Awesome Metric Learning
The Metric Learning approach to data science problems is heavily underutilized. There are a lot of academic research papers around it but much fewer practical guides and tutorials.
So we decided that we could help people adopt metric learning by collecting related materials in one place.
We are publishing a curated list of awesome practical metric learning tools, libraries, and materials - https://github.com/qdrant/awesome-metric-learning!
This collection aims to put together references to all relevant materials for building your application using Metric Learning.
If you know some exciting article, helpful tool, or a blog post that helped you apply metric learning - feel free to PR your proposal!
The Metric Learning approach to data science problems is heavily underutilized. There are a lot of academic research papers around it but much fewer practical guides and tutorials.
So we decided that we could help people adopt metric learning by collecting related materials in one place.
We are publishing a curated list of awesome practical metric learning tools, libraries, and materials - https://github.com/qdrant/awesome-metric-learning!
This collection aims to put together references to all relevant materials for building your application using Metric Learning.
If you know some exciting article, helpful tool, or a blog post that helped you apply metric learning - feel free to PR your proposal!
GitHub
GitHub - qdrant/awesome-metric-learning: 😎 A curated list of awesome practical Metric Learning and its applications
😎 A curated list of awesome practical Metric Learning and its applications - qdrant/awesome-metric-learning
👍16
Triplet loss - Advanced Intro
Loss functions in metric learning are all chasing the same goal - to make positive pairs closer and negative further.
But the way they achieve this leads to different results and different side effects.
In today's post, we describe the differences between Triplet and Contrastive loss, why the use of Triplet loss can give an advantage, especially in the context of fine-tuning.
It also covers the approach to an efficient implementation of batch-all triplet mining.
Loss functions in metric learning are all chasing the same goal - to make positive pairs closer and negative further.
But the way they achieve this leads to different results and different side effects.
In today's post, we describe the differences between Triplet and Contrastive loss, why the use of Triplet loss can give an advantage, especially in the context of fine-tuning.
It also covers the approach to an efficient implementation of batch-all triplet mining.
👍5🔥1
Metric Learning for Anomaly Detection
Anomaly detection is one of those tasks to which it is challenging to apply classical ML methods directly.
The balancing of normal and abnormal examples and the internal inconsistency of anomalies make classifier training a challenging task.
And the difficulty is often related to data labeling, which in the case of anomalies may not be trivial.
The metric learning approach avoids the explicit separation into classes while combining the advantage of modeling the subject domain with the knowledge of specific anomalous examples.
In our case study, we are solving the problem of estimating the quality of coffee beans ☕️🌱 and determining the type of defects.
We trained Auto-Encoder on unlabeled samples and made fine-tuning on a small fraction of labeled ones.
This approach achieves results equivalent to conventional classification but requires orders of magnitude less labeled data.
Anomaly detection is one of those tasks to which it is challenging to apply classical ML methods directly.
The balancing of normal and abnormal examples and the internal inconsistency of anomalies make classifier training a challenging task.
And the difficulty is often related to data labeling, which in the case of anomalies may not be trivial.
The metric learning approach avoids the explicit separation into classes while combining the advantage of modeling the subject domain with the knowledge of specific anomalous examples.
In our case study, we are solving the problem of estimating the quality of coffee beans ☕️🌱 and determining the type of defects.
We trained Auto-Encoder on unlabeled samples and made fine-tuning on a small fraction of labeled ones.
This approach achieves results equivalent to conventional classification but requires orders of magnitude less labeled data.
qdrant.tech
Metric Learning for Anomaly Detection - Qdrant
Practical use of metric learning for anomaly detection. A way to match the results of a classification-based approach with only ~0.6% of the labeled data.
🔥11👍7❤2
Similarity Learning lacks a framework. So we built one.
Many general-purpose frameworks allow you to train Computer Vision or NLP tasks quickly. However, Similarity Learning has peculiarities, which usually require an additional layer of complexity on top of the usual pipelines.
So, for example, the batch size in the training of similarity models has a much greater role than in other models. Labels either do not exist or are handled in a completely different way. In many cases, the model is already pre-trained, which also adjusts the process.
Developing Similarity Learning models one after another, we began to notice patterns that helped us generalize and bring all our experience with training and fine-tuning such models into one package.
Yesterday we published Quaterion — an open-source, blazing-fast, customizable, scalable framework for training and fine-tuning similarity learning models.
Many general-purpose frameworks allow you to train Computer Vision or NLP tasks quickly. However, Similarity Learning has peculiarities, which usually require an additional layer of complexity on top of the usual pipelines.
So, for example, the batch size in the training of similarity models has a much greater role than in other models. Labels either do not exist or are handled in a completely different way. In many cases, the model is already pre-trained, which also adjusts the process.
Developing Similarity Learning models one after another, we began to notice patterns that helped us generalize and bring all our experience with training and fine-tuning such models into one package.
Yesterday we published Quaterion — an open-source, blazing-fast, customizable, scalable framework for training and fine-tuning similarity learning models.
GitHub
GitHub - qdrant/quaterion: Blazing fast framework for fine-tuning similarity learning models
Blazing fast framework for fine-tuning similarity learning models - qdrant/quaterion
🔥9👍4
This media is not supported in your browser
VIEW IN TELEGRAM
One of the main features of the framework is caching. It allows you to infer large models only once and then use cached vectors during the training. It speeds up the process x100 times, simultaneously allowing you to use batch sizes that are unattainable in other ways.
(gif)
(gif)
👍11🔥2
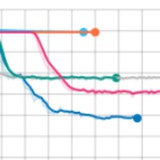
How many layers to fine-tune?
Model fine-tuning allows you to improve the quality of the pre-trained models with just a fraction of the resources spent on training the original model. But there is a trade-off between the number of layers you tune and the precision you get.
Using fewer layers allows for faster training with a larger batch size, while more layers increase the model's capacity.
We've done experiments so you can make more educated choices.
Highlights:
- Training only the head of a model (5% of weights) gives x2 boost on metrics, while full training gives only x3.
- Training only a head layer allows using larger models with bigger batch sizes, compensating for the precision.
- If you only have a small dataset, full model tuning will give a more negligible effect
Model fine-tuning allows you to improve the quality of the pre-trained models with just a fraction of the resources spent on training the original model. But there is a trade-off between the number of layers you tune and the precision you get.
Using fewer layers allows for faster training with a larger batch size, while more layers increase the model's capacity.
We've done experiments so you can make more educated choices.
Highlights:
- Training only the head of a model (5% of weights) gives x2 boost on metrics, while full training gives only x3.
- Training only a head layer allows using larger models with bigger batch sizes, compensating for the precision.
- If you only have a small dataset, full model tuning will give a more negligible effect
👍25❤6😁1
Vector Similaruty beyond Search
Vector similarity offers a range of powerful functions that go far beyond those available in traditional full-text search engines and the conventional kNN search.
We just scratched the surface of the topic but already found a lot of new ways to interact with the data, including:
- Dissimilarity search - that can be applied to anomaly detection, mislabeling detection, and data cleaning.
- Diversity search - that can be used for giving a better overview of the data, with no query at all.
- Recommendations - where we can do beyond the single query vector and use positive and negative examples to find the most relevant items.
- Discovery or Exploration - where we can invert the logic behind triplet-loss to provide real-time improvements of the search results.
In the article, we are talking about a new toolbox for unstructured data exploration, where the search is just one of the instruments.
And maybe you will find there a tool to implement your next big idea 🙂
https://qdrant.tech/articles/vector-similarity-beyond-search/
Vector similarity offers a range of powerful functions that go far beyond those available in traditional full-text search engines and the conventional kNN search.
We just scratched the surface of the topic but already found a lot of new ways to interact with the data, including:
- Dissimilarity search - that can be applied to anomaly detection, mislabeling detection, and data cleaning.
- Diversity search - that can be used for giving a better overview of the data, with no query at all.
- Recommendations - where we can do beyond the single query vector and use positive and negative examples to find the most relevant items.
- Discovery or Exploration - where we can invert the logic behind triplet-loss to provide real-time improvements of the search results.
In the article, we are talking about a new toolbox for unstructured data exploration, where the search is just one of the instruments.
And maybe you will find there a tool to implement your next big idea 🙂
https://qdrant.tech/articles/vector-similarity-beyond-search/
qdrant.tech
Vector Similarity: Going Beyond Full-Text Search | Qdrant - Qdrant
Discover how vector similarity expands data exploration beyond full-text search. Explore diversity sampling and more for enhanced data discovery!
🔥15👍7
Attention all Berliners!
You are invited to our first offline meetup!
Join us for talks on vector search, machine learning, and more.
I will also be participating, providing an overview of Qdrant's progress and future plans.
Still not convinced? We will have free pizza and beer!
The event is scheduled for December 8, 2023, at 18:00, in Berlin.
Please register https://lu.ma/vectorspace.
You are invited to our first offline meetup!
Join us for talks on vector search, machine learning, and more.
I will also be participating, providing an overview of Qdrant's progress and future plans.
Still not convinced? We will have free pizza and beer!
The event is scheduled for December 8, 2023, at 18:00, in Berlin.
Please register https://lu.ma/vectorspace.
Luma
Vector Space: LLM + Vector Databases · Luma
Vector Space Event
We want to celebrate with our friends, colleagues, and partners. Review the passing year, announce upcoming Qdrant Vector Database updates,…
We want to celebrate with our friends, colleagues, and partners. Review the passing year, announce upcoming Qdrant Vector Database updates,…
🔥13👍4❤1
BM42: the next hybrid search baseline
You probably heard that embedding similarity struggles with exact keyword matches, especially when the keyword is a rare word, a name, or some kind of ID.
Usually, this problem is solved by combining the embedding similarity with an exact keyword search like BM25.
However, BM25 relies on pure statistics and has no idea about the meaning of the words.
This works well for large documents, but for short texts and chunks, it's not that great.
We propose a new approach for exact keyword search based on Sparse Vectors and Attention from Transformers.
We can leverage the intelligence of the transformer to score the importance of each word in a sentence,
while still being able to combine it with collection-wide statistics like IDF.
This approach works especially well with the latest release of Qdrant.
It supports hybrid search out of the box, and handles IDF computation for you.
Read more in the article.
You probably heard that embedding similarity struggles with exact keyword matches, especially when the keyword is a rare word, a name, or some kind of ID.
Usually, this problem is solved by combining the embedding similarity with an exact keyword search like BM25.
However, BM25 relies on pure statistics and has no idea about the meaning of the words.
This works well for large documents, but for short texts and chunks, it's not that great.
We propose a new approach for exact keyword search based on Sparse Vectors and Attention from Transformers.
We can leverage the intelligence of the transformer to score the importance of each word in a sentence,
while still being able to combine it with collection-wide statistics like IDF.
This approach works especially well with the latest release of Qdrant.
It supports hybrid search out of the box, and handles IDF computation for you.
Read more in the article.
1🔥17👍8❤3⚡2🏆2💯1
MiniCOIL: Contextualized per-word embeddings
We continue our experiments with unorthodox methods to embed texts.
This time we want to solve the following problems of BM25:
- It can't differentiate homonyms: "bat" as and animal and a baseball "bat" are the same thing for BM25.
- It does loose the information during the stemming process: "information" and "informant" are the same for BM25.
How are we doing this?
Inspired by COIL paper, we generate embeddings per-word.
But instead of relying on learned relevance, which usually fails out of domain, we use learned semantic similarity + stasticical relevance.
We obtain miniCOIL vectors by reducing the dimensionality of the token-level embeddings of the Sentence Transformers.
The whole process luckily doesn't require explicit labels, and we can train it word-by-word on a single CPU.
Read more in our latest article
We continue our experiments with unorthodox methods to embed texts.
This time we want to solve the following problems of BM25:
- It can't differentiate homonyms: "bat" as and animal and a baseball "bat" are the same thing for BM25.
- It does loose the information during the stemming process: "information" and "informant" are the same for BM25.
How are we doing this?
Inspired by COIL paper, we generate embeddings per-word.
But instead of relying on learned relevance, which usually fails out of domain, we use learned semantic similarity + stasticical relevance.
We obtain miniCOIL vectors by reducing the dimensionality of the token-level embeddings of the Sentence Transformers.
The whole process luckily doesn't require explicit labels, and we can train it word-by-word on a single CPU.
Read more in our latest article
👍12❤10😁1👌1
Embeddings Confidence
Let's say we want to know which embeddings are good and which are noisy.
Normally, you can't do this, because embedding model tries to represent the whole variety of objects.
Even if input data is random, it would still match with similar random data.
Using the score threshold is also not a good idea, embedding models were not trained to predict absolute scores,
only relative scores makes sense.
But what if we could make emeddings more like a traditional classifiers, but instead of predicting class,
we would predict presence of some features of the object.
Then, we could apply the very same techniques to estimate confidence of the embeddings - use SoftMax.
An attentive reader will notice that a similar approach has already been discussed on this channel.
But the last the proposed approach involved a full model training.
This time, we only train a light-weight adapter for a ready-made model and dataset.
Tried this approach on a food dataset, encoded with CLIP:
Let's say we want to know which embeddings are good and which are noisy.
Normally, you can't do this, because embedding model tries to represent the whole variety of objects.
Even if input data is random, it would still match with similar random data.
Using the score threshold is also not a good idea, embedding models were not trained to predict absolute scores,
only relative scores makes sense.
But what if we could make emeddings more like a traditional classifiers, but instead of predicting class,
we would predict presence of some features of the object.
Then, we could apply the very same techniques to estimate confidence of the embeddings - use SoftMax.
An attentive reader will notice that a similar approach has already been discussed on this channel.
But the last the proposed approach involved a full model training.
This time, we only train a light-weight adapter for a ready-made model and dataset.
Tried this approach on a food dataset, encoded with CLIP:
❤12❤🔥2🙏1
Relevance Feedback
Did you know that Google search results used to have 👍/👎 buttons?
It was the way to collect signals from users and improve the ranking.
Do you know why you don't see those buttons anymore?
People are either too lazy to click or they abuse the buttons to their advantage.
In 2026, however, real people don't have to rank raw search results anymore - there are all sorts of AI in the middle.
And here we are talking not only about Agents.
From a raw retrieval to a final answer, there are multiple stages of progressively smarter re-ranking models,
each of which refines the result a little bit better than the previous one.
Each of those models also costs a little more than the model in the previous stage.
And so far, the process of re-ranking was linear: for better results, you need to pre-select more candidates.
That means that you pay proportionally more for compute.
Relevance feedback changes this pattern.
Instead of linear re-ranking, you can take feedback information and reiterate the retrieval process to source better candidates.
And for the first time, we implemented a relevance feedback mechanism directly in the vector search engine.
For the same or less number of calls of the expensive model, you can get better results.
And unlike previous methods, we don't need to re-score hundreds of candidates to extract the signal for relevance feedback,
meaning that this approach is efficient enough to be used in real-time applications.
Did you know that Google search results used to have 👍/👎 buttons?
It was the way to collect signals from users and improve the ranking.
Do you know why you don't see those buttons anymore?
People are either too lazy to click or they abuse the buttons to their advantage.
In 2026, however, real people don't have to rank raw search results anymore - there are all sorts of AI in the middle.
And here we are talking not only about Agents.
From a raw retrieval to a final answer, there are multiple stages of progressively smarter re-ranking models,
each of which refines the result a little bit better than the previous one.
Each of those models also costs a little more than the model in the previous stage.
And so far, the process of re-ranking was linear: for better results, you need to pre-select more candidates.
That means that you pay proportionally more for compute.
Relevance feedback changes this pattern.
Instead of linear re-ranking, you can take feedback information and reiterate the retrieval process to source better candidates.
And for the first time, we implemented a relevance feedback mechanism directly in the vector search engine.
For the same or less number of calls of the expensive model, you can get better results.
And unlike previous methods, we don't need to re-score hundreds of candidates to extract the signal for relevance feedback,
meaning that this approach is efficient enough to be used in real-time applications.
3❤4🔥2👏1