Hello. This channel is my personal development log about neural networks and machine learning.
Sebastian Ruder wrote in his blog (http://ruder.io/requests-for-research/index.html) about perspectives of Neural Networks in NLP.
He thinks that Few-Shot and Transfer learning will give huge impact in this area.
I found his arguments convincing, so now I'm making experiments with Few-Shot learning.
There are a lot of good datasets for Few-Shot learning problem in Computer Vision, e.g. Omniglot https://github.com/brendenlake/omniglot or any dataset for face recognition.
The most closest analogue in NLP is Conversations and Question answering dataset.
But result evaluation of this tasks is very specific: we can't check if random text answers some question without human because it's impossible to align all texts with a set of predefined labels like it is accomplished in Omniglot.
There is however a NLP task which fits Few-Shot learning approach - Named Entity Linking or NEL for short.
In NEL we should assign exact
The number of possible concepts is very large and grows with time, so it's impossible to apply regular classification techniques.
It makes NEL task perfect for Few-Shot learning. I prepared WikiLinks based dataset https://www.kaggle.com/generall/oneshotwikilinks
This dataset consists of entity mentions with corresponding wikipedia links. There are also kNN baseline which gives 70% accuracy.
KNN uses only Bag Of Words features without any word2vec or synonyms.
My next step was to try use well known neural architectures for text matching. It worth detailed denoscription, so next few posts will be about it.
He thinks that Few-Shot and Transfer learning will give huge impact in this area.
I found his arguments convincing, so now I'm making experiments with Few-Shot learning.
There are a lot of good datasets for Few-Shot learning problem in Computer Vision, e.g. Omniglot https://github.com/brendenlake/omniglot or any dataset for face recognition.
The most closest analogue in NLP is Conversations and Question answering dataset.
But result evaluation of this tasks is very specific: we can't check if random text answers some question without human because it's impossible to align all texts with a set of predefined labels like it is accomplished in Omniglot.
There is however a NLP task which fits Few-Shot learning approach - Named Entity Linking or NEL for short.
In NEL we should assign exact
concept link for each mention in text. You can think about concepts like about Wikipedia articles.The number of possible concepts is very large and grows with time, so it's impossible to apply regular classification techniques.
It makes NEL task perfect for Few-Shot learning. I prepared WikiLinks based dataset https://www.kaggle.com/generall/oneshotwikilinks
This dataset consists of entity mentions with corresponding wikipedia links. There are also kNN baseline which gives 70% accuracy.
KNN uses only Bag Of Words features without any word2vec or synonyms.
My next step was to try use well known neural architectures for text matching. It worth detailed denoscription, so next few posts will be about it.
🔥1
As a starting point I used MatchZoo - a collection of text matching models https://github.com/faneshion/MatchZoo.
It contains a set of model implementations in Keras as well as number of benchmark datasets.
MatchZoo was created by authors of the main part of those models. It includes a lot of different examples, but configuration requires manual adjustment for each new task.
I used MatchZoo implementation of CDSSM model as a baseline reference for my own implementation. With this baseline I was sure that the source of all possible errors is my model, not the shifted labels in dataset.
It contains a set of model implementations in Keras as well as number of benchmark datasets.
MatchZoo was created by authors of the main part of those models. It includes a lot of different examples, but configuration requires manual adjustment for each new task.
I used MatchZoo implementation of CDSSM model as a baseline reference for my own implementation. With this baseline I was sure that the source of all possible errors is my model, not the shifted labels in dataset.
GitHub
GitHub - NTMC-Community/MatchZoo: Facilitating the design, comparison and sharing of deep text matching models.
Facilitating the design, comparison and sharing of deep text matching models. - GitHub - NTMC-Community/MatchZoo: Facilitating the design, comparison and sharing of deep text matching models.
A variety of deep matching models can be categorized into two types according to their architecture.
One is the representation-focused model (pic. 1), which tries to build a good representation for a single text with a deep neural network, and then conducts matching between compressed text representations. Examples include DSSM, C-DSSM and ARC-I.
The other is the interaction-focused model (pic. 2), which first builds local interactions (i.e., local matching signals) between two
pieces of text, and then uses deep neural networks to learn hierarchical interaction patterns for matching. Examples
include MV-LSTM , ARC-II and MatchPyramid.
Useful property of representation-focused models is the possibility to pre-compute representation vectors.
It allows, for example, to perform fast ranking of web pages in search engines.
However, it does not take into account the interaction between two texts until an individual presentation of each text is generated.
Therefore there is a risk of losing details (e.g., a city name) important for the matching task in representing the texts.
In other words, in the forward phase (prediction), the representation of each text is formed without knowledge of each other.
As a result, interaction-focused models tends to perform better in Question Answering and Paraphrase Indentification tasks, though they are not applicable for web-scale matching.
One is the representation-focused model (pic. 1), which tries to build a good representation for a single text with a deep neural network, and then conducts matching between compressed text representations. Examples include DSSM, C-DSSM and ARC-I.
The other is the interaction-focused model (pic. 2), which first builds local interactions (i.e., local matching signals) between two
pieces of text, and then uses deep neural networks to learn hierarchical interaction patterns for matching. Examples
include MV-LSTM , ARC-II and MatchPyramid.
Useful property of representation-focused models is the possibility to pre-compute representation vectors.
It allows, for example, to perform fast ranking of web pages in search engines.
However, it does not take into account the interaction between two texts until an individual presentation of each text is generated.
Therefore there is a risk of losing details (e.g., a city name) important for the matching task in representing the texts.
In other words, in the forward phase (prediction), the representation of each text is formed without knowledge of each other.
As a result, interaction-focused models tends to perform better in Question Answering and Paraphrase Indentification tasks, though they are not applicable for web-scale matching.
1. Representation-based architecture. 2. Interaction-based architecture (MV-LSTM)
Neural Networks debugging
When training neural networks it can often be unclear why the network is not learning. Is it about learning parameters or NN architecture?
Brute force search on full training dataset may be very time consuming even with GPU acceleration.
If you need to write code on your laptop and run it on remote machine, it makes process even more painful.
One way to solve this problem is to use synthetic datasets for debugging.
The idea is to create small sets of examples each of which is a little more complex then previous one.
Let me illustrate this approach. On picture example we can see that model is able to distinguish:
- Object presence
- Shapes
- Colors
- Rotation
- Stroke
And it can't distinguish alignment and count of objects. Keep in mind that number of layers and neurons should be scaled down according to the size of synthetic data, or network will overfit. Knowing evaluation results we can quickly iterate over modifications for our network architecture.
Of course solving synthetic dataset does not guarantee solving real-life tasks. As well as passing Unit test does not guarantee that code has no bugs.
But there is another useful thing we can do: with large amount of small experiments we can detect relations between the result and changing of network parameters. This information will help us to concentrate on significant parameters tuning while training on real data.
Not only images can synthesized for training. In my NEL project I am using 13 synthetic text datasets. Size of this datasets allows me to debug neural network on laptop without any GPU. You can find code its generation here .
Writing code for data generation may be time consuming and boring, so the next possible step in NN debugging is to create tools, framework or even language for data generation. With declarative SQL-like language it would be possible to create datasets automatically, for example using some kind of evolution strategy. Unfortunately I was unable to find anything suitable for this task, so it is a good place for you to contribute!
When training neural networks it can often be unclear why the network is not learning. Is it about learning parameters or NN architecture?
Brute force search on full training dataset may be very time consuming even with GPU acceleration.
If you need to write code on your laptop and run it on remote machine, it makes process even more painful.
One way to solve this problem is to use synthetic datasets for debugging.
The idea is to create small sets of examples each of which is a little more complex then previous one.
Let me illustrate this approach. On picture example we can see that model is able to distinguish:
- Object presence
- Shapes
- Colors
- Rotation
- Stroke
And it can't distinguish alignment and count of objects. Keep in mind that number of layers and neurons should be scaled down according to the size of synthetic data, or network will overfit. Knowing evaluation results we can quickly iterate over modifications for our network architecture.
Of course solving synthetic dataset does not guarantee solving real-life tasks. As well as passing Unit test does not guarantee that code has no bugs.
But there is another useful thing we can do: with large amount of small experiments we can detect relations between the result and changing of network parameters. This information will help us to concentrate on significant parameters tuning while training on real data.
Not only images can synthesized for training. In my NEL project I am using 13 synthetic text datasets. Size of this datasets allows me to debug neural network on laptop without any GPU. You can find code its generation here .
Writing code for data generation may be time consuming and boring, so the next possible step in NN debugging is to create tools, framework or even language for data generation. With declarative SQL-like language it would be possible to create datasets automatically, for example using some kind of evolution strategy. Unfortunately I was unable to find anything suitable for this task, so it is a good place for you to contribute!
GitHub
OneShotNLP/ComplexTopicsGenerator.ipynb at master · generall/OneShotNLP
PyTorch text matching models implementation for One-Shot Named Entity Linking - generall/OneShotNLP
👍1🔥1
Practical example.
Situation: CDSSM model does not learn well on big dataset of natural language sentences. What is our next step?
Running the model on several synthetic datasets, we notice that CDSSM model is unable to handle the following simple data:
Withal the final matching layer of CDSSM is unable to hold enough information about each concrete word in original sentence.
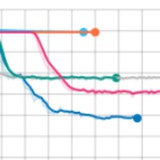
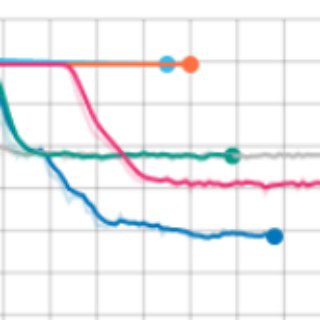
So the only way for network to minimize error is to remember noise in train set. Such behavior is easy to recognize on loss plots.
Train loss goes down quickly but validation loss grows - typical overfitting (pic 1.).
One possible way to solve this dataset is to change network architecture to the one that can handle low level interactions between words in sentence pair.
In previous post I mentioned interaction-focused models, the exact type of models we need. I choose ARC-II architecture for my experiment, you can check out implementation here . New model fits synthetic data perfectly well (pic 2.). As a result we can safely skip time consuming experiments with CDSSM model on real dataset.
Situation: CDSSM model does not learn well on big dataset of natural language sentences. What is our next step?
Running the model on several synthetic datasets, we notice that CDSSM model is unable to handle the following simple data:
Each sentence has several of N topic words + random noise words. Two sentences matching only if they have at least one common word.
Example:CDSSM overfits on this data. The reason is that it is unknown which word will be useful for matching before actual comparison of sentences.
1 ldwjum mugqw sohyp sohyp dwguv mugqw
0 ldwjum mugqw sohyp labhvz epqori kfdo
1 xnwpjc agqv lmjoh wvncu tekj lmjoh
0 xnwpjc agqv lmjoh jhnt fhzb xauhq
1 vflcmn pnuvx eolwrj dhfvbt vflcmn toxeyc
0 vflcmn pnuvx eolwrj dhfvbt yetkah bfnxqp
1 rybmae bwcej xnwpjc bwcej yrhefk yhca
0 rybmae bwcej xnwpjc bhck zbfj yhca
1 sohyp htdp symc jrvsyn symc fpoxj
0 sohyp htdp symc eolwrj masq hjzrp
1 dhfvbt yetkah omsaij omsaij dhfvbt tqdef
0 dhfvbt yetkah omsaij zilrh wvncu sohyp
Withal the final matching layer of CDSSM is unable to hold enough information about each concrete word in original sentence.
So the only way for network to minimize error is to remember noise in train set. Such behavior is easy to recognize on loss plots.
Train loss goes down quickly but validation loss grows - typical overfitting (pic 1.).
One possible way to solve this dataset is to change network architecture to the one that can handle low level interactions between words in sentence pair.
In previous post I mentioned interaction-focused models, the exact type of models we need. I choose ARC-II architecture for my experiment, you can check out implementation here . New model fits synthetic data perfectly well (pic 2.). As a result we can safely skip time consuming experiments with CDSSM model on real dataset.
GitHub
OneShotNLP/src/model/arc2.py at master · generall/OneShotNLP
PyTorch text matching models implementation for One-Shot Named Entity Linking - generall/OneShotNLP
FastText embeddings done right
An important feature of FastText embeddings is the usage of subword information.
In addition to the vocabulary FastText also contains word's ngrams.
This additional information is useful for the following: handling Out-Of-Vocabulary words, extracting sense from word's etymology and dealing with misspellings.
But unfortunately all this advantages are not used in most open source projects.
We can easily discover it via GitHub (pic.). The point is that regular
The good thing is that using FastText correctly is not so difficult! FacebookResearch provides an example of the proper way to use FastText in PyTorch framework.
Instead of
Now we will obtain all advantages in our neural network.
An important feature of FastText embeddings is the usage of subword information.
In addition to the vocabulary FastText also contains word's ngrams.
This additional information is useful for the following: handling Out-Of-Vocabulary words, extracting sense from word's etymology and dealing with misspellings.
But unfortunately all this advantages are not used in most open source projects.
We can easily discover it via GitHub (pic.). The point is that regular
Embedding layer maps the whole word into a single stored in memory fixed vector. In this case all the word vectors should be generated in advance, so none of the cool features work. The good thing is that using FastText correctly is not so difficult! FacebookResearch provides an example of the proper way to use FastText in PyTorch framework.
Instead of
Embedding you should choose EmbeddingBag layer. It will combine ngrams into single word vector which can be used as usual.Now we will obtain all advantages in our neural network.
GitHub
GitHub - facebookresearch/fastText: Library for fast text representation and classification.
Library for fast text representation and classification. - facebookresearch/fastText
Parallel preprocessing with
Using multiple processes to construct train batches may significantly reduce total training time of your network.
Basically, if you are using GPU for training, you can reduce additional batch construction time almost to zero. This is achieved through pipelining of computations: while GPU crunches numbers, CPU makes preprocessing. Python
PyTorch
Unfortunately
*
Methods
* Serialization
Other pitfall is associated with the need to transfer objects via pipes. In addition to the processing results,
Another difficulty that you may encounter is if the preprocessor is faster than GPU learning. In this case unprocessed batches accumulate in memory. If your memory is not to large enough you will get Out-of-Memory error. One way to solve this problem is to limit batch preprocessing until GPU learning is done.
multiprocessingUsing multiple processes to construct train batches may significantly reduce total training time of your network.
Basically, if you are using GPU for training, you can reduce additional batch construction time almost to zero. This is achieved through pipelining of computations: while GPU crunches numbers, CPU makes preprocessing. Python
multiprocessing module allows us to implement such pipelining as elegant as it is possible in the language with GIL.PyTorch
DataLoader class, for example, also uses multiprocessing in it's internals.Unfortunately
DataLoader suffers lack of flexibility. It's impossible to create batch with any complex structure within standard DataLoader class. So it should be useful to be able to apply raw multiprocessing.multiprocessing gives us a set of useful APIs to distribute computations among several processes. Processes does not share memory with each other, so data is transmitted via inter-process communication protocols. For example in linux-like operation systems multiprocessing uses pipes. Such organization leads to some pitfalls that I am going to tell you.*
map vs imapMethods
map and imap may be used to apply preprocessing to batches. Both of them take processing function and iterable as argument. The difference is that imap is lazy. It will return processed elements as soon as they are ready. In this case all processed batched should not be stored in RAM simultaneously. For training NN you should always prefer imap: def process(batch_reader):
with Pool(threads) as pool:
for batch in pool.imap(foo, batch_reader):
....
yield batch
....
* Serialization
Other pitfall is associated with the need to transfer objects via pipes. In addition to the processing results,
multiprocessing will also serialize transformation object if it is used like this: pool.imap(transformer.foo, batch_reader). transformer will be serialized and send to subprocess. It may lead to some problems if transformer object has large properties. In this case it may be better to store large properties as singleton class variables:class Transformer():
large_dictinary = None
def __init__(self, large_dictinary, **kwargs):
self.__class__.large_dictinary = large_dictinary
def foo(self, x):
....
y = self.large_dictinary[x]
....
Another difficulty that you may encounter is if the preprocessor is faster than GPU learning. In this case unprocessed batches accumulate in memory. If your memory is not to large enough you will get Out-of-Memory error. One way to solve this problem is to limit batch preprocessing until GPU learning is done.
Semaphore is perfect solution for this task:def batch_reader(semaphore):
for batch in source:
semaphore.acquire()
yield batch
def process(x):
return x + 1
def pooling():
with Pool(threads) as pool:
semaphore = Semaphore(limit)
for x in pool.imap(plus, batch_reader(semaphore)):
yield x
semaphore.release()
for x in pooling():
learn_gpu(x)
Semaphore has internal counter syncronized across all working processes. It's logic will block execution if some process tries to increase counet value above limit with semaphore.acquire ()👍1
There are some cases when you need to run your model on a small machine.
For example, if your model is being called 1 time per hour or you just don't want to pay $150 per month to Amazon for t2.2xlarge instance with 32Gb RAM.
The problem is that the size of most pre-trained word embeddings can reach tens of gigabytes.
In this post, I will describe the method of access word vectors without loading it into memory.
The idea is to simply save word vectors as a matrix so that we could compute the position of each row without reading any other rows from disk.
Fortunately, all this logic is already implemented in
The only thing we need to implement ourselves is the function which converts word into an appropriate index. We can simply store the whole vocabulary in memory or use hashing trick, it does not matter at this point.
It is slightly harder to store FastText vectors that way because it requires additional computation on n-grams to obtain word vector.
So for simplicity, we will just pre-compute vectors for all necessary words.
You may take a look at a simple implementation of the described approach here:
https://github.com/generall/OneShotNLP/blob/master/src/utils/disc_vectors.py
Class
Once the model is converted, you can retrieve vectors with
For example, if your model is being called 1 time per hour or you just don't want to pay $150 per month to Amazon for t2.2xlarge instance with 32Gb RAM.
The problem is that the size of most pre-trained word embeddings can reach tens of gigabytes.
In this post, I will describe the method of access word vectors without loading it into memory.
The idea is to simply save word vectors as a matrix so that we could compute the position of each row without reading any other rows from disk.
Fortunately, all this logic is already implemented in
numpy.memmap.The only thing we need to implement ourselves is the function which converts word into an appropriate index. We can simply store the whole vocabulary in memory or use hashing trick, it does not matter at this point.
It is slightly harder to store FastText vectors that way because it requires additional computation on n-grams to obtain word vector.
So for simplicity, we will just pre-compute vectors for all necessary words.
You may take a look at a simple implementation of the described approach here:
https://github.com/generall/OneShotNLP/blob/master/src/utils/disc_vectors.py
Class
DiscVectors contains method for converting fastText .bin model into on-disk matrix representation and json file with vocabulary and meta-information.Once the model is converted, you can retrieve vectors with
get_word_vector method. Performance check shows that in the worst case it takes 20 µs to retrieve single vector, pretty good since we are not using any significant amount of RAM.GitHub
OneShotNLP/src/utils/disc_vectors.py at master · generall/OneShotNLP
PyTorch text matching models implementation for One-Shot Named Entity Linking - generall/OneShotNLP