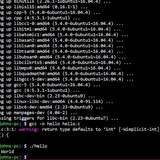
Diff 2 Files Without Knowing Exact Names
I want to diff two files, but I do not know the exact names.
The use case is, we are using DevOps pipelines that download a pre and post configuration file.
I would know what the files start with but the ending will be a date time string that I would not know.
Looking for help with a noscript that finds the files and does a diff of the later version vs the earlier version.
Names would be something like this:
name20230302T142605
name20230302T142803
Any thoughts on how to do this?
https://redd.it/11gauho
@r_bash
I want to diff two files, but I do not know the exact names.
The use case is, we are using DevOps pipelines that download a pre and post configuration file.
I would know what the files start with but the ending will be a date time string that I would not know.
Looking for help with a noscript that finds the files and does a diff of the later version vs the earlier version.
Names would be something like this:
name20230302T142605
name20230302T142803
Any thoughts on how to do this?
https://redd.it/11gauho
@r_bash
Reddit
r/bash on Reddit: Diff 2 Files Without Knowing Exact Names
Posted by u/pedrotheterror - No votes and no comments
Download Toddle for FREE: Toddler is a bash noscript that extracts all the TODO comments across your codebase into a markdown file.
https://github.com/Madjarx/toddler
https://redd.it/11ga9gb
@r_bash
https://github.com/Madjarx/toddler
https://redd.it/11ga9gb
@r_bash
GitHub
GitHub - Madjarx/toddler: Toddler is a bash noscript that extracts all the TODO comments acoss your codebase into a markdown file.
Toddler is a bash noscript that extracts all the TODO comments acoss your codebase into a markdown file. - GitHub - Madjarx/toddler: Toddler is a bash noscript that extracts all the TODO comments acoss...
Worked a lot on this noscript lately
I would like to share a noscript that I think can be quite useful for people who play games in DOSBox, or want to extract the OST from games (works with console games too that use CD audio). All that's required is to pass the CUE file as an argument to the noscript.
​
https://github.com/linux4ever07/noscripts/blob/main/cuebin\_extract.sh
​
I linked it before as part of a collective post about a bunch of my noscripts. Since I made that post, I've spent a lot of time refining everything so my noscripts can reach their 'final form'. The goal is to have them in such a state that I could die tomorrow and they will keep working indefinitely, and be easy to understand and maintain should people need to.
​
This specific noscript seems to be the last of the bunch to get its 'final makeover'. I might still update it, but I don't think I will change it a whole lot more. The one thing that comes to mind is to add support for additional audio formats, like Opus, MP3 etc. The reason I didn't add it myself yet is because I'm not interested. I always just use FLAC, and Ogg Vorbis is there as a lossy option. DOSBox supports Opus though, so maybe someone will be interested in forking the noscript and adding that, I don't know.
​
Listing the top comments of the noscript below, to elaborate on how it works:
​
\# This noscript is meant to take an input BIN/CUE file, extract the raw
\# track(s) (data / audio) in whatever format the user has specified
\# through noscript arguments. The noscript simply separates all the tracks
\# of BIN/CUE files.
​
\# Available audio formats are:
\# * cdr (native CD audio)
\# * ogg (Ogg Vorbis)
\# * flac (Free Lossless Audio Codec)
​
\# If no format is specified as an argument, the noscript will extract all
\# 3 formats, and create CUE sheets for all 3 formats as well.
​
\# The original purpose of the noscript is to take DOS games that have CD
\# audio, and getting rid of the need to store the uncompressed audio.
\# Ogg Vorbis is a lossy codec, so the files are much smaller and near
\# the same quality. In the case of FLAC, it's a lossless format so the
\# quality is identical to native CD audio. The only difference is FLAC
\# is losslessly compressed so the files are slightly smaller. The
\# generated CUE sheets can be used with DOSBox, using the 'IMGMOUNT'
\# command.
​
\# https://www.dosbox.com/wiki/IMGMOUNT
​
\# Another use case for this noscript is to simply extract the OST from
\# games, to listen to.
​
\# The noscript will work with all kinds of games, including PS1 and Sega
\# Saturn games. All that's required is that the disc image is in the
\# BIN/CUE format. Though, I'm not sure if there's emulators that can
\# handle FLAC or Ogg Vorbis tracks. The point would mainly be to listen
\# to the music.
​
\# Yet another use case is to just split a BIN/CUE into its separate
\# tracks, with the '-cdr' argument, without encoding the audio.
​
\# It's possible to do a byteswap on the audio tracks (to switch the
\# endianness / byte order), through the optional '-byteswap' argument.
\# This is needed in some cases, or audio tracks will be white noise if
\# the endianness is wrong. So, it's easy to tell whether or not the byte
\# order is correct.
​
\# ISO files produced by 'bchunk' are discarded, and data tracks are
\# instead copied directly from the source BIN file, calculating the
\# length of tracks based on information gathered from the CUE sheet.
​
\# Since the 'copy_track' function is now able to correctly copy any
\# track from the source BIN file, it's possible to make this noscript not
\# depend on 'bchunk' anymore. The default mode is to use 'bchunk', but
\# if the user passes the '-sox' argument to the noscript, then 'sox' is
\# used instead. The end result is identical either way. It's just nice
\# to have a way out, in
I would like to share a noscript that I think can be quite useful for people who play games in DOSBox, or want to extract the OST from games (works with console games too that use CD audio). All that's required is to pass the CUE file as an argument to the noscript.
​
https://github.com/linux4ever07/noscripts/blob/main/cuebin\_extract.sh
​
I linked it before as part of a collective post about a bunch of my noscripts. Since I made that post, I've spent a lot of time refining everything so my noscripts can reach their 'final form'. The goal is to have them in such a state that I could die tomorrow and they will keep working indefinitely, and be easy to understand and maintain should people need to.
​
This specific noscript seems to be the last of the bunch to get its 'final makeover'. I might still update it, but I don't think I will change it a whole lot more. The one thing that comes to mind is to add support for additional audio formats, like Opus, MP3 etc. The reason I didn't add it myself yet is because I'm not interested. I always just use FLAC, and Ogg Vorbis is there as a lossy option. DOSBox supports Opus though, so maybe someone will be interested in forking the noscript and adding that, I don't know.
​
Listing the top comments of the noscript below, to elaborate on how it works:
​
\# This noscript is meant to take an input BIN/CUE file, extract the raw
\# track(s) (data / audio) in whatever format the user has specified
\# through noscript arguments. The noscript simply separates all the tracks
\# of BIN/CUE files.
​
\# Available audio formats are:
\# * cdr (native CD audio)
\# * ogg (Ogg Vorbis)
\# * flac (Free Lossless Audio Codec)
​
\# If no format is specified as an argument, the noscript will extract all
\# 3 formats, and create CUE sheets for all 3 formats as well.
​
\# The original purpose of the noscript is to take DOS games that have CD
\# audio, and getting rid of the need to store the uncompressed audio.
\# Ogg Vorbis is a lossy codec, so the files are much smaller and near
\# the same quality. In the case of FLAC, it's a lossless format so the
\# quality is identical to native CD audio. The only difference is FLAC
\# is losslessly compressed so the files are slightly smaller. The
\# generated CUE sheets can be used with DOSBox, using the 'IMGMOUNT'
\# command.
​
\# https://www.dosbox.com/wiki/IMGMOUNT
​
\# Another use case for this noscript is to simply extract the OST from
\# games, to listen to.
​
\# The noscript will work with all kinds of games, including PS1 and Sega
\# Saturn games. All that's required is that the disc image is in the
\# BIN/CUE format. Though, I'm not sure if there's emulators that can
\# handle FLAC or Ogg Vorbis tracks. The point would mainly be to listen
\# to the music.
​
\# Yet another use case is to just split a BIN/CUE into its separate
\# tracks, with the '-cdr' argument, without encoding the audio.
​
\# It's possible to do a byteswap on the audio tracks (to switch the
\# endianness / byte order), through the optional '-byteswap' argument.
\# This is needed in some cases, or audio tracks will be white noise if
\# the endianness is wrong. So, it's easy to tell whether or not the byte
\# order is correct.
​
\# ISO files produced by 'bchunk' are discarded, and data tracks are
\# instead copied directly from the source BIN file, calculating the
\# length of tracks based on information gathered from the CUE sheet.
​
\# Since the 'copy_track' function is now able to correctly copy any
\# track from the source BIN file, it's possible to make this noscript not
\# depend on 'bchunk' anymore. The default mode is to use 'bchunk', but
\# if the user passes the '-sox' argument to the noscript, then 'sox' is
\# used instead. The end result is identical either way. It's just nice
\# to have a way out, in
GitHub
noscripts/cuebin_extract.sh at main · linux4ever07/noscripts
A collection of noscripts that I've written and refined over the years - noscripts/cuebin_extract.sh at main · linux4ever07/noscripts
case a certain program is not available.
​
\# The advantage of using the '-sox' argument, is that the noscript is then
\# able to process CUE sheets that contain multiple FILE commands (list
\# multiple BIN files). As an example, Redump will use 1 BIN file /
\# track, so that can be processed by the noscript directly in this case,
\# without having to merge the BIN/CUE first.
​
\# It may also be possible to use 'ffmpeg' in a similar way to how 'sox'
\# is used in the 'cdr2wav' function. But I did not manage to get it
\# working. The command would probably be something like this:
​
\# ffmpeg -i in.cdr -ar 44.1k -ac 2 -f pcm_s16le out.wav
​
​
https://preview.redd.it/325rj5fpzdla1.png?width=2560&format=png&auto=webp&v=enabled&s=c46a6f02733b6b18d1077925dbd99477cd134985
https://redd.it/11gd8rf
@r_bash
​
\# The advantage of using the '-sox' argument, is that the noscript is then
\# able to process CUE sheets that contain multiple FILE commands (list
\# multiple BIN files). As an example, Redump will use 1 BIN file /
\# track, so that can be processed by the noscript directly in this case,
\# without having to merge the BIN/CUE first.
​
\# It may also be possible to use 'ffmpeg' in a similar way to how 'sox'
\# is used in the 'cdr2wav' function. But I did not manage to get it
\# working. The command would probably be something like this:
​
\# ffmpeg -i in.cdr -ar 44.1k -ac 2 -f pcm_s16le out.wav
​
​
https://preview.redd.it/325rj5fpzdla1.png?width=2560&format=png&auto=webp&v=enabled&s=c46a6f02733b6b18d1077925dbd99477cd134985
https://redd.it/11gd8rf
@r_bash
Cannot pipe the output to a file
Hey guys. I am writing a noscript to provision a VM on Oracle Cloud. This Bash noscript is running on Ubuntu. The command themselves are working fine. I want to log the output to a file. I tried but nothing is being logged.
The output for this Oracle command takes about 5 minutes to come through. My guess is that the "tee" command is not waiting around for the output and it times out. How can I make it wait so it will log the output?
https://redd.it/11guy2f
@r_bash
Hey guys. I am writing a noscript to provision a VM on Oracle Cloud. This Bash noscript is running on Ubuntu. The command themselves are working fine. I want to log the output to a file. I tried but nothing is being logged.
The output for this Oracle command takes about 5 minutes to come through. My guess is that the "tee" command is not waiting around for the output and it times out. How can I make it wait so it will log the output?
#!/bin/bashecho -e "#######################################################################" >> /home/ubuntu/OCIprovision.logdate >> /home/ubuntu/OCIprovision.logoci compute instance launch \--availability-domain $A \--compartment-id $C \--shape VM.Standard.A1.Flex \--subnet-id $S \--assign-private-dns-record true \--assign-public-ip true \--availability-config file:///home/ubuntu/availabilityConfig.json \--display-name NEW-autoprovisioned \--image-id $I \--instance-options file:///home/ubuntu/instanceOptions.json \--shape-config file:///home/ubuntu/shapeConfig.json \--ssh-authorized-keys-file /home/ubuntu/.ssh/id_rsa.pub \--| tee -a /home/ubuntu/OCIprovision.loghttps://redd.it/11guy2f
@r_bash
Reddit
r/bash on Reddit: Cannot pipe the output to a file
Posted by u/kavee9 - No votes and no comments
Command to grab piece of text from somewhere
I just need some random small text. Maybe there are sites that store text pieces for such purposes? Why do I need it? Well, I wanna write a program to demonstrate how Linux commands work in practice by showing some grabbed input text on the left and transformed output on the right side with visual highlighted differences via smth like ydiff.
https://redd.it/11hdeyp
@r_bash
I just need some random small text. Maybe there are sites that store text pieces for such purposes? Why do I need it? Well, I wanna write a program to demonstrate how Linux commands work in practice by showing some grabbed input text on the left and transformed output on the right side with visual highlighted differences via smth like ydiff.
https://redd.it/11hdeyp
@r_bash
Reddit
r/bash on Reddit: Command to grab piece of text from somewhere
Posted by u/EmilySeville7cfg - No votes and no comments
Sshto update
Hi, sshto is getting better and better each time)
I've added hosts selection from groups and added 'CONTENTS' button in commands section to fast jump to other groups. Now you can merge groups with ease!
Enjoy!)
https://redd.it/11hetsr
@r_bash
Hi, sshto is getting better and better each time)
I've added hosts selection from groups and added 'CONTENTS' button in commands section to fast jump to other groups. Now you can merge groups with ease!
Enjoy!)
https://redd.it/11hetsr
@r_bash
GitHub
GitHub - vaniacer/sshto: Small bash noscript to manage your ssh connections. It builds menu (via dialog) from your ~/.ssh/config.…
Small bash noscript to manage your ssh connections. It builds menu (via dialog) from your ~/.ssh/config. It can not only connect but also to run commands, copy files, tunnel ports. - vaniacer/sshto
Tip to translate random languages with ChatGPT and tell which language is used in a text box
https://www.reddit.com/r/ChatGPT/comments/11hk3cc/tipuseakeyboardcomboshortcuttotranslatea/
https://redd.it/11hkens
@r_bash
https://www.reddit.com/r/ChatGPT/comments/11hk3cc/tipuseakeyboardcomboshortcuttotranslatea/
https://redd.it/11hkens
@r_bash
Reddit
r/ChatGPT on Reddit: Tip: use a keyboard combo shortcut to translate a text from random language, translate and tell which language…
Posted by u/GillesQuenot - No votes and 1 comment
Need some help with bash to combine two lists
I have two lists (List-1 and List-2) as shown below.
How would I combine them two by corresponding volume id (see my desired output)
​
echo $LIST1
/dev/nvme0n1:vol020dae210a89ec02f
/dev/nvme1n1:vol04a2ddeb86823787a
/dev/nvme2n1:vol0e87fd7996e425e4c
/dev/nvme3n1:vol00835963bde10321b
echo $LIST2
/dev/sda1:vol020dae210a89ec02f
/dev/sdb:vol0e87fd7996e425e4c
/dev/sdf:vol04a2ddeb86823787a
/dev/sdg:vol00835963bde10321b
​
Desired output:
echo $OUTPUT
/dev/nvme0n1:/dev/sda1
/dev/nvme1n1:/dev/sdf
/dev/nvme2n1:/dev/sdb
/dev/nvme3n1:/dev/sdg
Appreciate your help ! Cheers !
https://redd.it/11hq0my
@r_bash
I have two lists (List-1 and List-2) as shown below.
How would I combine them two by corresponding volume id (see my desired output)
​
echo $LIST1
/dev/nvme0n1:vol020dae210a89ec02f
/dev/nvme1n1:vol04a2ddeb86823787a
/dev/nvme2n1:vol0e87fd7996e425e4c
/dev/nvme3n1:vol00835963bde10321b
echo $LIST2
/dev/sda1:vol020dae210a89ec02f
/dev/sdb:vol0e87fd7996e425e4c
/dev/sdf:vol04a2ddeb86823787a
/dev/sdg:vol00835963bde10321b
​
Desired output:
echo $OUTPUT
/dev/nvme0n1:/dev/sda1
/dev/nvme1n1:/dev/sdf
/dev/nvme2n1:/dev/sdb
/dev/nvme3n1:/dev/sdg
Appreciate your help ! Cheers !
https://redd.it/11hq0my
@r_bash
Reddit
r/bash on Reddit: Need some help with bash to combine two lists
Posted by u/BlueAcronis - No votes and 2 comments
Odd behavior with reading from stdin and then trying to read user input in a while loop
I successfully made a bash noscript that would make a centered list of files (images) then let you select an image interactively and it would display whatever image you would currently have selected, in the terminal using an image viewer.
It works well if I assign the array from within the bash noscript with
names=(fd . /home/sweet/Pictures/icons --extension jpg)
and then I would read the user input in a while loop that would let me move through the array in increments to select different files/images using 'j' or 'k'.
the problem Im having is that I want to be able to use any command and pipe it into my bash noscript but no matter which method I try, it blocks the user keys/input from being read. I've spent 5 hours trying every suggestion online that I could find and reading man pages but to no avail. Most of them would "work" to assign the piped in files to the array but then everytime I hit j or k it would just show up on the screen literally as an ascii character instead of catching the case statement and triggering the function to move up/down through the array, display the image and return to drawing the screen.
I tried simple things like names=$(cat) or
and "readarray -t names"
I also tried to take stdin, write it to a file and then read that file into the array. Below is the full code with some things commented out that I tried
Im trying to achieve a fzf like behavior where I can pipe images into the noscript, display them and then pick on option. Any suggestions as to how I can prevent read/stdin from blocking the ability to read user input would be amazing.
https://redd.it/11imlvv
@r_bash
I successfully made a bash noscript that would make a centered list of files (images) then let you select an image interactively and it would display whatever image you would currently have selected, in the terminal using an image viewer.
It works well if I assign the array from within the bash noscript with
names=(fd . /home/sweet/Pictures/icons --extension jpg)
and then I would read the user input in a while loop that would let me move through the array in increments to select different files/images using 'j' or 'k'.
the problem Im having is that I want to be able to use any command and pipe it into my bash noscript but no matter which method I try, it blocks the user keys/input from being read. I've spent 5 hours trying every suggestion online that I could find and reading man pages but to no avail. Most of them would "work" to assign the piped in files to the array but then everytime I hit j or k it would just show up on the screen literally as an ascii character instead of catching the case statement and triggering the function to move up/down through the array, display the image and return to drawing the screen.
I tried simple things like names=$(cat) or
names=()
while read -r line; do
names+=( "$line" )
done < "${1:-/dev/stdin}"
and "readarray -t names"
I also tried to take stdin, write it to a file and then read that file into the array. Below is the full code with some things commented out that I tried
Im trying to achieve a fzf like behavior where I can pipe images into the noscript, display them and then pick on option. Any suggestions as to how I can prevent read/stdin from blocking the ability to read user input would be amazing.
\#!/bin/bash
# move selection up
up() {
if [ ${current} -gt 0 ]; then
current=$((current-1))
fi
tui
}
# move selection down
down () {
if [ ${current} -lt $((length-1)) ]; then
current=$((current+1))
fi
tui
}
# kitty
o() {
kitty +kitten icat --scale-up --place 50x50@0x0 "${names[$current]}"
}
get_term_size() {
read -r LINES COLUMNS < <(stty size)
}
indent() {
for i in $(seq 1 $1); do printf ' '; done
}
# note this didnt work
# read from stdin by default unless there is an argument in pos 1
# names=()
# while read -r line; do
# assign each item from stdin to the array
# names+=( "$line" )
# done < "${1:-/dev/stdin}"
# This works by itself
# names=($(fd . /home/sweet/Pictures/anime-icons --extension jpg))
# length=${#names[@]}
tui() {
clear
for (( n=0; n < ${#names[*]}; n++ )); do
# n is the iterator, get word length and subtract by column size to center
wordlength=${#names[n]}
move_to=$(( $(( COLUMNS / 2)) - $(( wordlength / 2 )) ))
indent $move_to
if [ ${n} -eq ${current} ]; then
for i in $(seq 1 $wordlength); do printf '─'; done
printf '\n'
indent $move\_to
printf "\\033\[1m${names\[n\]}\\033\[0m\\n"
indent $move\_to
for i in $(seq $wordlength); do printf '─'; done
printf '\n'
else
printf "${names\[n\]}\\n"
fi
done
}
# quit program
q() {
quit='true'
clear
printf '\e[?25h'
}
​
ctrl_c() {
clear
printf '\e[?25h'
exit
}
# get terminal size
get_term_size
# init variable for list index
current=0
# keep track of quit
quit='false'
# STDIN
names=$(cat)
length=${#names\[@\]}
# hide the cursor
printf '\e[?25l'
# init input list/array
tui
# main event loop
while [ ${quit} != 'true' ]; do
# trap ctrl+c to unhide cursor and reset terminal
trap ctrl_c INT
# take input from user
read -sn 1 key
case "$key" in
'k') up;o;;
'j') down;o;;
'o') o;;
'q') q;;
esac
done
https://redd.it/11imlvv
@r_bash
Reddit
r/bash on Reddit: Odd behavior with reading from stdin and then trying to read user input in a while loop
Posted by u/SweetBabyAlaska - No votes and no comments
I wrote a wallpaper getter setter in pure BASH v4.2+
https://github.com/wick3dr0se/wgs
https://redd.it/11inv00
@r_bash
https://github.com/wick3dr0se/wgs
https://redd.it/11inv00
@r_bash
GitHub
GitHub - wick3dr0se/wgs: A minimal wallpaper getter setter written in pure BASH
A minimal wallpaper getter setter written in pure BASH - GitHub - wick3dr0se/wgs: A minimal wallpaper getter setter written in pure BASH
Help! Urgent!
Hello everyone
I am trying to solve some bash noscript questions and need some help urgently as I have a deadline to meet in a few hours. Please dm if anyone can help me solve those questions. Would love to interact and learn
https://redd.it/11jfcfx
@r_bash
Hello everyone
I am trying to solve some bash noscript questions and need some help urgently as I have a deadline to meet in a few hours. Please dm if anyone can help me solve those questions. Would love to interact and learn
https://redd.it/11jfcfx
@r_bash
Reddit
r/bash on Reddit: Help! Urgent!
Posted by u/contentkumpo - No votes and no comments
Getting file path from an android device
I'm looking for a way to get the internal android path of an SD card from a device and assign it to a variable in bash.
For instance, when I browse my device connected to my pc, the entire working path is something like:
When browsing the same directory from the phone, it appears as
As far as I can figure out (which probably isn't very far), there doesn't seem to be a way to list the latter path from the pc. So far I've been manually typing it into my noscript, but that's a terribly inefficient way to go about things, especially since the number (some sort of UID?) changes whenever the device is power cycled or the media is removed.
Any suggestions on how to retrieve the internal path for such detachable media via bash?
https://redd.it/11jjl5d
@r_bash
I'm looking for a way to get the internal android path of an SD card from a device and assign it to a variable in bash.
For instance, when I browse my device connected to my pc, the entire working path is something like:
/run/user/1000/gvfs/mtp:host=motorola_Z38948/SanDisk SD card/TunesWhen browsing the same directory from the phone, it appears as
/storage/9028-e980-z73899-987/TunesAs far as I can figure out (which probably isn't very far), there doesn't seem to be a way to list the latter path from the pc. So far I've been manually typing it into my noscript, but that's a terribly inefficient way to go about things, especially since the number (some sort of UID?) changes whenever the device is power cycled or the media is removed.
Any suggestions on how to retrieve the internal path for such detachable media via bash?
https://redd.it/11jjl5d
@r_bash
Reddit
r/bash on Reddit: Getting file path from an android device
Posted by u/watermelonspanker - No votes and no comments
Do you use bash at/for your work?
New to this, just curious as to what some of you use it for besides personal projects.
https://redd.it/11jtqfu
@r_bash
New to this, just curious as to what some of you use it for besides personal projects.
https://redd.it/11jtqfu
@r_bash
Reddit
r/bash on Reddit: Do you use bash at/for your work?
Posted by u/gaslight_blues - No votes and no comments
bash issue with ip command
hi guys, i am trying to write a bash noscript that i will assign later to an alias, to output easier ip eth0 and eth0 ip (for openvpn)
the code looks good to me and work when both eth0 and tun0 are enabled but dont when tun0 is disabled
it output something i didnt ask for and should just change the eth0 output to "disabled" instead of being blank
ideas and help would be nice, thanks yall
https://preview.redd.it/ut9x13eed3ma1.png?width=821&format=png&auto=webp&v=enabled&s=9273f918bb620f17010feaf7b72130ae140cd4b5
https://preview.redd.it/dkmyu4ofd3ma1.png?width=457&format=png&auto=webp&v=enabled&s=992ef304e62f96e904be2aca73714b1d455eafbd
https://redd.it/11junh7
@r_bash
hi guys, i am trying to write a bash noscript that i will assign later to an alias, to output easier ip eth0 and eth0 ip (for openvpn)
the code looks good to me and work when both eth0 and tun0 are enabled but dont when tun0 is disabled
it output something i didnt ask for and should just change the eth0 output to "disabled" instead of being blank
ideas and help would be nice, thanks yall
https://preview.redd.it/ut9x13eed3ma1.png?width=821&format=png&auto=webp&v=enabled&s=9273f918bb620f17010feaf7b72130ae140cd4b5
https://preview.redd.it/dkmyu4ofd3ma1.png?width=457&format=png&auto=webp&v=enabled&s=992ef304e62f96e904be2aca73714b1d455eafbd
https://redd.it/11junh7
@r_bash
Where can I learn to use NNN as a noob?
What's a good tutorial on nnn for Mac. I'm a terminal noob, and installed the program. It's really fast and I love it for zipping around my folders and doing basic tasks. I've not managed to get previews however. I've spent quite some hours now with ChatGTP to get help but I mostly get inadequate, conflicting, or plainly wrong instructions. The learning curve is steep here as I'm looking at the instructions for installing preview-tui, and I can't quite get my head around it.
This is probably not the right forum for asking, but perhaps someone on here can point me in the right direction? Where can I get help with this stuff? Any advice would be appreciated.
Thanks.
https://redd.it/11kauu4
@r_bash
What's a good tutorial on nnn for Mac. I'm a terminal noob, and installed the program. It's really fast and I love it for zipping around my folders and doing basic tasks. I've not managed to get previews however. I've spent quite some hours now with ChatGTP to get help but I mostly get inadequate, conflicting, or plainly wrong instructions. The learning curve is steep here as I'm looking at the instructions for installing preview-tui, and I can't quite get my head around it.
This is probably not the right forum for asking, but perhaps someone on here can point me in the right direction? Where can I get help with this stuff? Any advice would be appreciated.
Thanks.
https://redd.it/11kauu4
@r_bash
Reddit
r/bash on Reddit: Where can I learn to use NNN as a noob?
Posted by u/unreluctant - No votes and 2 comments
Trying to use inotify + cp to move file upon creation.. cp can't reach source
Script:
#!/bin/sh
source='/var/lib/awx/projects/_*/files/'
dest='/var/lib/awx/proj_dep_files'
inotifywait -m --event create,modify,delete /var/lib/awx/projects/_*/files/ --format %w%f | while read path file; do
cp -f $path /var/lib/awx/proj_dep_files/
done
Error:
Setting up watches.
Watches established.
cp: cannot stat '/var/lib/awx/projects/_33__aap_repo/files/RPM-GPG-Key-cisco-amp': No such file or directory
cp: cannot stat '/var/lib/awx/projects/_33__aap_repo/files/debsig_policy': No such file or directory
cp: cannot stat '/var/lib/awx/projects/_33__aap_repo/files/sftd.yaml.j2': No such file or directory
cp: cannot stat '/var/lib/awx/projects/_33__aap_repo/files/snmpd.conf': No such file or directory
Now source and dest have been verified a few times.. perms on source and dest = are 777.I did try just an 'echo $path $file' earlier and the value of $path is the full /dir/path/to/file.name
​
And I can run the inotify and cp parts manually and they work so I'm totally struggle bussing it on this.
​
EDIT: I realize the source and dest variables arent doing anything.. with them I get the same error. This was one iteration of testing.
https://redd.it/11kgfau
@r_bash
Script:
#!/bin/sh
source='/var/lib/awx/projects/_*/files/'
dest='/var/lib/awx/proj_dep_files'
inotifywait -m --event create,modify,delete /var/lib/awx/projects/_*/files/ --format %w%f | while read path file; do
cp -f $path /var/lib/awx/proj_dep_files/
done
Error:
Setting up watches.
Watches established.
cp: cannot stat '/var/lib/awx/projects/_33__aap_repo/files/RPM-GPG-Key-cisco-amp': No such file or directory
cp: cannot stat '/var/lib/awx/projects/_33__aap_repo/files/debsig_policy': No such file or directory
cp: cannot stat '/var/lib/awx/projects/_33__aap_repo/files/sftd.yaml.j2': No such file or directory
cp: cannot stat '/var/lib/awx/projects/_33__aap_repo/files/snmpd.conf': No such file or directory
Now source and dest have been verified a few times.. perms on source and dest = are 777.I did try just an 'echo $path $file' earlier and the value of $path is the full /dir/path/to/file.name
​
And I can run the inotify and cp parts manually and they work so I'm totally struggle bussing it on this.
​
EDIT: I realize the source and dest variables arent doing anything.. with them I get the same error. This was one iteration of testing.
https://redd.it/11kgfau
@r_bash
SryRMS: A bash noscript to help install some popular proprietary as well as libre applications not available in the official repositories of Ubuntu.
https://github.com/hakerdefo/sryrms
https://redd.it/11l7iom
@r_bash
https://github.com/hakerdefo/sryrms
https://redd.it/11l7iom
@r_bash
GitHub
GitHub - hakerdefo/sryrms: SryRMS helps you in installing some popular proprietary as well as libre applications not available…
SryRMS helps you in installing some popular proprietary as well as libre applications not available in the official repositories of Ubuntu. - hakerdefo/sryrms
Creating a bash noscript to match multiline patterns in log files
Hi,
I'm trying to automate some time consuming tasks/log checking, building a system that I will replicate to other uses.
I have a logfile for example:
...multiline ACTION Text where all is good...
ERR-101 Something is wrong
ERR-201 Something is wrong with QASDASDASD
INFO-524 Something was wrong
WARN-484 Check line 23
...multiline ACTION Text where all is good...
ERR-101 Something is wrong
ERR-201 Something is wrong with PPOYOYOY
INFO-524 Something was wrong
WARN-484 Check line 23
INFO-524 This is it
I'm creating a check-error.template file:
# This is the template file
ERR-101 Something is wrong
ERR-201 Something is wrong with <TEXT_VAR>
INFO-524 Something was wrong
WARN-484 Check line <NUMBER_VAR>
<?>INFO-524 This is it</?>
Starting with # is a comment, surrounded by <?> are optional (e.g. exist only in the last line).
Text and number will be regexp checked.
If the error matches the template, I know it's ignorable.
I'm not using something advanced (perl, other regexp helpers), as it will be an issue to make sure it exists on every environment.
The following function gets a file and converts the template to regexp pattern
function template2variable {
local file=$1
local var_name=$2
local template=$(sed '/^#/d' "$file")
local pattern="${template//\\/\\\\}" # replace \ with \\
pattern="${pattern//\"/\\\"}" # escape "
pattern="${pattern//<TEXT_VALUE>/([[:alnum:]_]+)}"
pattern="${pattern//<NUMBER_VALUE>/([[:digit:]]+)}"
pattern="${pattern//$'\n'/\\n}"
pattern="${pattern//<?>/(}"
pattern="${pattern//<\/?>/)?}"
printf -v "$var_name" '%s' "$pattern"
}
template2variable "check-error.template" $error_template
Matching template with:
grep -Pzo "${error_template}" $logfile
Doing so, I get back all the template lines I wished.
However, when trying to work with the grep data
using -n lists every iteration with 1
using -c I get line count of 1
using -v results in an empty output
It seems like the match has returned as one giant result instead of several I can iterate over.
What am I doing wrong?
Suggestions for improvement?
Thank you
https://redd.it/11lepmr
@r_bash
Hi,
I'm trying to automate some time consuming tasks/log checking, building a system that I will replicate to other uses.
I have a logfile for example:
...multiline ACTION Text where all is good...
ERR-101 Something is wrong
ERR-201 Something is wrong with QASDASDASD
INFO-524 Something was wrong
WARN-484 Check line 23
...multiline ACTION Text where all is good...
ERR-101 Something is wrong
ERR-201 Something is wrong with PPOYOYOY
INFO-524 Something was wrong
WARN-484 Check line 23
INFO-524 This is it
I'm creating a check-error.template file:
# This is the template file
ERR-101 Something is wrong
ERR-201 Something is wrong with <TEXT_VAR>
INFO-524 Something was wrong
WARN-484 Check line <NUMBER_VAR>
<?>INFO-524 This is it</?>
Starting with # is a comment, surrounded by <?> are optional (e.g. exist only in the last line).
Text and number will be regexp checked.
If the error matches the template, I know it's ignorable.
I'm not using something advanced (perl, other regexp helpers), as it will be an issue to make sure it exists on every environment.
The following function gets a file and converts the template to regexp pattern
function template2variable {
local file=$1
local var_name=$2
local template=$(sed '/^#/d' "$file")
local pattern="${template//\\/\\\\}" # replace \ with \\
pattern="${pattern//\"/\\\"}" # escape "
pattern="${pattern//<TEXT_VALUE>/([[:alnum:]_]+)}"
pattern="${pattern//<NUMBER_VALUE>/([[:digit:]]+)}"
pattern="${pattern//$'\n'/\\n}"
pattern="${pattern//<?>/(}"
pattern="${pattern//<\/?>/)?}"
printf -v "$var_name" '%s' "$pattern"
}
template2variable "check-error.template" $error_template
Matching template with:
grep -Pzo "${error_template}" $logfile
Doing so, I get back all the template lines I wished.
However, when trying to work with the grep data
using -n lists every iteration with 1
using -c I get line count of 1
using -v results in an empty output
It seems like the match has returned as one giant result instead of several I can iterate over.
What am I doing wrong?
Suggestions for improvement?
Thank you
https://redd.it/11lepmr
@r_bash
Reddit
r/bash on Reddit: Creating a bash noscript to match multiline patterns in log files
Posted by u/WhenYouDev - No votes and no comments
It seems one can't use FFMpeg sub-folder syntax, './', when specifying list of video/audio files to concatenate in a text file.
I'm in the folder, present working directory, /home/user/Documents/, and have 2 main folders:
File List Text Files
/Split Files/Subfolder/
The first folder contains a text file, FileList.txt, with a list of video I'd like to concatenate/merge into one sequence:
file '/home/user/Documents/Split Files/Subfolder/004.webm'
file '/home/user/Documents/Split Files/Subfolder/005.webm'
Alternatively they can be specified as:
file './Split Files/Subfolder/004.webm'
file './Split Files/Subfolder/005.webm'
The following statement is executed, to join 004.webm and 005.webm into the output file 004005.web:
ffmpeg -f concat -safe 0 -i "./File List Text Files/Filenames.txt" -c copy "./Split Files/Subfolder/004005.webm"
In Windows CMD, I could use,
Impossible to open './File List Text Files/./Split Files/Subfolder/004.webm'
./File List Text Files/Filenames.txt: No such file or directory
It's trying to combing the two directories into one, which wasn't the case with Windows 7 CMD.
https://redd.it/11liy3m
@r_bash
I'm in the folder, present working directory, /home/user/Documents/, and have 2 main folders:
File List Text Files
/Split Files/Subfolder/
The first folder contains a text file, FileList.txt, with a list of video I'd like to concatenate/merge into one sequence:
file '/home/user/Documents/Split Files/Subfolder/004.webm'
file '/home/user/Documents/Split Files/Subfolder/005.webm'
Alternatively they can be specified as:
file './Split Files/Subfolder/004.webm'
file './Split Files/Subfolder/005.webm'
The following statement is executed, to join 004.webm and 005.webm into the output file 004005.web:
ffmpeg -f concat -safe 0 -i "./File List Text Files/Filenames.txt" -c copy "./Split Files/Subfolder/004005.webm"
In Windows CMD, I could use,
./Split Files/Subfolder/004.webm, in FileList.txt, but on Ubuntu Linux, FFMpeg displays the following error:Impossible to open './File List Text Files/./Split Files/Subfolder/004.webm'
./File List Text Files/Filenames.txt: No such file or directory
It's trying to combing the two directories into one, which wasn't the case with Windows 7 CMD.
https://redd.it/11liy3m
@r_bash
Reddit
r/bash on Reddit: It seems one can't use FFMpeg sub-folder syntax, './', when specifying list of video/audio files to concatenate…
Posted by u/Long_Bed_4568 - No votes and no comments