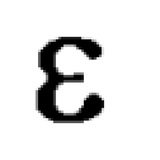
Оказалось что вводный пример этого фрейма является адаптированной главой из не менее очешуительной книги под названием Statistical Rethinking. Только вот не задача данный пример был из 7 главы книги... После этого стало сразу понятно почему же ничего не понятно.
Поэтому я начал читать Statistical Rethinking. Это оказалось тем что я так долго желал от статистики - работа с данными и распределениями. Автор максимально понятным и в тоже время строгим языком рассказывает про то как на основе условных данных о подбрасывании монетки составить его постериальное распределение или другими словами как создать функцию распределения из имеющегося набора данных.
Причем он с первой же главы начинает прям жестить(в хорошем смысле) и показывает как можно получить приблеженное распределение при помощи 3 методов: grid approximation, quadratic approximation и markov chain Monte Carlo (MCMC). И самое офигенное что он показывает все эти алгоритмы в коде, а не вываливает на тебя кучу формул говоря Ну ЭтО Жи АчИвИдНААА.
На данный момент я прочитал до 3 главы(в 3 главе осталось сделать упражнения, которые тоже нужно решить в коде). Не скажу что я понимаю на данный момент прямо все что там написано, но я прямо чувствую как начинаю понимать как приложить даже эту простую теорию в том же самом NLP или CV.
Также из этого списка я начал проходить matrix algebra for engineers. По первой неделе могу сказать что это очень хороший курс по введению в линал, так как уже после первой недели некоторые концепции сильно помогли мне при написании Sentence-Transformera. А также я имею довольно болезненный опыт ее изучения. Ранее я пытался проходить Introduction to Linear Algebra 5th Edition [2016] Gilbert Strang, я смог дочитать ее и проделать задания только до 135 страницы, благодаря этой книге например можно понять почему dot product нормированных векторов дает угол между ними. Но хочу отметить что matrix algebra for engineers также дает самое понятное представление о том почему же матрица поворота работает.
Напоследок приведу общую статистику сколько времени я на данный момент потратил за неделю на изучение данных штук
pyro - 90 min
matrix algebra for engineers - 225 min
statistical-rethinking - 385 min
Если остались выжившие до этого момента хочу пригласить вас в паблик в телеграм, я наконец решился. Вк дико неудобный для этого, кто знает может я полностью перееду туда
Поэтому я начал читать Statistical Rethinking. Это оказалось тем что я так долго желал от статистики - работа с данными и распределениями. Автор максимально понятным и в тоже время строгим языком рассказывает про то как на основе условных данных о подбрасывании монетки составить его постериальное распределение или другими словами как создать функцию распределения из имеющегося набора данных.
Причем он с первой же главы начинает прям жестить(в хорошем смысле) и показывает как можно получить приблеженное распределение при помощи 3 методов: grid approximation, quadratic approximation и markov chain Monte Carlo (MCMC). И самое офигенное что он показывает все эти алгоритмы в коде, а не вываливает на тебя кучу формул говоря Ну ЭтО Жи АчИвИдНААА.
На данный момент я прочитал до 3 главы(в 3 главе осталось сделать упражнения, которые тоже нужно решить в коде). Не скажу что я понимаю на данный момент прямо все что там написано, но я прямо чувствую как начинаю понимать как приложить даже эту простую теорию в том же самом NLP или CV.
Также из этого списка я начал проходить matrix algebra for engineers. По первой неделе могу сказать что это очень хороший курс по введению в линал, так как уже после первой недели некоторые концепции сильно помогли мне при написании Sentence-Transformera. А также я имею довольно болезненный опыт ее изучения. Ранее я пытался проходить Introduction to Linear Algebra 5th Edition [2016] Gilbert Strang, я смог дочитать ее и проделать задания только до 135 страницы, благодаря этой книге например можно понять почему dot product нормированных векторов дает угол между ними. Но хочу отметить что matrix algebra for engineers также дает самое понятное представление о том почему же матрица поворота работает.
Напоследок приведу общую статистику сколько времени я на данный момент потратил за неделю на изучение данных штук
pyro - 90 min
matrix algebra for engineers - 225 min
statistical-rethinking - 385 min
Если остались выжившие до этого момента хочу пригласить вас в паблик в телеграм, я наконец решился. Вк дико неудобный для этого, кто знает может я полностью перееду туда
🥴1
Я тут обнаружил что моя любимая электронная библиотечка прикрылась. FBI так сказать постарались.
Поэтому сейчас получить к ней доступ можно только через tor браузер, хотя у меня предчувствие что это надолго(если не навсегда).
Поэтому качаем tor браузер по этой ссылке https://www.torproject.org/
Переходим по этой ссылке https://ru.singlelogin.me/ и находим там onion ссылку для tor браузера. на данный момент она такая http://bookszlibb74ugqojhzhg2a63w5i2atv5bqarulgczawnbmsb6s6qead.onion/
Поэтому сейчас получить к ней доступ можно только через tor браузер, хотя у меня предчувствие что это надолго(если не навсегда).
Поэтому качаем tor браузер по этой ссылке https://www.torproject.org/
Переходим по этой ссылке https://ru.singlelogin.me/ и находим там onion ссылку для tor браузера. на данный момент она такая http://bookszlibb74ugqojhzhg2a63w5i2atv5bqarulgczawnbmsb6s6qead.onion/
23–24 ноября прошла крупнейшая международная конференция по ИИ AI Journey.
Ну прошла и прошла, мне то что? А вот что😏! Так вышло что я каким-то образом смог поучаствовать в постерной сессии🙈, которая шла параллельно с этой конференции. Мой опыт подобного участия(по ощущениям максимально бесполезный), так и не понял зачем и для кого я делал этот постер.
Кстати можете найти его по ссылке называется Utilize knowledge and persona for dialogue response generation
В целом за этот проект я понял что разработка DL ПО сильно отличается от обычного. Хотя если меня спросят какая концепция мне больше всего помогла в построении DL моделей, я скажу Абстрактная фабрика и TypedDict из модуля typing 👹👹👹
Тот код который вы найдете по QR этой статьи очень плохой, в сравнении с тем проектом, который я пишу сейчас. Хотя я все еще в поисках методологии написании кода для экспериментов(да я пробовал смотреть специализацию по MLOps от Ына, она гавно). Скорее тут поможет курс по дизайну экспериментов(очень интересный) и обычные паттерны проектирования приложений.
Также хочу отметить что идея логгировать результаты генерации модели и метрики в postgresql была лучшей за последнее время. Я конечно понимаю что есть скажем wandb, но он СУПЕР кривой и тормознутый. А какой-нибудь там MLFlow уродливый, да и неудобный тоже...
Вот мой стек:
- база данных через docker-compose из шаблона (мой шаблон на postgresql )
- peewee это удобная ORM для управления моделями, но голая ORM бесполезна без следующего модуля
- peewee_migrations - автомиграции для ваших моделей, как в django3
- dbeaver - надо же как-то писать свои запросы и дебажить, подходит вообще для любой БД
Хотя в целом может есть и готовое решение, но мне о нем точно неизвестно, да и вряд ли я бы смог его прикрутить как именно МНЕ надо к моему коду.
Все еще чувствую себя ебучим импостером(ну он и есть) на своей второй работе (deeppavlov) там все такие все дохуя из себя мфтишники, мгушники и тд (умные то есть), а я такой модельки сделали бррр хыыыы, метрики выросли ыыыы 😓
Ну прошла и прошла, мне то что? А вот что😏! Так вышло что я каким-то образом смог поучаствовать в постерной сессии🙈, которая шла параллельно с этой конференции. Мой опыт подобного участия(по ощущениям максимально бесполезный), так и не понял зачем и для кого я делал этот постер.
Кстати можете найти его по ссылке называется Utilize knowledge and persona for dialogue response generation
В целом за этот проект я понял что разработка DL ПО сильно отличается от обычного. Хотя если меня спросят какая концепция мне больше всего помогла в построении DL моделей, я скажу Абстрактная фабрика и TypedDict из модуля typing 👹👹👹
Тот код который вы найдете по QR этой статьи очень плохой, в сравнении с тем проектом, который я пишу сейчас. Хотя я все еще в поисках методологии написании кода для экспериментов(да я пробовал смотреть специализацию по MLOps от Ына, она гавно). Скорее тут поможет курс по дизайну экспериментов(очень интересный) и обычные паттерны проектирования приложений.
Также хочу отметить что идея логгировать результаты генерации модели и метрики в postgresql была лучшей за последнее время. Я конечно понимаю что есть скажем wandb, но он СУПЕР кривой и тормознутый. А какой-нибудь там MLFlow уродливый, да и неудобный тоже...
Вот мой стек:
- база данных через docker-compose из шаблона (мой шаблон на postgresql )
- peewee это удобная ORM для управления моделями, но голая ORM бесполезна без следующего модуля
- peewee_migrations - автомиграции для ваших моделей, как в django3
- dbeaver - надо же как-то писать свои запросы и дебажить, подходит вообще для любой БД
Хотя в целом может есть и готовое решение, но мне о нем точно неизвестно, да и вряд ли я бы смог его прикрутить как именно МНЕ надо к моему коду.
Все еще чувствую себя ебучим импостером(ну он и есть) на своей второй работе (deeppavlov) там все такие все дохуя из себя мфтишники, мгушники и тд (умные то есть), а я такой модельки сделали бррр хыыыы, метрики выросли ыыыы 😓
AI Journey
Конференция AI Journey 19-21 ноября 2025. Ключевые спикеры в сфере технологий искусственного интеллекта
Конференция AI Journey 19-21 ноября 2025. Ключевые спикеры в сфере технологий искусственного интеллекта.
👍2
Всем привет, хотел поделиться ресурсом.
Список лекций по количественному экономическому моделированию, разработанный и написанный Томасом Дж. Сарджентом и Джоном Стачурски. У каждой лекции есть подробная практическая часть на numpy, scipy, pymc
Сайт проекта
Github проекта
Особенно понравилась статья про Maximum Likelihood Estimation. Кому не сложно накидайте звезд на гитхабе, хотелось бы чтобы таких проектов было намного больше.
Список лекций по количественному экономическому моделированию, разработанный и написанный Томасом Дж. Сарджентом и Джоном Стачурски. У каждой лекции есть подробная практическая часть на numpy, scipy, pymc
Сайт проекта
Github проекта
Особенно понравилась статья про Maximum Likelihood Estimation. Кому не сложно накидайте звезд на гитхабе, хотелось бы чтобы таких проектов было намного больше.
Intermediate Quantitative Economics with Python
This website presents a set of lectures on quantitative economic modeling, designed and written by Thomas J. Sargent and John Stachurski.
🔥4
Всем привет, на связи ноулайфер.
Я написал туториал о настройке ssh соединения для linux и windows машин, а также настройке VS code.
Моя жизнь улучшилась многократно после того как я узнал, что в VS code можно настраивать соединение по приватному ключу, ведь раньше я каждый раз вводил пароль(это было довольно утомительно). Зато теперь моя жизнь эникейщика стала намного проще.
Сам туториал я решил написать на github, потому как я смогу его дополнять если что, или фиксить ошибки.
ССЫЛКА НА ТУТОРИАЛ
Также в следующий раз мне хотелось бы рассказать про такую замечательную технологию как dev container. Я считаю что это простая и в тоже время очень важная технология, которая позволит повысить воспроизводимость в DL многократно. Потому как сейчас все что я вижу это лютый кринж.
Один лайк и я расскажу как настроить CI\CD на gitlab, с kubernetes на bare metal на примере django 4 и vue 3. С настройкой домена, конфигурированием сервера и бекапом базы данных в S3.
Я написал туториал о настройке ssh соединения для linux и windows машин, а также настройке VS code.
Моя жизнь улучшилась многократно после того как я узнал, что в VS code можно настраивать соединение по приватному ключу, ведь раньше я каждый раз вводил пароль(это было довольно утомительно). Зато теперь моя жизнь эникейщика стала намного проще.
Сам туториал я решил написать на github, потому как я смогу его дополнять если что, или фиксить ошибки.
ССЫЛКА НА ТУТОРИАЛ
Также в следующий раз мне хотелось бы рассказать про такую замечательную технологию как dev container. Я считаю что это простая и в тоже время очень важная технология, которая позволит повысить воспроизводимость в DL многократно. Потому как сейчас все что я вижу это лютый кринж.
Один лайк и я расскажу как настроить CI\CD на gitlab, с kubernetes на bare metal на примере django 4 и vue 3. С настройкой домена, конфигурированием сервера и бекапом базы данных в S3.
GitHub
GitHub - dmitrymailk/ssh_remote
Contribute to dmitrymailk/ssh_remote development by creating an account on GitHub.
👍8🔥1
Всем привет, на связи ноулайфер.
Сегодня я хотел бы поделится с вами задачей над которой работал последний месяц(ну чуть меньше).
Автоматические методы оценки текста для open end диалоговых систем.
Как много вы про это слышали? Наверное знаете про то что есть какой-то там BLEU или METEOR, используй их и не думай.
Так думал я до этого мини исследования. Не буду томить вот выводы которые я сделал:
• Реализация важнее теории, важно указывать не просто ссылку на оригинальную работу по типу BLEU(а конкретный пакет и версию)
• На данный момент не существует универсальной метрики для оценки open end диалогов. Метрики лучше всего показывают себя на тех данных на которых они тренировались, что свидетельствует об переобучении.
• Важно давать инструкции разметчикам. Во всех работах наблюдается низкий уровень согласованности между людьми. Соответственно алгоритм ничего не найдет в зашумленных данных.
• Необходимо оставлять очень подробную документацию о постановке эксперимента оценок людьми, а также выкладывать данные с их оценками.
• Писать доку к проектам и оборачивать итоговое решение в docker, использовать технологию .devcontainer. Думать о том, что это будут использовать другие.
• Стараться использовать как можно больше метрик в своем исследовании, чтобы собрать как можно данных о метриках в разных доменах
• Необходимо использовать более продвинутые способы сбора информации чем Likert. Так как шкала может пониматься разметчиками совершенно по разному
• Использовать для корреляции Spearman, а не Pearson
Если вам интересно как я пришел к этим выводам, вот презентация на эту тему
А если вы сами что-то понимаете приглашаю законтрибьютить в данную репу https://github.com/dmitrymailk/text_evaluation
Ладно я пошел за хлебом, не теряйте, обнял.
Сегодня я хотел бы поделится с вами задачей над которой работал последний месяц(ну чуть меньше).
Автоматические методы оценки текста для open end диалоговых систем.
Как много вы про это слышали? Наверное знаете про то что есть какой-то там BLEU или METEOR, используй их и не думай.
Так думал я до этого мини исследования. Не буду томить вот выводы которые я сделал:
• Реализация важнее теории, важно указывать не просто ссылку на оригинальную работу по типу BLEU(а конкретный пакет и версию)
• На данный момент не существует универсальной метрики для оценки open end диалогов. Метрики лучше всего показывают себя на тех данных на которых они тренировались, что свидетельствует об переобучении.
• Важно давать инструкции разметчикам. Во всех работах наблюдается низкий уровень согласованности между людьми. Соответственно алгоритм ничего не найдет в зашумленных данных.
• Необходимо оставлять очень подробную документацию о постановке эксперимента оценок людьми, а также выкладывать данные с их оценками.
• Писать доку к проектам и оборачивать итоговое решение в docker, использовать технологию .devcontainer. Думать о том, что это будут использовать другие.
• Стараться использовать как можно больше метрик в своем исследовании, чтобы собрать как можно данных о метриках в разных доменах
• Необходимо использовать более продвинутые способы сбора информации чем Likert. Так как шкала может пониматься разметчиками совершенно по разному
• Использовать для корреляции Spearman, а не Pearson
Если вам интересно как я пришел к этим выводам, вот презентация на эту тему
А если вы сами что-то понимаете приглашаю законтрибьютить в данную репу https://github.com/dmitrymailk/text_evaluation
Ладно я пошел за хлебом, не теряйте, обнял.
Google Docs
Автоматическая оценка диалогов(или хватит использовать BLEU)
Автоматическая оценка диалогов(или хватит использовать BLEU )
🔥6
hash() в python возвращает разный хеш в разных процессах для одинаковых строк.
Это связано с тем что эта функция зависит от переменной PYTHONHASHSEED, значение которой может меняться, а может не меняться)) Зависит от версии python. Поэтому не стоит ее использовать для создания хешей скажем файлов. Для этого лучше взять к примеру
А зачем и почему так? Почему раньше было по-другому?
А потому что некоторые люди-суки любят ломать и атаковать другие программы. Так вот, если не менять сид функции, которая генерит хеши то возможно увеличить сложность работы алгоритма с O(1) до O(n). ЧЗХ магия? Нет, математика(да магия).
Если некратко почему и как это работает, то вот ссылка. А если кратко, то к примеру словари в python работают на структуре hash table. В целом если на собесе спросят, то у нее сложность O(1) для вставки. Но это в среднем. Если атакующий подберет данные для hash функции так чтобы элементы при хешировании попадали в одни и те же бакеты, то для вставки ему нужно будет пробегать весь связный список чтобы удостовериться в уникальности. Ну это один из примеров, на деле хеш функции много где используются, поэтому если хотите чтобы вам ничего не сломали, то не говорите вообще ничего, даже информация версии языка может быть использована против вас.
Или история о том как я потратил на исправление бага разработчиков deepspeed несколько часов чтобы все начало работать 🤪🤪🤪
Вот вам еще дока на этот счет где об этом тоже ничего не написано.
Но вот тут написано, что странно, я бы сюда точно не полез, если бы мне нужна была хеш функция.
Слава богу что есть люди которые смогли успокоить мою паранойю на stack overflow
Это связано с тем что эта функция зависит от переменной PYTHONHASHSEED, значение которой может меняться, а может не меняться)) Зависит от версии python. Поэтому не стоит ее использовать для создания хешей скажем файлов. Для этого лучше взять к примеру
hashlib.sha256
А зачем и почему так? Почему раньше было по-другому?
А потому что некоторые люди-суки любят ломать и атаковать другие программы. Так вот, если не менять сид функции, которая генерит хеши то возможно увеличить сложность работы алгоритма с O(1) до O(n). ЧЗХ магия? Нет, математика(да магия).
Если некратко почему и как это работает, то вот ссылка. А если кратко, то к примеру словари в python работают на структуре hash table. В целом если на собесе спросят, то у нее сложность O(1) для вставки. Но это в среднем. Если атакующий подберет данные для hash функции так чтобы элементы при хешировании попадали в одни и те же бакеты, то для вставки ему нужно будет пробегать весь связный список чтобы удостовериться в уникальности. Ну это один из примеров, на деле хеш функции много где используются, поэтому если хотите чтобы вам ничего не сломали, то не говорите вообще ничего, даже информация версии языка может быть использована против вас.
Или история о том как я потратил на исправление бага разработчиков deepspeed несколько часов чтобы все начало работать 🤪🤪🤪
Вот вам еще дока на этот счет где об этом тоже ничего не написано.
Но вот тут написано, что странно, я бы сюда точно не полез, если бы мне нужна была хеш функция.
Слава богу что есть люди которые смогли успокоить мою паранойю на stack overflow
👨💻8🤯2❤1
Всем привет. В моей группе стало больше 50 подписчиков, а это значит настало время рекламы от спонсоров.
1. Сервис для создания презентаций с красивыми шаблонами. Это некоторый аналог фигмы, только вырезали всю шелуху, оставили только пачку нормальных шаблонов общего типа конкретно для презентаций. pitch.com
2. Лично у меня больше нет оправдания не знать линал, теорвер и абстрактную алгебру в мельчайших деталях. Раньше я бросал многие учебники, потому что было сложно проверить а правильно я решил или нет, а если неправильно то что делать. Вот теперь у нас есть сервис brainly.com, где очень удобно собраны решения к самым крутым техническим книгам. (они просят деньги чтобы смотреть много решений, но можно поступить так же как и с medium - отключить куки для этого сайта в настройках 😎)
3. Бесплатный VPN, распширение для браузера. Hola VPN. Работает безотказно.
Далее поделюсь примерами слайдов которые я быстро накидал пока делал презентацию для курсовой, вроде неплохо для недизайнера.
1. Сервис для создания презентаций с красивыми шаблонами. Это некоторый аналог фигмы, только вырезали всю шелуху, оставили только пачку нормальных шаблонов общего типа конкретно для презентаций. pitch.com
2. Лично у меня больше нет оправдания не знать линал, теорвер и абстрактную алгебру в мельчайших деталях. Раньше я бросал многие учебники, потому что было сложно проверить а правильно я решил или нет, а если неправильно то что делать. Вот теперь у нас есть сервис brainly.com, где очень удобно собраны решения к самым крутым техническим книгам. (они просят деньги чтобы смотреть много решений, но можно поступить так же как и с medium - отключить куки для этого сайта в настройках 😎)
3. Бесплатный VPN, распширение для браузера. Hola VPN. Работает безотказно.
Далее поделюсь примерами слайдов которые я быстро накидал пока делал презентацию для курсовой, вроде неплохо для недизайнера.
👍10🔥1🤡1
Импорт llama2.c от karpathy на cython...
В своей жизни каждый программист должен изучить как минимум одну странную технологию, так вот сегодня я расскажу вам о cython, читается как сай(между зубов такая т)он, не перепутайте.
Я накатал небольшой обзор основных фич данного инструмента. В целом выводы можно сделать следующие. Вам нужен cython если
- вы боитесь писать код на с++, и вы работаете с какими-то невычислительными задачами, а скорость нужна
- вам надо как-то интегрировать инструменты на с++ в свой проект
- у вас чешутся руки, хочется что-то поускорять
Мой вариант если догадались это последний, поэтому на свет родился следующий туториал:
cython_lesson
Вооот, один лайк и в следующий раз я расскажу вам о своих попытках познать жизнь и всё сущее 🤖
В своей жизни каждый программист должен изучить как минимум одну странную технологию, так вот сегодня я расскажу вам о cython, читается как сай(между зубов такая т)он, не перепутайте.
Я накатал небольшой обзор основных фич данного инструмента. В целом выводы можно сделать следующие. Вам нужен cython если
- вы боитесь писать код на с++, и вы работаете с какими-то невычислительными задачами, а скорость нужна
- вам надо как-то интегрировать инструменты на с++ в свой проект
- у вас чешутся руки, хочется что-то поускорять
Мой вариант если догадались это последний, поэтому на свет родился следующий туториал:
cython_lesson
Вооот, один лайк и в следующий раз я расскажу вам о своих попытках познать жизнь и всё сущее 🤖
GitHub
GitHub - dmitrymailk/cython_lesson
Contribute to dmitrymailk/cython_lesson development by creating an account on GitHub.
👍14❤2🤡1
Выложил бенчмарк для автоматической оценки LLM для русского языка при помощи gpt-4. По факту это просто переведенная версия официального mt-bench, только с модифицированным интерфейсом просмотра и завернутым в докер чтобы это продолжало работать и через год. Ну и соответственно там есть небольшой лидерборд. https://github.com/dmitrymailk/mt_bench_ru
👍7🔥3🤡2
Какое-то время назад я, вдохновившись проектом Saiga, пытался сделать свою модель, более лучшую (спойлер ничего не вышло). Я полагал, чтобы улучшить ее, необходимо собрать больше разнообразных датасетов. Из этого родился данный датасет verbalist.
В большей мере это просто сборник инструкционных датасетов со всего huggingface, с небольшой предобработкой. Однако среди них есть и те которые я собирал вручную, например:
• dim/logic_tasks_ru - набор задач по логике для детей взят с веб-сайта.
• dim/openreview_prompts_65 - Датасет рецензий на реальные научные статьи с сайта openreview. Вышло на самом деле не так много, так как многие статьи не выложенны на arxiv или просто не имеют рецензий. Плюс я собрал только малую часть данного сайта, а не все что там было.
• dim/kinomania_noscripts - Небольшой датасет, который содержит в себе сценарии фильмов целиком и их краткое содержание
• dim/bugurt_thread_prompts - Небольшой набор размеченных бугуртов вместе с моим другом, для того чтобы модель научилась писать бугурты на конкретную ситуацию. Собраны из телеграм паблика БУГУРТ ТРЕД(https://news.1rj.ru/str/bugurtthread)
• dim/russian_lyrics_prompts - Небольшой датасет промптов собранный мною из различных учебников по стихосложению, чтобы модель научилась писать стихи, используя необходимый литературный прием на конкретную тему.
• dim/azbyka_logic_ru - Небольшой набор детских логических и православных задач, взятых с сайта. Обычно у них почти нет развернутого решения, только ответ. Я пытался расписать решение некоторых задач, но меня хватило только на 35, если кто-то займется подобным буду рад .
• dim/what_where_when_ru - полная выгрузка данных с https://db.chgk.info, примерно 228k пар вопросов ответов.
• dim/bugurt_completion_prompts - Обрезанные бугурты, где в качестве промпта используется строка вида - продолжи бугурт: первая строчка бугурта
• dim/forum_uristov_rf_prompts - Вопросы-ответы с российского юридического форума.
• dim/huggingartists_prompts - Промпты, которые просят продолжить песню в стиле определенного исполнителя. В данном наборе содержатся почти все исполнители, которых вы можете найти в этой организации https://huggingface.co/huggingartists
Описание остальных датасетов и их предобработки можно найти в основной репе.
Ощущаю себя сизифом 🪨🚶💬
В большей мере это просто сборник инструкционных датасетов со всего huggingface, с небольшой предобработкой. Однако среди них есть и те которые я собирал вручную, например:
• dim/logic_tasks_ru - набор задач по логике для детей взят с веб-сайта.
• dim/openreview_prompts_65 - Датасет рецензий на реальные научные статьи с сайта openreview. Вышло на самом деле не так много, так как многие статьи не выложенны на arxiv или просто не имеют рецензий. Плюс я собрал только малую часть данного сайта, а не все что там было.
• dim/kinomania_noscripts - Небольшой датасет, который содержит в себе сценарии фильмов целиком и их краткое содержание
• dim/bugurt_thread_prompts - Небольшой набор размеченных бугуртов вместе с моим другом, для того чтобы модель научилась писать бугурты на конкретную ситуацию. Собраны из телеграм паблика БУГУРТ ТРЕД(https://news.1rj.ru/str/bugurtthread)
• dim/russian_lyrics_prompts - Небольшой датасет промптов собранный мною из различных учебников по стихосложению, чтобы модель научилась писать стихи, используя необходимый литературный прием на конкретную тему.
• dim/azbyka_logic_ru - Небольшой набор детских логических и православных задач, взятых с сайта. Обычно у них почти нет развернутого решения, только ответ. Я пытался расписать решение некоторых задач, но меня хватило только на 35, если кто-то займется подобным буду рад .
• dim/what_where_when_ru - полная выгрузка данных с https://db.chgk.info, примерно 228k пар вопросов ответов.
• dim/bugurt_completion_prompts - Обрезанные бугурты, где в качестве промпта используется строка вида - продолжи бугурт: первая строчка бугурта
• dim/forum_uristov_rf_prompts - Вопросы-ответы с российского юридического форума.
• dim/huggingartists_prompts - Промпты, которые просят продолжить песню в стиле определенного исполнителя. В данном наборе содержатся почти все исполнители, которых вы можете найти в этой организации https://huggingface.co/huggingartists
Описание остальных датасетов и их предобработки можно найти в основной репе.
Ощущаю себя сизифом 🪨🚶
Please open Telegram to view this post
VIEW IN TELEGRAM
🔥9👍2
Топ моих любимых плагинов для obsidian.md
Сколько не пытался пользоваться онлайн заметками все время приходил к выводу, что я им не доверяю. Поэтому последнее время пользуюсь исключительно obsidian. Однако в его дефолтной версии не хватает удобных фич для работы с картинками или автоматическим сохранением. Поэтому решил поделиться следующим списком:
‣ Autocomplete - помогает быстрее писать часто повторяющиеся слова или термины, типа Т9
‣ Git - автоматически сохраняет заметки в гит. У меня pro на гитхабе, поэтому я могу создавать приватные репозитории. Думаю можно совершенно без проблем прикрутить к любому другому провайдеру или self-hosted.
‣ Clear Unused Images - так как это локальный редактор, то при вставке изображения она просто сохраняется в папку и потом вставляется ее путь. Если я удалю из редактора путь, сама картинка никуда не денется. Для этого создано данное расширение, если картинка не появляется ни в одном документе, то она удаляется по нажатию на одну кнопку. Очень удобно.
‣ Image Toolkit - просмотр изображений в дефолтном obsidian реализован очень неудобно. Данное расширение помогает смотреть изображения при нажатии на них, с возможностью увеличивать и открывать на полный экран.
‣ Mousewheel Image zoom - мне часто при конспектировании различных лекций приходится вставлять скриншоты. При вставке они бывают либо слишком большими, либо слишком маленькими. Раньше приходилось руками подбирать размер, чтобы картинки не мешали. Данное расширение помогает очень быстро адаптировать размер изображения, при этом все остается в рамках стандартного markdown без добавления css.
‣ Paste URL into selection - обожаю коллекционировать полезные ссылки. Чтобы вставить ссылку с подписью в markdown нужно написать конструкцию вида [текст](ссылка) это очень долго, если речь идет о конспектировании. Данный плагин позволяет формировать гиперссылку для выделенного текста при помощи обычного ctrl+V
‣ Scroll To Top - позволяет моментально скролить вверх или вниз страницы.
Сколько не пытался пользоваться онлайн заметками все время приходил к выводу, что я им не доверяю. Поэтому последнее время пользуюсь исключительно obsidian. Однако в его дефолтной версии не хватает удобных фич для работы с картинками или автоматическим сохранением. Поэтому решил поделиться следующим списком:
‣ Autocomplete - помогает быстрее писать часто повторяющиеся слова или термины, типа Т9
‣ Git - автоматически сохраняет заметки в гит. У меня pro на гитхабе, поэтому я могу создавать приватные репозитории. Думаю можно совершенно без проблем прикрутить к любому другому провайдеру или self-hosted.
‣ Clear Unused Images - так как это локальный редактор, то при вставке изображения она просто сохраняется в папку и потом вставляется ее путь. Если я удалю из редактора путь, сама картинка никуда не денется. Для этого создано данное расширение, если картинка не появляется ни в одном документе, то она удаляется по нажатию на одну кнопку. Очень удобно.
‣ Image Toolkit - просмотр изображений в дефолтном obsidian реализован очень неудобно. Данное расширение помогает смотреть изображения при нажатии на них, с возможностью увеличивать и открывать на полный экран.
‣ Mousewheel Image zoom - мне часто при конспектировании различных лекций приходится вставлять скриншоты. При вставке они бывают либо слишком большими, либо слишком маленькими. Раньше приходилось руками подбирать размер, чтобы картинки не мешали. Данное расширение помогает очень быстро адаптировать размер изображения, при этом все остается в рамках стандартного markdown без добавления css.
‣ Paste URL into selection - обожаю коллекционировать полезные ссылки. Чтобы вставить ссылку с подписью в markdown нужно написать конструкцию вида [текст](ссылка) это очень долго, если речь идет о конспектировании. Данный плагин позволяет формировать гиперссылку для выделенного текста при помощи обычного ctrl+V
‣ Scroll To Top - позволяет моментально скролить вверх или вниз страницы.
Obsidian
Obsidian - Sharpen your thinking
The free and flexible app for your private thoughts.
👍8❤2