What is wrong with this noscript?
Trying to grep an array of strings from a file on a remote server but the noscript does seem to do it, I might be missing quotes or the use of array is wrong here?
PARAMS=(“abc” “xyz” “ijk”)
REMOTEFILE=“pathtoFile”
NODES=(“srv1” “srv2”)
for srv in “${NODES@}”
do
ssh $srv << EOF
grep -f “${PARAMS@}” $REMOTEFILE >/path/remotefile.txt
EOF
done
https://redd.it/10nxxc0
@r_bash
Trying to grep an array of strings from a file on a remote server but the noscript does seem to do it, I might be missing quotes or the use of array is wrong here?
PARAMS=(“abc” “xyz” “ijk”)
REMOTEFILE=“pathtoFile”
NODES=(“srv1” “srv2”)
for srv in “${NODES@}”
do
ssh $srv << EOF
grep -f “${PARAMS@}” $REMOTEFILE >/path/remotefile.txt
EOF
done
https://redd.it/10nxxc0
@r_bash
Reddit
r/bash on Reddit
What is wrong with this noscript?
Cannot backup a directory with tar. When i am trying to run the noscript it says "Cannot stat: No such file or directory". What is the problem? How to resolve it? Or maybe there is some other way to backup a directory. Please help
https://redd.it/10o3h0k
@r_bash
https://redd.it/10o3h0k
@r_bash
Reddit
r/bash on Reddit
Cannot backup a directory with tar. When i am tryi... - No votes and 3 comments
How can I modify this bash command that will also output the content of the given file.
https://redd.it/10o2qi5
@r_bash
https://redd.it/10o2qi5
@r_bash
What is the fastest way to read groups of N lines from stdin / a pipe?
Im trying to figure out a good, efficient and reliable way to read groups of N lines at a time from stdin or (more generally) from a pipe. Id like to accomplish this without needing to save (or wait for) the entire contents of stdin into a variable. So far the only reliable way Ive found to do this involves something like:
nLines=8 # change as needed
while true; do
outCur="$(kk=0; while (( $kk < $nLines )); do read -r </dev/stdin || break; echo "$REPLY"; done)"
[ -z $outCur ] && break || echo "$outCur"
done # | <...>
That said, if reading the entire pipe, there are some options that are much faster than
fgg() { while read -r; do echo "$REPLY"; done | wc -l; }
fhh() { cat | wc -l; }
fii() { head -n $1 | wc -l; }
fjj() { echo "$(</dev/stdin)" | wc -l; }
fkk() { wc -l </dev/stdin; }
fll() { mapfile -t inLines </dev/stdin; printf '%s\n' "${inLines@}" | wc -l; }
fmm() { inLines="$(</dev/stdin)"; echo "${inLines}" | wc -l; }
# note: fll and fmm dont meet the "dont save the full stdin to a variable" criteria
nLines=100000
for fun in fgg fhh "fii $nLines" fjj fkk fll fmm; do
declare -f "${fun% }"
echo
time seq 1 $nLines | $fun
echo
echo '----------------------------------'
echo
done
Which, on my test system, produces
fgg ()
{
while read -r; do
echo "$REPLY";
done | wc -l
}
100000
real 0m5.780s
user 0m3.655s
sys 0m4.306s
----------------------------------
fhh ()
{
cat | wc -l
}
100000
real 0m0.086s
user 0m0.077s
sys 0m0.028s
----------------------------------
fii ()
{
head -n $1 | wc -l
}
100000
real 0m0.085s
user 0m0.107s
sys 0m0.000s
----------------------------------
fjj ()
{
echo "$(</dev/stdin)" | wc -l
}
100000
real 0m0.124s
user 0m0.117s
sys 0m0.039s
----------------------------------
fkk ()
{
wc -l < /dev/stdin
}
1000001
real 0m0.085s
user 0m0.094s
sys 0m0.000s
----------------------------------
fll ()
{
mapfile -t inLines < /dev/stdin;
printf '%s\n' "${inLines[@]}" | wc -l
}
100000
real 0m2.241s
user 0m1.064s
sys 0m2.331s
----------------------------------
fmm ()
{
inLines="$(</dev/stdin)";
echo "${inLines}" | wc -l
}
100000
real 0m0.185s
user 0m0.180s
sys 0m0.039s
This suggests (on my test system) in a worst-case scenario (i.e., many many inputs and most of the time spend looping the `read` command), `read` is about 75x slower than optimal, loading the lines into an array is \~25x slower than optimal (+ more memory usage), and saving the full input into a (non-array) variable is \~2x slower than optimal (+ more memory usage).
From this test, using
seq 1 1000 | {
head -n 10
head -n 10
head -n 10
}
produces
0
1
2
3
4
5
6
7
8
9
284
285
286
287
288
289
290
291
292
293
540
541
542
543
544
545
546
547
548
549
Playing around with different sized input lines suggests that on every subsequent call after the 1st on the same pipe,
Im trying to figure out a good, efficient and reliable way to read groups of N lines at a time from stdin or (more generally) from a pipe. Id like to accomplish this without needing to save (or wait for) the entire contents of stdin into a variable. So far the only reliable way Ive found to do this involves something like:
nLines=8 # change as needed
while true; do
outCur="$(kk=0; while (( $kk < $nLines )); do read -r </dev/stdin || break; echo "$REPLY"; done)"
[ -z $outCur ] && break || echo "$outCur"
done # | <...>
That said, if reading the entire pipe, there are some options that are much faster than
read. I wrote a little speedtest to test a few:fgg() { while read -r; do echo "$REPLY"; done | wc -l; }
fhh() { cat | wc -l; }
fii() { head -n $1 | wc -l; }
fjj() { echo "$(</dev/stdin)" | wc -l; }
fkk() { wc -l </dev/stdin; }
fll() { mapfile -t inLines </dev/stdin; printf '%s\n' "${inLines@}" | wc -l; }
fmm() { inLines="$(</dev/stdin)"; echo "${inLines}" | wc -l; }
# note: fll and fmm dont meet the "dont save the full stdin to a variable" criteria
nLines=100000
for fun in fgg fhh "fii $nLines" fjj fkk fll fmm; do
declare -f "${fun% }"
echo
time seq 1 $nLines | $fun
echo
echo '----------------------------------'
echo
done
Which, on my test system, produces
fgg ()
{
while read -r; do
echo "$REPLY";
done | wc -l
}
100000
real 0m5.780s
user 0m3.655s
sys 0m4.306s
----------------------------------
fhh ()
{
cat | wc -l
}
100000
real 0m0.086s
user 0m0.077s
sys 0m0.028s
----------------------------------
fii ()
{
head -n $1 | wc -l
}
100000
real 0m0.085s
user 0m0.107s
sys 0m0.000s
----------------------------------
fjj ()
{
echo "$(</dev/stdin)" | wc -l
}
100000
real 0m0.124s
user 0m0.117s
sys 0m0.039s
----------------------------------
fkk ()
{
wc -l < /dev/stdin
}
1000001
real 0m0.085s
user 0m0.094s
sys 0m0.000s
----------------------------------
fll ()
{
mapfile -t inLines < /dev/stdin;
printf '%s\n' "${inLines[@]}" | wc -l
}
100000
real 0m2.241s
user 0m1.064s
sys 0m2.331s
----------------------------------
fmm ()
{
inLines="$(</dev/stdin)";
echo "${inLines}" | wc -l
}
100000
real 0m0.185s
user 0m0.180s
sys 0m0.039s
This suggests (on my test system) in a worst-case scenario (i.e., many many inputs and most of the time spend looping the `read` command), `read` is about 75x slower than optimal, loading the lines into an array is \~25x slower than optimal (+ more memory usage), and saving the full input into a (non-array) variable is \~2x slower than optimal (+ more memory usage).
From this test, using
head -n in a loop seems like the obvious optimal answer, but when I try this I get....strange behavior...seq 1 1000 | {
head -n 10
head -n 10
head -n 10
}
produces
0
1
2
3
4
5
6
7
8
9
284
285
286
287
288
289
290
291
292
293
540
541
542
543
544
545
546
547
548
549
Playing around with different sized input lines suggests that on every subsequent call after the 1st on the same pipe,
head -n throws away the 1st kilobyte worth of input lines. Perhaps it is trying to "skip" reading a 1kb pipe header of some sort, but since it isnt at the start of the pipe it throws away data instead? If anyone knows how to stop head -n from doing thisplease let me know. Or if there is some other quick way that I havent tested here please do suggest it.
Thanks in advance.
https://redd.it/10odhbo
@r_bash
Thanks in advance.
https://redd.it/10odhbo
@r_bash
Reddit
r/bash - What is the fastest way to read groups of N lines from stdin / a pipe?
Posted in the bash community.
Random Joke generator
Small bash file to tell a random joke. (100+ available!)
​
\#!/bin/bash
\#mmartin.,29/01/23, Purpose:Print a random joke
awk '
BEGIN{ srand() }
rand() * NR < 1 {
line = $0
}
END { print line }' \~/Documents/VariousTexts/jokes.txt
exit
​
Download from my github
github.com/myklmar/noscripts with jokes.txt file.
https://redd.it/10oc0a4
@r_bash
Small bash file to tell a random joke. (100+ available!)
​
\#!/bin/bash
\#mmartin.,29/01/23, Purpose:Print a random joke
awk '
BEGIN{ srand() }
rand() * NR < 1 {
line = $0
}
END { print line }' \~/Documents/VariousTexts/jokes.txt
exit
​
Download from my github
github.com/myklmar/noscripts with jokes.txt file.
https://redd.it/10oc0a4
@r_bash
GitHub
GitHub - myklmar/noscripts: noscripts, cli tricks,
noscripts, cli tricks, . Contribute to myklmar/noscripts development by creating an account on GitHub.
GitHub - awesome-lists/awesome-bash: A curated list of delightful Bash noscripts and resources.
https://github.com/awesome-lists/awesome-bash
https://redd.it/10ozsm8
@r_bash
https://github.com/awesome-lists/awesome-bash
https://redd.it/10ozsm8
@r_bash
GitHub
GitHub - awesome-lists/awesome-bash: A curated list of delightful Bash noscripts and resources.
A curated list of delightful Bash noscripts and resources. - awesome-lists/awesome-bash
How can I execute bash commands from a string ?
Something like this:
cmd="Hello World! | cat -"
$cmd
https://redd.it/10p316j
@r_bash
Something like this:
cmd="Hello World! | cat -"
$cmd
https://redd.it/10p316j
@r_bash
Reddit
r/bash on Reddit: How can I execute bash commands from a string ?
Posted by u/FinTechno - No votes and no comments
Thank you
I don’t post much but I do lurk around looking to learn. From beginner to expert questions everyone is very helpful. Just wanted to say thank you to the community.
BTW will be cross posting to r/commandline because they are a great community as well.
https://redd.it/10p3tia
@r_bash
I don’t post much but I do lurk around looking to learn. From beginner to expert questions everyone is very helpful. Just wanted to say thank you to the community.
BTW will be cross posting to r/commandline because they are a great community as well.
https://redd.it/10p3tia
@r_bash
Reddit
r/bash - Thank you
Posted in the bash community.
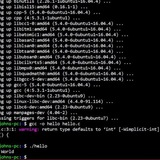
How to filer partial matches that do not end in certain characters
first time posting, forgive me
Basically I want to filter output to go from something like this:
mate-desktop-common
gedit
gedit:i386
to this
mate-desktop-common
gedit:i386
How would I do that?
https://redd.it/10p6duw
@r_bash
first time posting, forgive me
Basically I want to filter output to go from something like this:
mate-desktop-common
gedit
gedit:i386
to this
mate-desktop-common
gedit:i386
How would I do that?
https://redd.it/10p6duw
@r_bash
Reddit
r/bash - How to filer partial matches that do not end in certain characters
Posted in the bash community.
exit terminal without closing the program / headless mode
Hi there!I run this noscript:
The goal is to open weston, which will start waydroid in that window size. Everything works fine, but I'd like to hide or exit the terminal and only show the weston window. (Like headless mode)? How could I achieve this?
https://redd.it/10pd91w
@r_bash
Hi there!I run this noscript:
#! /bin/sh. waydroid session stop weston --width=555 --height=875 -Swayland-droid & WAYLAND_DISPLAY=wayland-droid waydroid show-full-uiThe goal is to open weston, which will start waydroid in that window size. Everything works fine, but I'd like to hide or exit the terminal and only show the weston window. (Like headless mode)? How could I achieve this?
https://redd.it/10pd91w
@r_bash
Reddit
r/bash on Reddit: exit terminal without closing the program / headless mode
Posted by u/crepuscopoli - No votes and no comments
How do you copy the folder structure of a folder and paste it in a new folder?
How do you copy the folder structure of a folder and paste it in a new folder? I have a folder with a lot of subfolders that contains a lot of subfolders, and I would like to copy the folder structure so I don't have to do it manually. Is there any command for this?
https://redd.it/10ppmtr
@r_bash
How do you copy the folder structure of a folder and paste it in a new folder? I have a folder with a lot of subfolders that contains a lot of subfolders, and I would like to copy the folder structure so I don't have to do it manually. Is there any command for this?
https://redd.it/10ppmtr
@r_bash
Reddit
r/bash - How do you copy the folder structure of a folder and paste it in a new folder?
Posted in the bash community.
Print just first lines beginning with "> " via sed doesn't work
Hi! Here is my input file:
#
> Check file types and compare values
> Returns 0 if the condition evaluates to true, 1 if it evaluates to false
> More information: https://www.gnu.org/software/bash/manual/bash.html#index-test
- Test if a given variable [is equal/not equal to the specified string:
Here is my noscript:
#!/usr/bin/env bash
declare file="/home/emilyseville7cfg/Documents/mine/other/cli-pages/common/.btldr"
sed -nE '/^>/ {
h
:denoscription
N
H
/> (Aliases|See also|More information):/! bdenoscription
s/^.*\n//
x
p
Q
}' "$file"
I wanna print just all lines beginning with `> ` but not including `(Aliases|See also|More information):` at the beginning. I expect such lines to be in the pattern buffer at the end of the noscript but surprisingly I get this output:
> Check file types and compare values
> Check file types and compare values
> Returns 0 if the condition evaluates to true, 1 if it evaluates to false
> Check file types and compare values
> Returns 0 if the condition evaluates to true, 1 if it evaluates to false
> More information: https://www.gnu.org/software/bash/manual/bash.html#index-test
Note that hold space should contain `> More information: https://www.gnu.org/software/bash/manual/bash.html#index-test` at the end of the noscript.
My idea was to condense all lines starting with an angle bracket in the pattern space excluding the last one containing `(Aliases|See also|More information):`. What am I missing to implement what I want?
[https://redd.it/10pwd8q
@r_bash
Hi! Here is my input file:
#
> Check file types and compare values
> Returns 0 if the condition evaluates to true, 1 if it evaluates to false
> More information: https://www.gnu.org/software/bash/manual/bash.html#index-test
- Test if a given variable [is equal/not equal to the specified string:
[ "${string value: variable}" {string value: ==|!=} "{string value: string}" ]Here is my noscript:
#!/usr/bin/env bash
declare file="/home/emilyseville7cfg/Documents/mine/other/cli-pages/common/.btldr"
sed -nE '/^>/ {
h
:denoscription
N
H
/> (Aliases|See also|More information):/! bdenoscription
s/^.*\n//
x
p
Q
}' "$file"
I wanna print just all lines beginning with `> ` but not including `(Aliases|See also|More information):` at the beginning. I expect such lines to be in the pattern buffer at the end of the noscript but surprisingly I get this output:
> Check file types and compare values
> Check file types and compare values
> Returns 0 if the condition evaluates to true, 1 if it evaluates to false
> Check file types and compare values
> Returns 0 if the condition evaluates to true, 1 if it evaluates to false
> More information: https://www.gnu.org/software/bash/manual/bash.html#index-test
Note that hold space should contain `> More information: https://www.gnu.org/software/bash/manual/bash.html#index-test` at the end of the noscript.
My idea was to condense all lines starting with an angle bracket in the pattern space excluding the last one containing `(Aliases|See also|More information):`. What am I missing to implement what I want?
[https://redd.it/10pwd8q
@r_bash
www.gnu.org
Bash Features ¶
Next: Introduction, Previous: (dir), Up: (dir) [Contents][Index]
Can I do -this- using a bash noscript?
I have a fee Lua driver files that use libraries. I need to provide context for any use of these libraries in the file so that all the logic is contained in one file. Can I accomplish that using a bash noscript? All files will be stored locally.
https://redd.it/10qdrc8
@r_bash
I have a fee Lua driver files that use libraries. I need to provide context for any use of these libraries in the file so that all the logic is contained in one file. Can I accomplish that using a bash noscript? All files will be stored locally.
https://redd.it/10qdrc8
@r_bash
Reddit
r/bash - Can I do -this- using a bash noscript?
Posted in the bash community.
Bash noscript to invoke conda environment
I'm trying to write a bash noscript for executing a set of commands to activate my conda env
#!/bin/csh
source ~/.cshrc
module load anaconda3/4.2.0
source <path>/conda.csh
conda activate myenv1
however post the noscript execution, I expect myenv1 to be activated but that fails to happen, why is that? and what can I do to fix it?
https://redd.it/10qn164
@r_bash
I'm trying to write a bash noscript for executing a set of commands to activate my conda env
#!/bin/csh
source ~/.cshrc
module load anaconda3/4.2.0
source <path>/conda.csh
conda activate myenv1
however post the noscript execution, I expect myenv1 to be activated but that fails to happen, why is that? and what can I do to fix it?
https://redd.it/10qn164
@r_bash
Reddit
r/bash - Bash noscript to invoke conda environment
Posted in the bash community.
I can run a program even though it's not in my current directory, and is not found when I use the
I wrote a bash noscript a few weeks ago and could have sworn I put it in my ~/bin/ folder. Yesterday, I wanted to use the noscript but forgot the name of it, so I perused ~/bin/ to refresh my memory. I couldn't find it! So instead, I searched my history to find the name of the noscript. It's not in ~/bin/, so I used
How can I find the location of this noscript? And why isn't it showing up when I try to find it with
https://redd.it/10qwod7
@r_bash
which command. Where the heck is my program??I wrote a bash noscript a few weeks ago and could have sworn I put it in my ~/bin/ folder. Yesterday, I wanted to use the noscript but forgot the name of it, so I perused ~/bin/ to refresh my memory. I couldn't find it! So instead, I searched my history to find the name of the noscript. It's not in ~/bin/, so I used
which <noscript_name> to find it... but nothing was found! I thought that maybe I deleted the noscript by mistake somehow, but then I noticed that when I typed part of the noscript name it would auto-complete with tab. I tried to run it, and it works! But I have no idea where the heck this noscript even is, so that I can update it!How can I find the location of this noscript? And why isn't it showing up when I try to find it with
which?https://redd.it/10qwod7
@r_bash
Reddit
r/bash on Reddit
I can run a program even though it's not in my cur... - No votes and 1 comment