool.
#tools #compiler
#новичкам
Если вы когда-нибудь заходили в исходники своего компилятора, то могли заметить, что его исходный код написан на С++.
Также возможно вы слышали, что компилятор java написан на java.
Если вдуматься в эти факты, то невольно задаешься вопросом: а как это вообще возможно? Нельзя же себя поднять за волосы из болота.
Вообще-то барон Мюнхгаузен смог и мы сможем!
Нужно лишь немного опоры. Чуть-чуть оттолкнуться.
Давайте пройдем весь процесс от и до.
1️⃣ Вы решили написать свой язык самый лучший язык во всей вселенной GOAT. Разработали синтаксис и правила языка, пару раз пооргазмировали от его крутости.
2️⃣ Дальше вам нужно уметь конвертировать код на новом языке в программу. Выхода нет: вы быстренько пишите простой компилятор или интерпретатор GOAT на уже существующем языке. Пусть для определенности вы написали компилятор на С. Компилируете его каким-нибудь gcc и у вас появляется первый компилятор языка GOAT. Это так называемый компилятор начальной загрузки или bootstrap компилятор.
Отлично! Вы можете писать программы на новом языке!
3️⃣ Но компилятор - это же тоже программа. Теперь вы можете на GOAT написать компилятор GOAT и скомпилировать его bootstrap компилятором. В итоге у вас получится рабочий компилятор GOAT, написанный на языке GOAT! Вот яйцо и родило яйцо.
4️⃣ В дальнейшем вы можете развивать компилятор, используя сам язык GOAT и перекомпилируя его самим собой.
Весь этот процесс называется bootstrapping.
Первый компилятор и jvm были написаны на С. Первый компилятор С был написан на ассемблере. Pascal'я - на Fortran.
Интересно, что clang изначально был написан на урезанной версии С++, которая компилировалась и на gcc, и на msvc. Поэтому clang можно использовать на винде.
Преимущества бутстраппинга:
👉🏿 Демонстрирует зрелость и самодостаточность языка. Можно развиваться самостоятельно и не зависеть от других технологий.
👉🏿 Разработчики компилятора могут использовать все возможности языка, для которого они пишут компилятор.
👉🏿 Тестирование возможностей языка. Если вам недостаточно инструментов в языке, чтобы написать компилятор, значит язык нужно дорабатывать.
👉🏿 Упрощается разработка компилятора. Не нужно знать несколько языков.
А вот как бутстрапился С++ разберем в следующем посте.
Be self-sufficient. Stay cool.
#tools #compiler
1❤48👍22🔥10🥱1
История компилятора С++
#новичкам
С++ начал свой путь в 1979 году, когда Бьерн Страуструп работал над своей диссертацией. Он назвал его "С с классами". Это была довольно примитивная версия С++, были просто добавлены классы, их методы, возможность наследования и другие более минорные фичи. Никакого полиморфизма и шаблонов. Для компиляции этой версии было достаточно написать препроцессор для С компилятора, который бы транслировал инструкции С++ в С-шный код. Этот препроцессор + С-компилятор назывался CPre.
Но Бьерн не забросил свою разработку и в 1982 году разработал улучшенную версию С с классами и назвал ее С++. Она уже включала виртуальные функции, перегрузку функций и операторов, ссылки, стандартные функции работы с памятью(new/delete).
И CPre уже не справлялся с такими мощными фичами. Да он и изначально был довольно костыльным, потому что не было работы с типами, которой быть и не могло на этапе препроцессинга. Нужно было делать лексический и синтаксический анализ, строить ast дерево программы, чтобы поддерживать типобезопасность.
Но хотелось сохранить возможность получения С-шного кода из С++, потому что это способствовало более быстрому распространению языка и его можно было использовать в новых модулях старых проектов.
По сути нужен был полноценный компилятор, преобразующий С++ код в С. И им стал Cfront.
Вот теперь пошли интересности.
Первая простейшая версия языка С++ и компилятора Cfront была написана на "С с классами" и скомпилирована CPre. В дальнейшем мощные фичи в язык добавлялись уже с помощью Сfront, который писался на предыдущей версии С++. CPre не вывозил возросшей сложности.
Ну хорошо, Бьерн у себя на домашнем компьютере с определенной архитектурой имеет свежайшую версию Cfront, которая написана на С++. С++ уже не может быть скомпилирован CPre. Как получить компилятор на другой архитектуре?
Здесь помогла именно трансляция С++ в С код. При компиляции свежей версии Cfront на выходе на самом деле получается Сшный код. Если этот код чуть причесать и убрать оттуда платформозависимые решения, то можно принести его на компьютер с другой архитектурой, скомпилировать его существующим там С-компилятором и получить готовый Cfront, умеющий компилировать С++.
Таким образом распространялись версии компилятора под разные архитектуры.
Cfront успешно развивался еще несколько лет, но у него были объективные недостатки:
👉🏿 скорость компиляции в С/С++ и так не славится скорость, так тут еще и двухступенчатая компиляция была
👉🏿 при попытке компиляции ошибки показывались в сгенерированном C-коде, а не в исходном C++, что затрудняло отладку
👉🏿 некоторые возможности C++ было сложно или невозможно реализовать через трансляцию в C. С не всесилен и довольно лаконичен в используемых инструментах.
В итоге при попытке добавить в язык исключения Cfront умер...
Но благо разработчики прониклись С++ и поняли, что для быстрой и полноценной работы с С++ им нужен полноценный компилятор С++ в асм. Ну а дальше начал разрастаться зоопарк плюсовых компиляторов, некоторые умирали, а некоторые дожили до наших дней.
The end.
Know that everything has its limits. Stay cool.
#tools #compiler
#новичкам
С++ начал свой путь в 1979 году, когда Бьерн Страуструп работал над своей диссертацией. Он назвал его "С с классами". Это была довольно примитивная версия С++, были просто добавлены классы, их методы, возможность наследования и другие более минорные фичи. Никакого полиморфизма и шаблонов. Для компиляции этой версии было достаточно написать препроцессор для С компилятора, который бы транслировал инструкции С++ в С-шный код. Этот препроцессор + С-компилятор назывался CPre.
Но Бьерн не забросил свою разработку и в 1982 году разработал улучшенную версию С с классами и назвал ее С++. Она уже включала виртуальные функции, перегрузку функций и операторов, ссылки, стандартные функции работы с памятью(new/delete).
И CPre уже не справлялся с такими мощными фичами. Да он и изначально был довольно костыльным, потому что не было работы с типами, которой быть и не могло на этапе препроцессинга. Нужно было делать лексический и синтаксический анализ, строить ast дерево программы, чтобы поддерживать типобезопасность.
Но хотелось сохранить возможность получения С-шного кода из С++, потому что это способствовало более быстрому распространению языка и его можно было использовать в новых модулях старых проектов.
По сути нужен был полноценный компилятор, преобразующий С++ код в С. И им стал Cfront.
Вот теперь пошли интересности.
Первая простейшая версия языка С++ и компилятора Cfront была написана на "С с классами" и скомпилирована CPre. В дальнейшем мощные фичи в язык добавлялись уже с помощью Сfront, который писался на предыдущей версии С++. CPre не вывозил возросшей сложности.
Ну хорошо, Бьерн у себя на домашнем компьютере с определенной архитектурой имеет свежайшую версию Cfront, которая написана на С++. С++ уже не может быть скомпилирован CPre. Как получить компилятор на другой архитектуре?
Здесь помогла именно трансляция С++ в С код. При компиляции свежей версии Cfront на выходе на самом деле получается Сшный код. Если этот код чуть причесать и убрать оттуда платформозависимые решения, то можно принести его на компьютер с другой архитектурой, скомпилировать его существующим там С-компилятором и получить готовый Cfront, умеющий компилировать С++.
Таким образом распространялись версии компилятора под разные архитектуры.
Cfront успешно развивался еще несколько лет, но у него были объективные недостатки:
👉🏿 скорость компиляции в С/С++ и так не славится скорость, так тут еще и двухступенчатая компиляция была
👉🏿 при попытке компиляции ошибки показывались в сгенерированном C-коде, а не в исходном C++, что затрудняло отладку
👉🏿 некоторые возможности C++ было сложно или невозможно реализовать через трансляцию в C. С не всесилен и довольно лаконичен в используемых инструментах.
В итоге при попытке добавить в язык исключения Cfront умер...
Но благо разработчики прониклись С++ и поняли, что для быстрой и полноценной работы с С++ им нужен полноценный компилятор С++ в асм. Ну а дальше начал разрастаться зоопарк плюсовых компиляторов, некоторые умирали, а некоторые дожили до наших дней.
The end.
Know that everything has its limits. Stay cool.
#tools #compiler
❤43👍17🔥6🤷♂2🐳2👏1
Наследие Cfront. this
#новичкам
Cfront был первым компилятором С++. И это оказало большое влияние на то, какие подходы к компиляции C++ используют другие компиляторы. В следующих нескольких постах мы обсудим наследие, которое после себя оставил Cfront.
Главное, о чем надо помнить в этой серии - Cfront компилировал С++ код в С. То есть все концепции языка С++, которыми Cfront оперировал, можно было представить в С коде. Некоторые такие представления перетекли в стандарт, некоторые остались на уровне реализации.
Сегодня поговорим про такую привычную и базовую вещь, как this или неявный указатель на объект класса в методах.
Мы уже написали несколько постов о том, как можно вызывать методы классов с помощью указателя на функцию и объекта класса(или указателя на него). Тык, тык и тык. Но здесь повторим более наглядно чтоли.
Вот у Cfront на входе есть С++ код:
У каждого класса есть конструктор, деструктор и набор методов. Все это компилировалось в обычные функции, которые первым аргументом принимали неявный указатель this на экземпляр сишной структуры:
Константность метода регулировалась константностью указателя this.
Если есть класс, значит должно быть использование:
Этот код превращался в нечто подобное:
Заметьте, что в конце любого скоупа, в котором был создан объект компилятором вставлялся вызов деструктора, тем самым обеспечивая идиому RAII.
Have a legacy. Stay cool.
#cppcore #goodoldc #compiler
#новичкам
Cfront был первым компилятором С++. И это оказало большое влияние на то, какие подходы к компиляции C++ используют другие компиляторы. В следующих нескольких постах мы обсудим наследие, которое после себя оставил Cfront.
Главное, о чем надо помнить в этой серии - Cfront компилировал С++ код в С. То есть все концепции языка С++, которыми Cfront оперировал, можно было представить в С коде. Некоторые такие представления перетекли в стандарт, некоторые остались на уровне реализации.
Сегодня поговорим про такую привычную и базовую вещь, как this или неявный указатель на объект класса в методах.
Мы уже написали несколько постов о том, как можно вызывать методы классов с помощью указателя на функцию и объекта класса(или указателя на него). Тык, тык и тык. Но здесь повторим более наглядно чтоли.
Вот у Cfront на входе есть С++ код:
class Point {
int x, y;
public:
Point(int x, int y) : x(x), y(y) {}
int get_x() const { return x; }
int get_y() const { return y; }
void move(int dx, int dy) { x += dx; y += dy; }
};У каждого класса есть конструктор, деструктор и набор методов. Все это компилировалось в обычные функции, которые первым аргументом принимали неявный указатель this на экземпляр сишной структуры:
struct Point {
int x;
int y;
};
void Point_ctor(struct Point* this, int x, int y) {
this->x = x;
this->y = y;
}
int Point_get_x(const struct Point* this) {
return this->x;
}
int Point_get_y(const struct Point* this) {
return this->y;
}
void Point_move(struct Point* this, int dx, int dy) {
this->x += dx;
this->y += dy;
}
void Point_dtor(struct Point* this) {}Константность метода регулировалась константностью указателя this.
Если есть класс, значит должно быть использование:
void foo() {
Point p = Point(1, 2);
p.move(2, 3);
printf("%d/n", p.get_x());
}Этот код превращался в нечто подобное:
void foo() {
struct Point p;
Point_ctor(&p, 1, 2);
Point_move(&p, 2, 3);
printf("%d/n", Point_get_x(&p));
Point_dtor(&p);
}Заметьте, что в конце любого скоупа, в котором был создан объект компилятором вставлялся вызов деструктора, тем самым обеспечивая идиому RAII.
Have a legacy. Stay cool.
#cppcore #goodoldc #compiler
4❤37👍12🔥12
Наследие Cfront. Наследование
#новичкам
Сорри за тавталогию, но мимо этой темы мы не можем пройти(хотя я бы прошел, если бы не @shumilkinad, спасибо ему)
В раннем С++ уже были классы и наследование, но в С этого не было. Как же можно транслировать наследование классов в С'шный код?
Простая агрегация и никакого мошенничества.
Все классы в С++ - это простые С-структуры с отдельным набором функций, принимающих cv-специфицированный указатель на инстанс структуры(это мы выяснили в прошлом посте). Наследники же в начале объекта хранят все поля базового класса. Так давайте просто первым полем наследника сделаем инстанс базовой структуры. Таким образом мы обеспечим вложенность объектов с любым количеством наследований.
Вот есть пара родитель-наследник:
Примерно в такой код они транслировались:
Первым полем структуры Derived - структура Base.
Конструкторы же - это отдельные функции. Но в С++ очень важен порядок вызовов конструкторов и деструкторов.
Поэтому конструктор самого базового класса только инициализирует свои поля и дальше выполняет инструкции из тела конструктора. При создании же наследников в начале вызывается конструктор базового класса и лишь потом инициализация полей и выполнение тела.
Разрушение же объекта выполняется в обратном порядке. Трусы снимаются только после штанов, раньше не получится.
Превращается в:
Новичкам особенно будет полезно понимать, как простой код С++ может быть написан на С, чтобы досканально понимать все абстракции языка и какие действия скрыты от наших глаз.
Have a legacy. Stay cool.
#cppcore #goodoldc #compiler
#новичкам
Сорри за тавталогию, но мимо этой темы мы не можем пройти(хотя я бы прошел, если бы не @shumilkinad, спасибо ему)
В раннем С++ уже были классы и наследование, но в С этого не было. Как же можно транслировать наследование классов в С'шный код?
Простая агрегация и никакого мошенничества.
Все классы в С++ - это простые С-структуры с отдельным набором функций, принимающих cv-специфицированный указатель на инстанс структуры(это мы выяснили в прошлом посте). Наследники же в начале объекта хранят все поля базового класса. Так давайте просто первым полем наследника сделаем инстанс базовой структуры. Таким образом мы обеспечим вложенность объектов с любым количеством наследований.
Вот есть пара родитель-наследник:
class Base {
public:
int x;
Base(int a) : x(a) {}
};
class Derived : public Base {
public:
int y;
int z;
Derived(int a, int b) : Base(a), y(b) {
z = x + y;
}
};Примерно в такой код они транслировались:
struct Base {
int x;
};
struct Derived {
struct Base _base; // embedded base object
int y;
int z;
};
void Base_constructor(struct Base* this, int a) {
this->x = a;
// Constructor body (if presented)
}
void Derived_constructor(struct Derived* this, int a, int b) {
// Init base object
Base_constructor(&this->_base, a);
// Init fields of derived object
this->y = b;
// Constructor body
this->z = this->_base.x + this->y;
}Первым полем структуры Derived - структура Base.
Конструкторы же - это отдельные функции. Но в С++ очень важен порядок вызовов конструкторов и деструкторов.
Поэтому конструктор самого базового класса только инициализирует свои поля и дальше выполняет инструкции из тела конструктора. При создании же наследников в начале вызывается конструктор базового класса и лишь потом инициализация полей и выполнение тела.
Разрушение же объекта выполняется в обратном порядке. Трусы снимаются только после штанов, раньше не получится.
class Base {
public:
~Base() {
// Destructor Base body
}
};
class Derived : public Base {
public:
~Derived() {
// Destructor Derived body
}
}Превращается в:
struct Base {
};
struct Derived {
struct Base _base;
};
void Base_destructor(struct Base* this) {
// Destructor Base body
}
void Derived_destructor(struct Derived* this) {
// Destructors execute in reverse order
// Destructor Derived body
Base_destructor(&this->_base);
}Новичкам особенно будет полезно понимать, как простой код С++ может быть написан на С, чтобы досканально понимать все абстракции языка и какие действия скрыты от наших глаз.
Have a legacy. Stay cool.
#cppcore #goodoldc #compiler
5👍33❤13🔥12
Наследие Cfront. Полиморфизм
#новичкам
Часто мы говорим о каких-то вещах в С++ и можем сказать, как они работают под капотом. Но стандарт языка не говорит о том, как компиляторы должны реализовывать те или иные фичи. Он только задает требование. Тем не менее подходы к реализации некоторых фичей повторяются в разных компиляторах. И отчасти это так из-за влияния Cfront.
В С++ классический динамический полиморфизм подтипов синтаксически реализуется через виртуальные функции.
Мы более подробно разбирали полиморфизм в одном из предыдущих постов. Сейчас мы поговорим, как примерно Cfront преобразовывал этот С++ код в С код.
Основные идеи:
1️⃣ Для каждого полиморфного класса формируется статическая таблица виртуальных функций. Это по сути массив указателей на виртуальные "методы" класса, которые Cfront представлял в виде обычных функций. Порядок методов в таблице определялся порядком их объявления в классе.
2️⃣ Нужно каким-то образом связать таблицу для класса с объектом этого класса. Для этого использовалось неявное дополнительное поле класса - указатель на таблицу виртуальных функций или vptr.
Вот как Cfront преобразовывал код выше(примерно, детали могут отличаться):
В самом первом базовом классе появлялся указатель vptr, который в конструкторе инициализируется правильным адресом нужной таблицы. void (**vptr)() - это тип указателя на указатель на функцию, возвращающую void и не принимающую аргументов.
Но погодите, виртуальные методы как минимум принимают один неявный аргумент this, а как максимум могут самые разнообразные сигнатуры иметь. Почему указатель имеет такой тип?
Ну а как вы еще засунете в один массив разные функции? Их кастили к одному общему типу void(*)(), только так это было возможно:
Cfront генерировал Сишные реализации методов и клал их в массив, попутно приводя к типу void(*)().
Ну а в месте вызова метода компилятору ничего не мешает сделать каст к нужному типу, так как он знает сигнатуру вызываемого метода:
В те времена С не был стандартизирован и правила преобразования типов были несколько мягче, поэтому такая магия с приведениями работала.
В наше время не нужна трансляция С++ в С, но тем не менее концепция таблиц виртуальных функций и указателей на них осталась.
Have a legacy. Stay cool
#cppcore #goodoldc #compiler
#новичкам
Часто мы говорим о каких-то вещах в С++ и можем сказать, как они работают под капотом. Но стандарт языка не говорит о том, как компиляторы должны реализовывать те или иные фичи. Он только задает требование. Тем не менее подходы к реализации некоторых фичей повторяются в разных компиляторах. И отчасти это так из-за влияния Cfront.
В С++ классический динамический полиморфизм подтипов синтаксически реализуется через виртуальные функции.
class Person {
protected:
std::string name;
int age;
public:
Person(const std::string &n, int a) : name(n), age(a) {}
virtual void describe() const {
std::cout << name << " (" << age << " years)";
}
virtual ~Person() = default;
};
class Employee : public Person {
std::string position;
public:
Employee(const std::string &n, int a, const std::string &pos)
: Person(n, a), position(pos) {}
void describe() const override {
std::cout << name << " (" << age << " years) - " << position;
}
~Employee() override = default;
};Мы более подробно разбирали полиморфизм в одном из предыдущих постов. Сейчас мы поговорим, как примерно Cfront преобразовывал этот С++ код в С код.
Основные идеи:
1️⃣ Для каждого полиморфного класса формируется статическая таблица виртуальных функций. Это по сути массив указателей на виртуальные "методы" класса, которые Cfront представлял в виде обычных функций. Порядок методов в таблице определялся порядком их объявления в классе.
2️⃣ Нужно каким-то образом связать таблицу для класса с объектом этого класса. Для этого использовалось неявное дополнительное поле класса - указатель на таблицу виртуальных функций или vptr.
Вот как Cfront преобразовывал код выше(примерно, детали могут отличаться):
struct Person {
// pointer to vtable
void (**vptr)();
struct string name;
int age;
};
struct Employee {
struct Person base;
struct string position;
};В самом первом базовом классе появлялся указатель vptr, который в конструкторе инициализируется правильным адресом нужной таблицы. void (**vptr)() - это тип указателя на указатель на функцию, возвращающую void и не принимающую аргументов.
Но погодите, виртуальные методы как минимум принимают один неявный аргумент this, а как максимум могут самые разнообразные сигнатуры иметь. Почему указатель имеет такой тип?
Ну а как вы еще засунете в один массив разные функции? Их кастили к одному общему типу void(*)(), только так это было возможно:
void (*Person_vtable[])() = {
(void(*)())Person_describe_impl,
(void(*)())Person_dtor
};
void (*Employee_vtable[])() = {
(void(*)())Employee_describe_impl,
(void(*)())Employee_dtor
};
void Person_describe_impl(const struct Person* this) {
printf("%s (%d years)", this->name, this->age);
}
void Person_dtor(struct Person* this) {
String_dtor(this->name);
}
void Employee_describe_impl(const struct Person* this) {
// cast to proper type
const struct Employee* emp = (const struct Employee*)this;
printf("%s (%d years) - %s", emp->base.name, emp->base.age, emp->position);
}
void Person_dtor(struct Person* this) {
String_dtor(this->position);
Person_dtor(this->base);
}
Cfront генерировал Сишные реализации методов и клал их в массив, попутно приводя к типу void(*)().
Ну а в месте вызова метода компилятору ничего не мешает сделать каст к нужному типу, так как он знает сигнатуру вызываемого метода:
void print_info(const Person* person) {
person->describe();
}void print_info(const struct Person* person) {
void (*describe_func)(const struct Person*) =
(void (*)(const struct Person*))person->vptr[0];
describe_func(person);
}В те времена С не был стандартизирован и правила преобразования типов были несколько мягче, поэтому такая магия с приведениями работала.
В наше время не нужна трансляция С++ в С, но тем не менее концепция таблиц виртуальных функций и указателей на них осталась.
Have a legacy. Stay cool
#cppcore #goodoldc #compiler
👍23🔥15❤9
Современные таблицы виртуальных функций
#опытным
С++ давно ушел от компиляции в С. Но таблицы виртуальных функций, как средство реализации динамического полиморфизма, остались в компиляторах.
Как устроены vtables сейчас, когда С++ напрямую компилируется в ассемблер?
Идея все та же:
👉🏿 На каждый полиморфный класс создается своя vtable
👉🏿 Она представляет собой просто массив адресов. В ассемблере адреса нетипизированные, поэтому они просто лежат там чиселками.
👉🏿 В каждом объекте хранится vptr - указатель на эту таблицу.
👉🏿 vtpr инициализируется в самом базовом классе его адресом его vtable и затем каждый конструктор наследника присваивает в него адрес своей таблицы
Реализации вносят свои особенности, но это ядро остается неизменным.
Вот примерчик(можете смотреть на годболте):
Будем сейчас разбирать gcc-шный асм.
Вот так выглядят таблицы для обоих классов:
quad - это 64-битное число. Видно, что таблицы - это статические массивы.
Первым числом у них является offset to top, это число нужно для корректной работы множественного наследования, не будем вдаваться в детали.
Второй число - адрес расположения информации о динамическом типе(RTTI) объекта. Эта информация нужна, например, для dynamic_cast'а.
Дальше расположены адреса виртуальных функций нужных классов. Заметьте, что адреса расположены в порядке объявления виртуального метода в классе. Если в дочернем классе переопределяется метод, то в его vtable указатель родительского метода заменяется на переопределенный(методы
В конструкторе Employee происходит такое:
Вызывается конструктор базового класса и сразу же после этого переприсваивается vptr на таблицу класса Employee.
Ну а виртуальный вызов выглядит просто как call нужного адреса:
#опытным
С++ давно ушел от компиляции в С. Но таблицы виртуальных функций, как средство реализации динамического полиморфизма, остались в компиляторах.
Как устроены vtables сейчас, когда С++ напрямую компилируется в ассемблер?
Идея все та же:
👉🏿 На каждый полиморфный класс создается своя vtable
👉🏿 Она представляет собой просто массив адресов. В ассемблере адреса нетипизированные, поэтому они просто лежат там чиселками.
👉🏿 В каждом объекте хранится vptr - указатель на эту таблицу.
👉🏿 vtpr инициализируется в самом базовом классе его адресом его vtable и затем каждый конструктор наследника присваивает в него адрес своей таблицы
Реализации вносят свои особенности, но это ядро остается неизменным.
Вот примерчик(можете смотреть на годболте):
class Person {
protected:
std::string name;
int age;
public:
Person(const std::string &n, int a) : name(n), age(a) {}
virtual std::string getRole() const { return "Person"; }
virtual std::string getName() const { return name; }
virtual void describe() const {
std::cout << name << " (" << age << " years)";
}
virtual ~Person() = default;
};
class Employee : public Person {
std::string position;
public:
Employee(const std::string &n, int a, const std::string &pos)
: Person(n, a), position(pos) {}
std::string getRole() const override { return "Employee"; }
void describe() const override {
std::cout << name << " (" << age << " years) - " << position;
}
};
int main() {
Person * p = new Employee("Steven", 42, "CEO");
p->describe();
std::cout << p->getName() << std::endl;
}Будем сейчас разбирать gcc-шный асм.
Вот так выглядят таблицы для обоих классов:
vtable for Person:
.quad 0
.quad typeinfo for Person
.quad Person::getRoleabi:cxx11 const
.quad Person::getNameabi:cxx11 const
.quad Person::describe() const
.quad Person::~Person()
vtable for Employee:
.quad 0
.quad typeinfo for Employee
.quad Employee::getRoleabi:cxx11 const
.quad Person::getNameabi:cxx11 const
.quad Employee::describe() const
.quad Employee::~Employee()
quad - это 64-битное число. Видно, что таблицы - это статические массивы.
Первым числом у них является offset to top, это число нужно для корректной работы множественного наследования, не будем вдаваться в детали.
Второй число - адрес расположения информации о динамическом типе(RTTI) объекта. Эта информация нужна, например, для dynamic_cast'а.
Дальше расположены адреса виртуальных функций нужных классов. Заметьте, что адреса расположены в порядке объявления виртуального метода в классе. Если в дочернем классе переопределяется метод, то в его vtable указатель родительского метода заменяется на переопределенный(методы
getRole и describe). Если наследник не переопределяет метод, то в таблице остается указатель на родительский метод(getName).В конструкторе Employee происходит такое:
; Сначала вызывается конструктор Person (устанавливает vptr Person)
call Person::Person(...) [base object constructor]
; Затем перезаписывается vptr на таблицу Employee
mov edx, OFFSET FLAT:vtable for Employee+16
mov rax, QWORD PTR [rbp-24]
mov QWORD PTR [rax], rdx
Вызывается конструктор базового класса и сразу же после этого переприсваивается vptr на таблицу класса Employee.
Ну а виртуальный вызов выглядит просто как call нужного адреса:
mov rax, QWORD PTR [rbp-40] ; Загружаем указатель p
mov rax, QWORD PTR [rax] ; Загружаем vptr (указывает на vtable+16)
add rax, 16 ; Смещаемся к 4-му слоту (describe)
mov rdx, QWORD PTR [rax] ; Загружаем адрес функции describe
mov rax, QWORD PTR [rbp-40] ; Загружаем this (указатель p)
mov rdi, rax ; Передаем this как первый параметр
call rdx ; Виртуальный вызов describe
❤🔥22❤11👍6🔥6😁1
Компилятору достаточно лишь правильно положить аргументы функции в правильные регистры, согласно calling conventions. Какие аргументы нужно подготовить компилятор знает заранее, так как сигнатура виртуальных методов одинакова для всех переопределенных вариантов. Остается лишь call'ьнуть нужный указатель и происходит виртуальный вызов.
Подкапотоное устройство полиморфизма часто спрашивают на собесах. Теперь вы знаете, как отвечать почти на полный спектр вопросов по этой теме.
Know whats under the hood. Stay cool.
#compiler #cppcore
Подкапотоное устройство полиморфизма часто спрашивают на собесах. Теперь вы знаете, как отвечать почти на полный спектр вопросов по этой теме.
Know whats under the hood. Stay cool.
#compiler #cppcore
❤24👍14🔥9
Наследие Cfront. Манглирование
#новичкам
В С нет перегрузки функций, поэтому там люди вынуждены каким-то образом руками разделять имена функций.
Вместо
Там пишут:
Плюс линкеры работают с именами символов. А имя функции в С не включает в себя параметры. Поэтому во всей программе не может быть двух функций с одинаковыми именами. Линкер их банально не различит и выдаст ошибку множественного определения.
А в С++ была перегрузка и надо было каким-то образом плюсовые перегруженные функции превращать в неперегруженные сишные при трансляции кода. Для этого было придумано декорирование имен или name mangling.
Самый простой способ - добавлять к конце функции ее параметры в закодированном виде: ИмяФункции_ТипыПараметров:
Так как у нас не может быть двух перегрузок с разными возвращаемыми значениями, то кодирование типа возврата не нужно.
Но это самое базовое представление о декорировании имен. Давайте посмотрим, что еще может влиять на итоговое имя функции:
👉🏿 2 разных класса могут иметь методы с одинаковым названием. Так как при трансляции в С это были просто свободные функции, манглинг должен учитывать и имя класса:
👉🏿 Есть же еще и пространства имен. Они помогают разграничить скоуп существования имен. И названия пространства имен тоже манглировались в имена функций:
👉🏿 В С++ когда-то появились шаблоны. Шаблон всегда инстанцируется с каким-то типом. И чтобы различать эти инстанциации, Cfront манглировал типы шаблонных параметров в полное имя типа:
Конкретные преобразованные имена из поста могут быть не такими, какими их генерировал Cfront, но главное уловить идею.
В современных компиляторах тоже делается манглинг имен, чтобы линкер не ругался на одинаковые символы:
Шаблоны, неймспейсы, noexcept и const квалификаторы - все вшивается в имя символа.
Вы также можете вручную управлять манглингом: включать и выключать его:
Это нужно для совместимости ABI интерфейсов, предоставляемых библиотеками.
Поэтому декорирование имен живее всех живых и повсеместно используется в современных компиляторах.
Have a legacy. Stay cool
#cppcore #goodoldc #compiler
#новичкам
В С нет перегрузки функций, поэтому там люди вынуждены каким-то образом руками разделять имена функций.
Вместо
void print(int x);
void print(float x);
Там пишут:
void print_int(int x);
void print_float(float x);
Плюс линкеры работают с именами символов. А имя функции в С не включает в себя параметры. Поэтому во всей программе не может быть двух функций с одинаковыми именами. Линкер их банально не различит и выдаст ошибку множественного определения.
А в С++ была перегрузка и надо было каким-то образом плюсовые перегруженные функции превращать в неперегруженные сишные при трансляции кода. Для этого было придумано декорирование имен или name mangling.
Самый простой способ - добавлять к конце функции ее параметры в закодированном виде: ИмяФункции_ТипыПараметров:
void draw(int x, int y);
void draw(double x, double y);
// Cfront mangling:
draw_i_i // draw(int, int)
draw_d_d // draw(double, double)
Так как у нас не может быть двух перегрузок с разными возвращаемыми значениями, то кодирование типа возврата не нужно.
Но это самое базовое представление о декорировании имен. Давайте посмотрим, что еще может влиять на итоговое имя функции:
👉🏿 2 разных класса могут иметь методы с одинаковым названием. Так как при трансляции в С это были просто свободные функции, манглинг должен учитывать и имя класса:
void Circle::paint(Color c);
void Square::paint();
Rectangle::~Rectangle();
Shape::~Shape();
// transform into
void Circle_paint_Color(struct Circle* this, struct Color c);
void Square_paint(struct Square* this);
void Rectangle_dtor(struct Rectangle* this);
void Shape_dtor(struct Shape* this);
👉🏿 Есть же еще и пространства имен. Они помогают разграничить скоуп существования имен. И названия пространства имен тоже манглировались в имена функций:
namespace Graphics {
class Canvas {
void clear();
};
}
// transform into
void Graphics_Canvas_clear(struct Canvas* this)👉🏿 В С++ когда-то появились шаблоны. Шаблон всегда инстанцируется с каким-то типом. И чтобы различать эти инстанциации, Cfront манглировал типы шаблонных параметров в полное имя типа:
template<typename T>
class Stack {
void push(T value);
};
Stack<int> stack;
// transforms into
Stack_int_push_i(int value);
Конкретные преобразованные имена из поста могут быть не такими, какими их генерировал Cfront, но главное уловить идею.
В современных компиляторах тоже делается манглинг имен, чтобы линкер не ругался на одинаковые символы:
void Circle::rotate(int);
// transforms into
_ZN6Circle6rotateEi
// Разбор:
_Z - префикс C++
N - вложенное имя
6Circle - длина=6, "Circle"
6rotate - длина=6, "rotate"
E - конец аргументов
i - тип int
Шаблоны, неймспейсы, noexcept и const квалификаторы - все вшивается в имя символа.
Вы также можете вручную управлять манглингом: включать и выключать его:
extern "C" void c_function(); // Без манглинга: _c_function
extern "C++" void cpp_function(); // С манглингом: _Z10cpp_functionv
Это нужно для совместимости ABI интерфейсов, предоставляемых библиотеками.
Поэтому декорирование имен живее всех живых и повсеместно используется в современных компиляторах.
Have a legacy. Stay cool
#cppcore #goodoldc #compiler
❤22👍21🔥13
Новый год
Вот и подходит к своему завершению 2025 год.
Самое время подвести его итоги. Но я не буду перечислять список полезных или популярных постов. Кто захочет, то найдет. Я хочу поделиться состоянием(вайбом для зумеров) от завершающего свой последний аккорд года.
⚡️ Меня радует, что качество постов наконец-то меня удовлетворяет. Не по обертке(всегда бывают косяки), а по сути, структурированности и целостности. Можете ради интереса вернуться к первым постам и проследить эволюцию стиля. Количество юморесок и степень свободы изложения заметно сократились в угоду системности. Это логичная проф деформация, когда каждый раз при написании постов делаешь инъекцию 3-х кубиков стандарта внутривенно. Это несомненно позитивные изменения. Но теперь хочется, чтобы маятник вновь качнулся в сторону развлекательного аспекта. Все-таки мы здесь покекать пришли, а не плюсы учить. Или у вас не так?)
⚡️ Канал свел меня с прекрасными людьми, с которыми у нас началось сотрудничество по части плюсов и не только. Я очень вырос благодаря этим связям и не могу наудивляться, насколько у нас здесь клевые ребята собрались.
⚡️ Очень радует, что подписчики все чаще предлагают какие-то идеи для постов, особенно лично. Благодаря некоторым появились даже целые рубрики. Видно, что наше коммьюнити живое и активно развивается. У нас можно и поболтать за жизнь, и похоливарить на тему языков, и узнать что-то новенькое от крутых спецов. Есть более профессиональные чаты для гурманов и заядлых сомелье С++, но мне кажется, что определенную нишу мы заняли.
У меня это был эпический год по всем направлениям в жизни. Накопилась большая усталось, но при этом на лице улыбка.
И хочу вам сказать большое спасибо. Всем и каждому. Именно благодаря вам я расту и развиваюсь. Благодаря вам куча людей в принципе может регулярно получать небольшую порцию любимого С++ к обеду. Надеюсь, что канал вам нравится и вы находите его полезным. Без вас ничего этого не было бы.
Желаю вам в будущем году плотно и потно трудиться. Легко не будет, особенно начинающим, но у вас все получится. Идите к своим целям на всех парах. Верю в вас всех и каждого.
С Новым годом, друзья! С новым счастьем!☃️🎊🎉🎄
Вот и подходит к своему завершению 2025 год.
Самое время подвести его итоги. Но я не буду перечислять список полезных или популярных постов. Кто захочет, то найдет. Я хочу поделиться состоянием(вайбом для зумеров) от завершающего свой последний аккорд года.
⚡️ Меня радует, что качество постов наконец-то меня удовлетворяет. Не по обертке(всегда бывают косяки), а по сути, структурированности и целостности. Можете ради интереса вернуться к первым постам и проследить эволюцию стиля. Количество юморесок и степень свободы изложения заметно сократились в угоду системности. Это логичная проф деформация, когда каждый раз при написании постов делаешь инъекцию 3-х кубиков стандарта внутривенно. Это несомненно позитивные изменения. Но теперь хочется, чтобы маятник вновь качнулся в сторону развлекательного аспекта. Все-таки мы здесь покекать пришли, а не плюсы учить. Или у вас не так?)
⚡️ Канал свел меня с прекрасными людьми, с которыми у нас началось сотрудничество по части плюсов и не только. Я очень вырос благодаря этим связям и не могу наудивляться, насколько у нас здесь клевые ребята собрались.
⚡️ Очень радует, что подписчики все чаще предлагают какие-то идеи для постов, особенно лично. Благодаря некоторым появились даже целые рубрики. Видно, что наше коммьюнити живое и активно развивается. У нас можно и поболтать за жизнь, и похоливарить на тему языков, и узнать что-то новенькое от крутых спецов. Есть более профессиональные чаты для гурманов и заядлых сомелье С++, но мне кажется, что определенную нишу мы заняли.
У меня это был эпический год по всем направлениям в жизни. Накопилась большая усталось, но при этом на лице улыбка.
И хочу вам сказать большое спасибо. Всем и каждому. Именно благодаря вам я расту и развиваюсь. Благодаря вам куча людей в принципе может регулярно получать небольшую порцию любимого С++ к обеду. Надеюсь, что канал вам нравится и вы находите его полезным. Без вас ничего этого не было бы.
Желаю вам в будущем году плотно и потно трудиться. Легко не будет, особенно начинающим, но у вас все получится. Идите к своим целям на всех парах. Верю в вас всех и каждого.
С Новым годом, друзья! С новым счастьем!☃️🎊🎉🎄
23❤92🎄22👍16☃13❤🔥3👎1🗿1
Праздник Баг к нам приходит
Врываемся в новый год с поучительных историй.
На дворе 31 декабря 2к21 года. В России все нарезают салаты, готовятся веселиться и еще не знают, какой год их ждет впереди. На западе тоже все еще празднуют, хотя Рождество уже позади.
В первые минуты января сверкает салют, хлопаются хлопушки, шампанское переливается через края бокалов и перестает доставляться вся электронная почта, за обработку и доставку которой отвечал Microsoft Exchange Server.
Вот так в одну секунду по всему миру куча организаций перестала получать свою почту. В журнале событий сервера можно было найти такую запись: «Процесс сканирования FIP-FS Scan Process не прошел инициализацию. Ошибка: 0x8004005. Подробности ошибки: «Неопределенная ошибка» или «Код ошибки: 0x80004005». Описание ошибки: «Не удается преобразовать "2201010001" в длинное число».
Оказывается, что Exchange сохранял в журнале проверок антивируса даты в виде int32. Максимальным значением может быть 2147483647. У числа может быть всего 10 десятичных разрядов: первые 2 числа - последние 2 цифры года, дальше month/day/time. Для 2021 все было ок. Но чтобы представить первую секунду 2022 года нужно число 2201010001. А это уже перебор. Конвертация навернулась и полетели ошибки.
Эту проблему тогда обозвали Y2K22 bug, по аналогии с багом 2000 года(Y2K). В 20-м веке люди тоже часто обрабатывали только последние 2 цифры даты и в момент миллениума года сбрасывались просто до нуля.
Стоит ли говорить, что малварьный модель FIP-FS был скорее всего написан на С/C++?
Но не в этом дело. Если какой-то программист решил применить свою уникальную оптимизацию и не подумал чуть наперед, то здесь любым языком можно пакостей.
Вообще, ошибки связаные с переходом на новый год, не так уж и редки. У меня на проекте тоже был такой баг. Так что будьте внимательны при работе со временем. Хардкод и обрезание дат играют злую шутку.
А вы сталкивались с подобными ошибками? Расскажите в комментах.
Celebrate the holiday. Stay cool.
#fun
Врываемся в новый год с поучительных историй.
На дворе 31 декабря 2к21 года. В России все нарезают салаты, готовятся веселиться и еще не знают, какой год их ждет впереди. На западе тоже все еще празднуют, хотя Рождество уже позади.
В первые минуты января сверкает салют, хлопаются хлопушки, шампанское переливается через края бокалов и перестает доставляться вся электронная почта, за обработку и доставку которой отвечал Microsoft Exchange Server.
Вот так в одну секунду по всему миру куча организаций перестала получать свою почту. В журнале событий сервера можно было найти такую запись: «Процесс сканирования FIP-FS Scan Process не прошел инициализацию. Ошибка: 0x8004005. Подробности ошибки: «Неопределенная ошибка» или «Код ошибки: 0x80004005». Описание ошибки: «Не удается преобразовать "2201010001" в длинное число».
Оказывается, что Exchange сохранял в журнале проверок антивируса даты в виде int32. Максимальным значением может быть 2147483647. У числа может быть всего 10 десятичных разрядов: первые 2 числа - последние 2 цифры года, дальше month/day/time. Для 2021 все было ок. Но чтобы представить первую секунду 2022 года нужно число 2201010001. А это уже перебор. Конвертация навернулась и полетели ошибки.
Эту проблему тогда обозвали Y2K22 bug, по аналогии с багом 2000 года(Y2K). В 20-м веке люди тоже часто обрабатывали только последние 2 цифры даты и в момент миллениума года сбрасывались просто до нуля.
Стоит ли говорить, что малварьный модель FIP-FS был скорее всего написан на С/C++?
Но не в этом дело. Если какой-то программист решил применить свою уникальную оптимизацию и не подумал чуть наперед, то здесь любым языком можно пакостей.
Вообще, ошибки связаные с переходом на новый год, не так уж и редки. У меня на проекте тоже был такой баг. Так что будьте внимательны при работе со временем. Хардкод и обрезание дат играют злую шутку.
А вы сталкивались с подобными ошибками? Расскажите в комментах.
Celebrate the holiday. Stay cool.
#fun
👍23❤10🔥6😁4🫡3
Наследие Cfront. Компоновка
#новичкам
Продолжаем серию постов с прошлого года. Для тех, кто не в теме: пост про Cfront тут, начало серии тут.
С++ оказывал влияние не только на компиляторы, но и на линковщики.
Если в первых версиях языка и компилятора Cfront Бьерн сфокусировался на ООП и полиморфизме, то дальше были введены шаблоны и inline функции.
Шаблоны и inline функции просто исходя из своей механики работы предполагают то, что конкретные инстанциации и определения inline функций могут находиться в нескольких единицах трансляции в рамках одной программы.
Но в С был и есть One Definition Rule, который запрещал иметь более одного определения сущности в рамках одной программы.
Поначалу для решения этой проблемы использовались разные хаки: от макросов и магии с именами до ручной инстанциации шаблонов в одном cpp файле.
Это конечно было неудобно, но благо С++ становился все более популярным и влиятельным. Поэтому команда Cfront начала активно взаимодействовать с разработчиками линковщиков для того, чтобы ввести так поддержку слабых символов. Их в программе может быть сколько угодно, линковщик выберет один любой из них и будет ссылать на этот символ все заглушки. Главное, чтобы все определения символа были одинаковыми, иначе UB.
Также в С++ появились глобальные объекты. А глобальные объекты требуют своей инициализации (то есть выполнения кода) до main. В сижке такого нет, там исполнение пользовательского кода начинается с вызова main. Кстати поэтому в С нет SIOF.
Поэтому приходилось извращаться. Формировать массив конструкторов глобальных объектов и вызывать его первой инструкцией main. Разрушение происходило в конце main с помощью массива деструкторов.
Но это костыль и нужно было нормальное решение. Результатом совместной работы Cfront и линковщиков стали секции .ctors/.dtors в объектных и бинарных файлах. Там находятся информация о том, какие глобальные пользовательские объекты есть в коде. Код конструкторов и деструкторов объектов из этих секций выполняется до и после main соответственно.
Таким было наследие Cfront. The end.
Have a legacy. Stay cool.
#compiler
#новичкам
Продолжаем серию постов с прошлого года. Для тех, кто не в теме: пост про Cfront тут, начало серии тут.
С++ оказывал влияние не только на компиляторы, но и на линковщики.
Если в первых версиях языка и компилятора Cfront Бьерн сфокусировался на ООП и полиморфизме, то дальше были введены шаблоны и inline функции.
Шаблоны и inline функции просто исходя из своей механики работы предполагают то, что конкретные инстанциации и определения inline функций могут находиться в нескольких единицах трансляции в рамках одной программы.
Но в С был и есть One Definition Rule, который запрещал иметь более одного определения сущности в рамках одной программы.
Поначалу для решения этой проблемы использовались разные хаки: от макросов и магии с именами до ручной инстанциации шаблонов в одном cpp файле.
Это конечно было неудобно, но благо С++ становился все более популярным и влиятельным. Поэтому команда Cfront начала активно взаимодействовать с разработчиками линковщиков для того, чтобы ввести так поддержку слабых символов. Их в программе может быть сколько угодно, линковщик выберет один любой из них и будет ссылать на этот символ все заглушки. Главное, чтобы все определения символа были одинаковыми, иначе UB.
Также в С++ появились глобальные объекты. А глобальные объекты требуют своей инициализации (то есть выполнения кода) до main. В сижке такого нет, там исполнение пользовательского кода начинается с вызова main. Кстати поэтому в С нет SIOF.
Поэтому приходилось извращаться. Формировать массив конструкторов глобальных объектов и вызывать его первой инструкцией main. Разрушение происходило в конце main с помощью массива деструкторов.
Но это костыль и нужно было нормальное решение. Результатом совместной работы Cfront и линковщиков стали секции .ctors/.dtors в объектных и бинарных файлах. Там находятся информация о том, какие глобальные пользовательские объекты есть в коде. Код конструкторов и деструкторов объектов из этих секций выполняется до и после main соответственно.
Таким было наследие Cfront. The end.
Have a legacy. Stay cool.
#compiler
👍27🔥11❤8