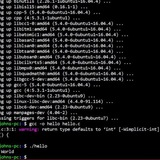
Need to unhide output
I have an embedded system I'm poking around in and from what I gather it's running bash. I'm taking a wild guess based on looking through the firmware.
I can get out of the application and drop to a shell however the following happens: blinking cursor, can type anything but when I hit enter it drops the blinking cursor to a new line and no output from the command is posted to the screen.
Using the Up, down, left, right keys produce characters such as, "^[D" when the left key is pressed, etc.
CTRL +ALT + DEL restarts the machine.
Enter moves the blinking cursor to the next line.
ESC produces "^[".
Tab works and moves the cursor over like it would in Windows.
What I'm looking for is a way to get the terminal/she'll to echo the output of the command or show the command prompt so I can see what's going on.
Any ideas? Excuse me if I'm in the wrong sub.
[https://redd.it/12g1knv
@r_bash
I have an embedded system I'm poking around in and from what I gather it's running bash. I'm taking a wild guess based on looking through the firmware.
I can get out of the application and drop to a shell however the following happens: blinking cursor, can type anything but when I hit enter it drops the blinking cursor to a new line and no output from the command is posted to the screen.
Using the Up, down, left, right keys produce characters such as, "^[D" when the left key is pressed, etc.
CTRL +ALT + DEL restarts the machine.
Enter moves the blinking cursor to the next line.
ESC produces "^[".
Tab works and moves the cursor over like it would in Windows.
What I'm looking for is a way to get the terminal/she'll to echo the output of the command or show the command prompt so I can see what's going on.
Any ideas? Excuse me if I'm in the wrong sub.
[https://redd.it/12g1knv
@r_bash
Reddit
r/bash on Reddit: Need to unhide output
Posted by u/patg84 - No votes and no comments
confusion over read ...or maybe printf?
So I'm doing some synthetic testing in order to better understand how read works, but now I think I'm getting tripped up with how printf works? The only thing I know for certain is I am confused.
I'm feeding the two arguments
bash-5.2$ read readitem < <(printf '%s\t%s\n' 'hello\' 'world') && echo "$readitem"
hello world
The \\t escape sequence is seemingly not negated, and the '\\' escape character itself is gone. Compare this to negating a newline in the format
bash-5.2$ read readitem < <(printf '%s\n%s\n' 'hello\' 'world') && echo "$readitem"
helloworld
And it works as I expect, with the
https://redd.it/12g8wvz
@r_bash
So I'm doing some synthetic testing in order to better understand how read works, but now I think I'm getting tripped up with how printf works? The only thing I know for certain is I am confused.
I'm feeding the two arguments
'hello\' 'world' to printf with the format %s\t%s\n. The 'hello\\' is deliberate as to negate the '\\t' escape sequence. The input stream is fed into the read command and I echo the variable. I'm expecting this to be pretty straight forward, with the output being something like 'helloworld', wherein the tab has been negated and the string is without any whitespace. After which I was expecting to add the -r option to read and see something like hello\ world because the backslash would be ignored as an escape character. When I actually run the command though...bash-5.2$ read readitem < <(printf '%s\t%s\n' 'hello\' 'world') && echo "$readitem"
hello world
The \\t escape sequence is seemingly not negated, and the '\\' escape character itself is gone. Compare this to negating a newline in the format
%s\n%s\n...bash-5.2$ read readitem < <(printf '%s\n%s\n' 'hello\' 'world') && echo "$readitem"
helloworld
And it works as I expect, with the
\n character being negated. Why am I able to escape the newline but not the tab?https://redd.it/12g8wvz
@r_bash
Reddit
r/bash on Reddit: confusion over read ...or maybe printf?
Posted by u/windows_sans_borders - No votes and 1 comment
bash returns me an error when reading a string with "/" from CSV file
This error `sed: -e expression #1, character 20: unknown option for s'` happens when `sed` reads a `/`.
I have a code that reads a CSV file, where there are cells with `/`. Here's a small portion of the code:
while read col1 col2
do
name1 = $col1 # here are cells that include "/"
name2 = $col2
for i in ${!name1[@]}
do
sed -i s/$name_place/"${name1[i]// /\\ }"/ file.noscript
# + more stuff here
done
done < $CSVfile
How can I fix it so the output includes the `/`?
https://redd.it/12gmok0
@r_bash
This error `sed: -e expression #1, character 20: unknown option for s'` happens when `sed` reads a `/`.
I have a code that reads a CSV file, where there are cells with `/`. Here's a small portion of the code:
while read col1 col2
do
name1 = $col1 # here are cells that include "/"
name2 = $col2
for i in ${!name1[@]}
do
sed -i s/$name_place/"${name1[i]// /\\ }"/ file.noscript
# + more stuff here
done
done < $CSVfile
How can I fix it so the output includes the `/`?
https://redd.it/12gmok0
@r_bash
Reddit
r/bash on Reddit: bash returns me an error when reading a string with "/" from CSV file
Posted by u/AlbertoAru - No votes and 2 comments
5 Bash String Manipulation Methods That Help Every Developer
https://levelup.gitconnected.com/5-bash-string-manipulation-methods-that-help-every-developer-49d4ee38b593?sk=e454f60397c41cd73d9e4810ee7869f8
https://redd.it/12h9c9h
@r_bash
https://levelup.gitconnected.com/5-bash-string-manipulation-methods-that-help-every-developer-49d4ee38b593?sk=e454f60397c41cd73d9e4810ee7869f8
https://redd.it/12h9c9h
@r_bash
Medium
5 Bash String Manipulation Methods That Help Every Developer
Process strings productively in your automation noscripts with these syntaxes
need help implementing s feature into a noscript
I have been working on a noscript that allows me to choose a host in my ~/.ssh/config file in my termux installation on my phone. The noscript works great as is.
The noscript allows for pushing a file or folder to the selected remote host or pulling a remote folder to my phone. I've gotten the push files section to allow for switching between selecting [a] file or folder.
I want to be able to do the same with the pull section. I can currently either set it for files or folders which is ok but I know it can be done just haven't figured out how yet.
Also another thing I have been trying to implement is selecting multiple files or folders and getting it to properly transfer I currently get an error when selecting multiple files that seems to come from fzf output it looks like this
`rsync: [sender] change_dir "/data/data/com.termux/files/home/.shortcuts/home\#012/data/data/com.termux/files/home/.shortcuts/love\#012/data/data/com.termux/files/home/.shortcuts" failed: No such file or directory`
Here is the current noscript any suggestions or help is very much appreciated
#!/bin/bash
function get-remote-hosts {
grep -iw host ~/.ssh/config | grep -v "exec" | cut -d ' ' -f 2
}
function backup-files {
mapfile -t REMOTE_HOSTS < <(get-remote-hosts)
if [ ${#REMOTE_HOSTS[@]} -eq 0 ]; then
printf "No remote hosts found in ~/.ssh/config\n"
return 1
fi
printf "Select a remote host:\n"
select remote_host in "${REMOTE_HOSTS[@]}"; do
printf "Select an option:\n"
select option in "Push files to remote directory" "Pull files from remote directory" "Exit" ; do
case "$option" in
"Push files to remote directory")
if command -v fzf >/dev/null 2>&1; then
FZF_DEFAULT_COMMAND='find "$HOME"/ /sdcard/ -maxdepth 2 -type f | grep -iv music | sort -f'
local_source_dir=$(eval "$FZF_DEFAULT_COMMAND" | sort -f | fzf --bind 'ctrl-d:reload(find "$HOME"/ /sdcard/ -maxdepth 1 -type d | sort -f),ctrl-f:reload(find "$HOME"/ /sdcard/ -maxdepth 2 -type f | grep -iv music | sort -f)' -m --layout=reverse --reverse)
else
local_source_dir=$(dialog --stdout --noscript "Select a directory" --dselect "$HOME/" 14 48)
fi
exit_status=$?
if [ $exit_status -ne 0 ]; then
printf "Error: Failed to select local directory\n"
return 1
fi
temp_file=$(mktemp)
ssh "$remote_host" 'find $HOME/ /media/nowhereman/nowhereman/ -maxdepth 1 -type d | sort -f' | sort -f > "$temp_file"
if command -v fzf >/dev/null 2>&1; then
remote_dest_dir=$(cat "$temp_file" | fzf --reverse)
else
remote_dest_dir=$(dialog --stdout --noscript "Select a remote directory" --fselect "$temp_file" 14 48)
fi
rm "$temp_file"
exit_status=$?
if [ $exit_status -ne 0 ]; then
printf "Error: Failed to select remote directory\n"
return 1
fi
if rsync -avz --progress "$local_source_dir" "$remote_host":"$remote_dest_dir"; then
printf "Files pushed successfully\n"
else
printf "Error: Failed to push files\n"
return 1
fi
break
;;
"Pull files from remote directory")
temp_file=$(mktemp)
ssh "$remote_host" 'find $HOME/
I have been working on a noscript that allows me to choose a host in my ~/.ssh/config file in my termux installation on my phone. The noscript works great as is.
The noscript allows for pushing a file or folder to the selected remote host or pulling a remote folder to my phone. I've gotten the push files section to allow for switching between selecting [a] file or folder.
I want to be able to do the same with the pull section. I can currently either set it for files or folders which is ok but I know it can be done just haven't figured out how yet.
Also another thing I have been trying to implement is selecting multiple files or folders and getting it to properly transfer I currently get an error when selecting multiple files that seems to come from fzf output it looks like this
`rsync: [sender] change_dir "/data/data/com.termux/files/home/.shortcuts/home\#012/data/data/com.termux/files/home/.shortcuts/love\#012/data/data/com.termux/files/home/.shortcuts" failed: No such file or directory`
Here is the current noscript any suggestions or help is very much appreciated
#!/bin/bash
function get-remote-hosts {
grep -iw host ~/.ssh/config | grep -v "exec" | cut -d ' ' -f 2
}
function backup-files {
mapfile -t REMOTE_HOSTS < <(get-remote-hosts)
if [ ${#REMOTE_HOSTS[@]} -eq 0 ]; then
printf "No remote hosts found in ~/.ssh/config\n"
return 1
fi
printf "Select a remote host:\n"
select remote_host in "${REMOTE_HOSTS[@]}"; do
printf "Select an option:\n"
select option in "Push files to remote directory" "Pull files from remote directory" "Exit" ; do
case "$option" in
"Push files to remote directory")
if command -v fzf >/dev/null 2>&1; then
FZF_DEFAULT_COMMAND='find "$HOME"/ /sdcard/ -maxdepth 2 -type f | grep -iv music | sort -f'
local_source_dir=$(eval "$FZF_DEFAULT_COMMAND" | sort -f | fzf --bind 'ctrl-d:reload(find "$HOME"/ /sdcard/ -maxdepth 1 -type d | sort -f),ctrl-f:reload(find "$HOME"/ /sdcard/ -maxdepth 2 -type f | grep -iv music | sort -f)' -m --layout=reverse --reverse)
else
local_source_dir=$(dialog --stdout --noscript "Select a directory" --dselect "$HOME/" 14 48)
fi
exit_status=$?
if [ $exit_status -ne 0 ]; then
printf "Error: Failed to select local directory\n"
return 1
fi
temp_file=$(mktemp)
ssh "$remote_host" 'find $HOME/ /media/nowhereman/nowhereman/ -maxdepth 1 -type d | sort -f' | sort -f > "$temp_file"
if command -v fzf >/dev/null 2>&1; then
remote_dest_dir=$(cat "$temp_file" | fzf --reverse)
else
remote_dest_dir=$(dialog --stdout --noscript "Select a remote directory" --fselect "$temp_file" 14 48)
fi
rm "$temp_file"
exit_status=$?
if [ $exit_status -ne 0 ]; then
printf "Error: Failed to select remote directory\n"
return 1
fi
if rsync -avz --progress "$local_source_dir" "$remote_host":"$remote_dest_dir"; then
printf "Files pushed successfully\n"
else
printf "Error: Failed to push files\n"
return 1
fi
break
;;
"Pull files from remote directory")
temp_file=$(mktemp)
ssh "$remote_host" 'find $HOME/
/media/nowhereman/nowhereman -maxdepth 1 -type d' | sort -f > "$temp_file"
if command -v fzf >/dev/null 2>&1; then
remote_source_dir=$(cat "$temp_file" | grep -iv pictures | fzf --reverse)
else
remote_source_dir=$(dialog --stdout --noscript "Select a remote directory" --fselect "$temp_file" 14 48)
fi
rm "$temp_file"
exit_status=$?
if [ $exit_status -ne 0 ]; then
printf "Error: Failed to select remote directory\n"
return 1
fi
if command -v fzf >/dev/null 2>&1; then
local_dest_dir=$(find "$HOME"/ /sdcard/ -maxdepth 1 -type d | sort -f | fzf --reverse)
else
local_dest_dir=$(dialog --stdout --noscript "Select a directory" --dselect "$HOME/" 14 48)
fi
exit_status=$?
if [ $exit_status -ne 0 ]; then
printf "Error: Failed to select local directory\n"
return 1
fi
if rsync -avz --progress "$remote_host":"$remote_source_dir" "$local_dest_dir"; then
printf "Files pulled successfully\n"
else
printf "Error: Failed to pull files\n"
return 1
fi
break
;;
"Exit")
break
;;
*)
printf "Invalid option. Please select a valid option.\n"
;;
esac
done
break
done
}
PS3="𝝅) "
# Execute the backup-files function
backup-files
https://redd.it/12hbdwl
@r_bash
if command -v fzf >/dev/null 2>&1; then
remote_source_dir=$(cat "$temp_file" | grep -iv pictures | fzf --reverse)
else
remote_source_dir=$(dialog --stdout --noscript "Select a remote directory" --fselect "$temp_file" 14 48)
fi
rm "$temp_file"
exit_status=$?
if [ $exit_status -ne 0 ]; then
printf "Error: Failed to select remote directory\n"
return 1
fi
if command -v fzf >/dev/null 2>&1; then
local_dest_dir=$(find "$HOME"/ /sdcard/ -maxdepth 1 -type d | sort -f | fzf --reverse)
else
local_dest_dir=$(dialog --stdout --noscript "Select a directory" --dselect "$HOME/" 14 48)
fi
exit_status=$?
if [ $exit_status -ne 0 ]; then
printf "Error: Failed to select local directory\n"
return 1
fi
if rsync -avz --progress "$remote_host":"$remote_source_dir" "$local_dest_dir"; then
printf "Files pulled successfully\n"
else
printf "Error: Failed to pull files\n"
return 1
fi
break
;;
"Exit")
break
;;
*)
printf "Invalid option. Please select a valid option.\n"
;;
esac
done
break
done
}
PS3="𝝅) "
# Execute the backup-files function
backup-files
https://redd.it/12hbdwl
@r_bash
Reddit
r/bash on Reddit: need help implementing s feature into a noscript
Posted by u/nowhereman531 - No votes and no comments
Delete only files in a directory with a specific extension when there isn't also a file with the same name, but a different extension?
Basically, Skyrim can't delete old
So, how would I go about mass-deleting
Quicksave0C385D2FF153686F6B6574686961Tamriel00104020230407173815221.skse
Quicksave0C385D2FF153686F6B6574686961Tamriel00104120230407173849221.skse
Quicksave0C385D2FF153686F6B6574686961Tamriel00104420230407174210221.skse
Quicksave0C385D2FF153686F6B6574686961Tamriel00111820230407181617231.skse
Quicksave0C385D2FF153686F6B6574686961Tamriel00115620230407185421241.ess
Quicksave0C385D2FF153686F6B6574686961Tamriel00115620230407185421241.skse
So, as an example, I'd like to be able to delete the first four
I could, I guess, copy the paired files (there's only a few dozen, though finding them in the list would be painful) somewhere safe, then just
Thank you in advance.
https://redd.it/12hj8we
@r_bash
Basically, Skyrim can't delete old
*.skse files when it updates or deletes its *.ess save files, leaving lots of orphaned *.skse files that are now useless (only the most recent is used for anything and can sometimes break a savefile if it goes missing). Currently over 10,000 files in the directory, which is quite annoying to prune by hand. :/So, how would I go about mass-deleting
*.skse files that don't have a matching *.ess? The types of filenames I'm looking at are...Quicksave0C385D2FF153686F6B6574686961Tamriel00104020230407173815221.skse
Quicksave0C385D2FF153686F6B6574686961Tamriel00104120230407173849221.skse
Quicksave0C385D2FF153686F6B6574686961Tamriel00104420230407174210221.skse
Quicksave0C385D2FF153686F6B6574686961Tamriel00111820230407181617231.skse
Quicksave0C385D2FF153686F6B6574686961Tamriel00115620230407185421241.ess
Quicksave0C385D2FF153686F6B6574686961Tamriel00115620230407185421241.skse
So, as an example, I'd like to be able to delete the first four
*.skse files since they have no matching *.ess files, but keep the last two because they properly pair.I could, I guess, copy the paired files (there's only a few dozen, though finding them in the list would be painful) somewhere safe, then just
rm the remaining, but I'd rather be able to slap a noscript in ~/.local/bin to run whenever I happen to think of it...Thank you in advance.
https://redd.it/12hj8we
@r_bash
Reddit
r/bash on Reddit: Delete only files in a directory with a specific extension when there isn't also a file with the same name, but…
Posted by u/JDGumby - No votes and 3 comments
Sshto update
Hi, I've played a bit with this new filter feature and it's proved to be very handy. But I've noticed few bugs:
1. It creates dupes in the list if same hosts scattered through subgroups
2. 'Select hosts' didn't work for filtered group
3. 'Edit conf' didn't work for filtered group
These are fixed, but who knows how many remains) I've also add 'quick commands' section to the CONTENTS view to be able to start filter from there. And renamed CONNECT button in first menu to CONNECT/SELECT to correspond new feature.
The link to sshto
Enjoy)
https://redd.it/12htrl2
@r_bash
Hi, I've played a bit with this new filter feature and it's proved to be very handy. But I've noticed few bugs:
1. It creates dupes in the list if same hosts scattered through subgroups
2. 'Select hosts' didn't work for filtered group
3. 'Edit conf' didn't work for filtered group
These are fixed, but who knows how many remains) I've also add 'quick commands' section to the CONTENTS view to be able to start filter from there. And renamed CONNECT button in first menu to CONNECT/SELECT to correspond new feature.
The link to sshto
Enjoy)
https://redd.it/12htrl2
@r_bash
GitHub
GitHub - vaniacer/sshto: Small bash noscript to manage your ssh connections. It builds menu (via dialog) from your ~/.ssh/config.…
Small bash noscript to manage your ssh connections. It builds menu (via dialog) from your ~/.ssh/config. It can not only connect but also to run commands, copy files, tunnel ports. - vaniacer/sshto
grep and force header (show filename) behaviour. How to format the output?
I have very basic noscript along the lines
for i in $(run some command that gives a list of files)
do grep -H $i ^pattern
done
which is giving me the output
/home/user1/textfile1.txt:pattern is matched in this line
/home/user1/textfile2.txt:pattern is a match here in this line
/home/user1/textfile33.txt:pattern is a word in this file
That is, the filename and the matched grep are concatenated altogether on one line with a colon field separator in between.
What I'd like, without too much more effort, is to put the output on separate lines more like
/home/user1/textfile1.txt
pattern is matched in this line
/home/user1/textfile2.txt
pattern is matched here in this line
/home/user1/textfile33.txt
pattern is matched
Can grep do this? Or do I need to get complicated with the noscript and do something stupid like run grep twice or use an if to print file name if grep returns a result?
Also, using sed to change that colon into a line break isn't going to work where either the filename/path or the matched line include a colon. Grep doesn't appear to have an option to change the field separator from colon to anything else, either (very interesting design choice, I think).
https://redd.it/12i4iqz
@r_bash
I have very basic noscript along the lines
for i in $(run some command that gives a list of files)
do grep -H $i ^pattern
done
which is giving me the output
/home/user1/textfile1.txt:pattern is matched in this line
/home/user1/textfile2.txt:pattern is a match here in this line
/home/user1/textfile33.txt:pattern is a word in this file
That is, the filename and the matched grep are concatenated altogether on one line with a colon field separator in between.
What I'd like, without too much more effort, is to put the output on separate lines more like
/home/user1/textfile1.txt
pattern is matched in this line
/home/user1/textfile2.txt
pattern is matched here in this line
/home/user1/textfile33.txt
pattern is matched
Can grep do this? Or do I need to get complicated with the noscript and do something stupid like run grep twice or use an if to print file name if grep returns a result?
Also, using sed to change that colon into a line break isn't going to work where either the filename/path or the matched line include a colon. Grep doesn't appear to have an option to change the field separator from colon to anything else, either (very interesting design choice, I think).
https://redd.it/12i4iqz
@r_bash
Reddit
r/bash on Reddit: grep and force header (show filename) behaviour. How to format the output?
Posted by u/homelaberator - No votes and 1 comment
Well, experts, show me the way. Not able to get the construction right off if loop
Here is a short program, which restricts the search within the directory(how trivial it may sound to ya)
​
Alright, now running this inside a git repo produced the right output , like this ,
​
Now, running this on a normal directory i.e. not a git repo, produces this:
​
In short, it is not working as "expected" due to the logical flaw in the loop construct, I am not able to fix it.
So, shed some light. ...and please be precise.
https://redd.it/12i6gv7
@r_bash
Here is a short program, which restricts the search within the directory(how trivial it may sound to ya)
#!/usr/bin/env bash12 check_git="git -C $PWD rev-parse"34 usage()5 {6 echo Provide name with regex delimeters.-- 7 echo Example : $(basename $0) \"*bash*\"8 }910 if [ $# -eq 0 ];then11 usage12 exit 113 fi1415 local_search()16 {17 if [[ "$(eval "$check_git")" == "" ]];then1819 git grep -n "$1"2021 elif [[ ! -d .git ]];then2223 find "$PWD" -type f,d -name "$1" -ls2425 else26 :27 fi28 }2930 local_search "$@"​
Alright, now running this inside a git repo produced the right output , like this ,
~/LaTeX_Workouts [master|✔]08:15 $ local_search "tex"Bhaskar_Chowdhury.log:1:This is pdfTeX, Version 3.14159265-2.6-1.40.21 (TeX Live 2020 Gentoo Linux) (preloaded format=pdflatex 2020.8.23) 23 AUG 2020 10:59​
Now, running this on a normal directory i.e. not a git repo, produces this:
tp_x250_08:17:40_Tue Apr 11: :~/Music>local_search "Mark"fatal: not a git repository (or any of the parent directories): .gitfatal: not a git repository (or any of the parent directories): .git​
In short, it is not working as "expected" due to the logical flaw in the loop construct, I am not able to fix it.
So, shed some light. ...and please be precise.
https://redd.it/12i6gv7
@r_bash
Reddit
r/bash on Reddit: Well, experts, show me the way. Not able to get the construction right off if loop
Posted by u/unixbhaskar - No votes and no comments
When using bash variable operators such as
TL;DR: Im looking for functionality in pure-bash matching like what
Say I have an array
a=('hi' '-hi' 'hihi' 'hiya' 'hi how are you' 'hi' 'hi'$'\n''there')
Now say I want to clear (replace with `''`) the two fields that contain exactly the string 'hi' and nothing else. Can this be done in an `a=("${a<someOperator>}")` sort of way?
Now I mean I know a bunch of ways to do this. For example, one can do this in a single-line command that uses external commands, pipes, and bash substitution. e.g.,
mapfile -t a < <(printf '%s\n' "${a[@]//$'\n'/$'\034'}" | grep -vE '^hi$' | tr $'\034' $'\n')
I also know a "pure-bash" way that one can do this that uses a temporary non-array variable. e.g.,
a0="$(printf '%s\n' '' "${a[@]//$'\n'/$'\034'}")"
mapfile -t a <<< "${a0//$'\n'hi$'\n'/}"
a=("${a[@]//$'\034'/$'\n'}")
And of course the good old fashioned loop
for kk in "${!a[@]}"; do [[ "${a[$kk]}" == 'hi' ]] && unset a[$kk]; done
but I dont know how to do this in a single command without pipes / subshells / external commands / copying data into a temporary variable / loops (which `a=("${a<someOperator>}")` would seemingly provide). Is this possible?
Thanks in advance.
P.S. Note that the first two methods above methods temporarily replace newlines that are in the array field data with the ASCII field separator (FS) control code (octal 34). In the unlikely event that the array field data already has any of these FS control characters naturally, a different temporary newline replacement (that isnt already present in the data) would need to be used.
https://redd.it/12i7sxy
@r_bash
${x[@]##y}, can you "anchor" what matches y to the start/end of the variable / array field?TL;DR: Im looking for functionality in pure-bash matching like what
^ and $ provide in regex matching.Say I have an array
a=('hi' '-hi' 'hihi' 'hiya' 'hi how are you' 'hi' 'hi'$'\n''there')
Now say I want to clear (replace with `''`) the two fields that contain exactly the string 'hi' and nothing else. Can this be done in an `a=("${a<someOperator>}")` sort of way?
Now I mean I know a bunch of ways to do this. For example, one can do this in a single-line command that uses external commands, pipes, and bash substitution. e.g.,
mapfile -t a < <(printf '%s\n' "${a[@]//$'\n'/$'\034'}" | grep -vE '^hi$' | tr $'\034' $'\n')
I also know a "pure-bash" way that one can do this that uses a temporary non-array variable. e.g.,
a0="$(printf '%s\n' '' "${a[@]//$'\n'/$'\034'}")"
mapfile -t a <<< "${a0//$'\n'hi$'\n'/}"
a=("${a[@]//$'\034'/$'\n'}")
And of course the good old fashioned loop
for kk in "${!a[@]}"; do [[ "${a[$kk]}" == 'hi' ]] && unset a[$kk]; done
but I dont know how to do this in a single command without pipes / subshells / external commands / copying data into a temporary variable / loops (which `a=("${a<someOperator>}")` would seemingly provide). Is this possible?
Thanks in advance.
P.S. Note that the first two methods above methods temporarily replace newlines that are in the array field data with the ASCII field separator (FS) control code (octal 34). In the unlikely event that the array field data already has any of these FS control characters naturally, a different temporary newline replacement (that isnt already present in the data) would need to be used.
https://redd.it/12i7sxy
@r_bash
Reddit
r/bash on Reddit: When using bash variable operators such as`${x[@]##y}`, can you "anchor" what matches `y` to the start/end of…
Posted by u/jkool702 - No votes and no comments
How to create log of all file modifications with timestamps?
Hi,
Bash newbie here. I'm trying to create a noscript that will create a log of all file modification operations done across my mac for a set time period (year ish). So it'll look something like
[01/02/23\] - fileA.txt OPENED
[01/02/23\] - fileA.txt MODIFIED
[01/06/23\] - fileB.txt DELETED
[01/15/23\] - fileA.txt DELETED
etc...
Not looking to be handed the answers. Just some guidance on where to look. An idea I had was to use the bash noscript to access the mac logs and filter by file operations, and then output those. But I can't find logs that have that file modification info.
https://redd.it/12i5v16
@r_bash
Hi,
Bash newbie here. I'm trying to create a noscript that will create a log of all file modification operations done across my mac for a set time period (year ish). So it'll look something like
[01/02/23\] - fileA.txt OPENED
[01/02/23\] - fileA.txt MODIFIED
[01/06/23\] - fileB.txt DELETED
[01/15/23\] - fileA.txt DELETED
etc...
Not looking to be handed the answers. Just some guidance on where to look. An idea I had was to use the bash noscript to access the mac logs and filter by file operations, and then output those. But I can't find logs that have that file modification info.
https://redd.it/12i5v16
@r_bash
Reddit
r/bash on Reddit: How to create log of all file modifications with timestamps?
Posted by u/hummus_k - 1 vote and 2 comments
How to add progress bar and log to this noscript?
https://raw.githubusercontent.com/mfn77/Post-Install/main/Post-Install.sh
I wrote a bash noscript for my post install configuration. I am definetely not an expert and this code probably is garbage but it works for me, at least it looks like it 's working. But I am wondering that can I add progress bar between user interactions and write a log file instead for normal terminal output? If I can how?
https://redd.it/12iizna
@r_bash
https://raw.githubusercontent.com/mfn77/Post-Install/main/Post-Install.sh
I wrote a bash noscript for my post install configuration. I am definetely not an expert and this code probably is garbage but it works for me, at least it looks like it 's working. But I am wondering that can I add progress bar between user interactions and write a log file instead for normal terminal output? If I can how?
https://redd.it/12iizna
@r_bash
rclone copy (or sync) with fzfI'm not sure if I've ever posted any of my code like this; it's usually only in some comment responding to someone that I do that
but this little bash noscript, barely 35 lines if you leave out the comments and the "help" text, seems interesting enough that someone might care to try it
the use case is when you want to run
rclone copy (or sync) but you'd like to (a) select what to copy using fzf, and (b) just as importantly, you want to copy multiple directories (or multiple files)this ability to select is especially useful if you're copying from a remote to a local directory
code is at https://github.com/xkcd386at/noscripts/blob/master/fclone if you want to take a look
https://redd.it/12ijnqh
@r_bash
GitHub
noscripts/fclone at master · xkcd386at/noscripts
various noscripts and tools. Contribute to xkcd386at/noscripts development by creating an account on GitHub.
Adding portions of strings in tab delimited file to another column
Hi,
I have a tab separated file (it's an .ALE file exported from Avid Media Composer). I am trying to add portions of one column's data into other columns on the same row. The second column in this file is a list of filenames. Each filename has specific information about the file which I'd like to add in the same row but under another column.
For example, I have the following columns: Name, Scene, Camera, Take
Name Scene Camera Take
302012_0017_2-33f_1b_b026.mov
302012_0016_2-33f_1a_a026.mov
302012_0019_2-33f_2a_a026.mov
302012_0024_2-33f_3c_c021.mov
302012_0020_2-33f_2b_b026.mov
302012_0018_2-33f_1c_c021.mov
302012_0022_2-33f_3a_a026.mov
302012_0023_2-33f_3b_b026.mov
302012_0021_2-33f_2c_c021.mov
In the first filename, 33f would be the Scene, 1b would be the Camera, and b026 would be the Take. On the command line, I can use the following to get each section one-by-one, changing the field of the last cut command for each section, but I'm also not sure how to iterate through the filename to get each part.
echo {302012_0017_2-33f_1b_b026.mov%.*} | cut -d - -f2 | cut -d _ -f1
Any help or pointers would be appreciated.
Thank you!
https://redd.it/12jcjug
@r_bash
Hi,
I have a tab separated file (it's an .ALE file exported from Avid Media Composer). I am trying to add portions of one column's data into other columns on the same row. The second column in this file is a list of filenames. Each filename has specific information about the file which I'd like to add in the same row but under another column.
For example, I have the following columns: Name, Scene, Camera, Take
Name Scene Camera Take
302012_0017_2-33f_1b_b026.mov
302012_0016_2-33f_1a_a026.mov
302012_0019_2-33f_2a_a026.mov
302012_0024_2-33f_3c_c021.mov
302012_0020_2-33f_2b_b026.mov
302012_0018_2-33f_1c_c021.mov
302012_0022_2-33f_3a_a026.mov
302012_0023_2-33f_3b_b026.mov
302012_0021_2-33f_2c_c021.mov
In the first filename, 33f would be the Scene, 1b would be the Camera, and b026 would be the Take. On the command line, I can use the following to get each section one-by-one, changing the field of the last cut command for each section, but I'm also not sure how to iterate through the filename to get each part.
echo {302012_0017_2-33f_1b_b026.mov%.*} | cut -d - -f2 | cut -d _ -f1
Any help or pointers would be appreciated.
Thank you!
https://redd.it/12jcjug
@r_bash
Reddit
r/bash on Reddit: Adding portions of strings in tab delimited file to another column
Posted by u/_aidsburger - No votes and 2 comments
I can't fathom what's wrong with this noscript. Feel like I'm missing something small but can't see what. Can anyone spot something?
Hello. I have the following noscript that scans recursively within directories for .mkv files and shows me those without subnoscripts. Everything about this seems to me that it *should* work, but when I run it I get
I first thought it could be a permissions issue, but even when running as root I get the same error. The noscript is of course executable and mkvmerge is indeed in my PATH. I'm a bit stumped! Thanks
​
https://redd.it/12jexov
@r_bash
Hello. I have the following noscript that scans recursively within directories for .mkv files and shows me those without subnoscripts. Everything about this seems to me that it *should* work, but when I run it I get
sh: line 5: : No such file or directory errors, regardless of which directory I use as $dir. There is also never any ouput file generated. Despite the warnings, I can hear the disk scanning the directories for some time, so it's doing *something*, just not what I wanted :DI first thought it could be a permissions issue, but even when running as root I get the same error. The noscript is of course executable and mkvmerge is indeed in my PATH. I'm a bit stumped! Thanks
​
#!/bin/bash# Set the directory to search for .mkv filesdir="/path/to/directory"# Set the output fileoutput_file="output.txt"# Find all .mkv files recursively in the directory and check if they have subnoscriptsfind "$dir" -type f -name "*.mkv" -exec sh -c 'for file do# Check if the file has subnoscriptsif ! mkvmerge -i "$file" | grep -q "subnoscripts"; then# Output the file name to the output fileecho "$file" >> "$output_file"fidone' sh {} +echo "Done. Output saved to $output_file."https://redd.it/12jexov
@r_bash
Reddit
r/bash on Reddit: I can't fathom what's wrong with this noscript. Feel like I'm missing something small but can't see what. Can anyone…
Posted by u/CheekyYoghurts - No votes and 7 comments
"what" -- A tool to get info about commands. I wrote it after I got fed up with how uninformative the standard tools like "type" and "which" can be, and how much digging you have to do to figure out problems.
https://github.com/wjandrea/what-bash
https://redd.it/12jqk01
@r_bash
https://github.com/wjandrea/what-bash
https://redd.it/12jqk01
@r_bash
GitHub
GitHub - wjandrea/what-bash: Get more info about a Bash command
Get more info about a Bash command. Contribute to wjandrea/what-bash development by creating an account on GitHub.
Why is trap handler not invoked immediately in this noscript
#!/bin/bash
cleanup() {
echo "Received SIGTERM signal. Cleaning up..."
exit 1
}
echo "Spawning child process..."
trap cleanup SIGTERM
sleep 10
echo $?
When I issue a SIGTERM after 2-3 seconds after invoking this process the cleanup is called AFTER 10 seconds. Shoulnd't the trap handler invoke immediately?
https://redd.it/12jqard
@r_bash
#!/bin/bash
cleanup() {
echo "Received SIGTERM signal. Cleaning up..."
exit 1
}
echo "Spawning child process..."
trap cleanup SIGTERM
sleep 10
echo $?
When I issue a SIGTERM after 2-3 seconds after invoking this process the cleanup is called AFTER 10 seconds. Shoulnd't the trap handler invoke immediately?
https://redd.it/12jqard
@r_bash
Reddit
r/bash on Reddit: Why is trap handler not invoked immediately in this noscript
Posted by u/ForeignCabinet2916 - No votes and 2 comments
bashelim collates a noscript with its sources (nested), and sends the result to stdout
Sometimes it is nice to collate all the noscripts that is at play,
in order to make it easier to inspect, or to share with someone
maybe after some final editing.
This noscript, is an adaption of the `soelim` noscript for collating
`troff` sources, for bash, it understands `.` and `source`, and also
nested files, and that cycles of nested files are bad!
This version doesn't read the path and looks for sources any other
place than in the current folder, tildes are expanded into the home-
folder however.
#!/bin/awk -f
# McUsr 2023 Mostly stolen from Jon Bently's m1.awk
# Vim licence
# bashelim instead of soelim V.0.0.0
# Collates the bashcript presented on the command line
# with all sourced files, for debugging purposes.
# Tildexpands any paths.but doesn't look through the path
# to find files without pathname besides the current folder.
BEGIN {
RS="\n"
hp=ENVIRON["HOME"]
}
function error(s) {
print "m1 error: " s | "cat 1>&2"; exit 1
}
function dofile(fname, savefile, savebuffer, newstring) {
if (fname in activefiles)
error("recursively reading file: " fname)
activefiles[fname] = 1
savefile = file; file = fname
savebuffer = buffer; buffer = ""
while (readline() != EOF) {
if (/^[ \t]*source[ \t]/) {
if (NF != 2) error("bad source line")
sub("~",hp,$2)
dofile(dosubs($2))
} else if (/^[ \t]*\.[ \t]/) {
if (NF != 2) error("bad source line")
sub("~",hp,$2)
dofile(dosubs($2))
} else
print $0
}
close(fname)
delete activefiles[fname]
file = savefile
buffer = savebuffer
}
# readline
#Put next input line into global string "buffer".
#Return "EOF" or "" (null string).
function readline( i, status) {
status = ""
if (buffer != "") {
i = index(buffer, "\n")
$0 = substr(buffer, 1, i-1)
buffer = substr(buffer, i+1)
} else {
# Hume: special case for non v10: if (file == "/dev/stdin")
if (getline <file <= 0)
status = EOF
}
# Hack: allow @Mname at start of line w/o closing @
if ($0 ~ /^@[A-Z][a-zA-Z0-9]*[ \t]*$/)
sub(/[ \t]*$/, "@")
return status
}
function dosubs(s, l, r, i, m) {
if (index(s, "@") == 0)
return s
l = "" # Left of current pos; ready for output
r = s # Right of current; unexamined at this time
while ((i = index(r, "@")) != 0) {
l = l substr(r, 1, i-1)
r = substr(r, i+1) # Currently scanning @
i = index(r, "@")
if (i == 0) {
l = l "@"
break
}
m = substr(r, 1, i-1)
r = substr(r, i+1)
if (m in symtab) {
r = symtab[m] r
} else {
l = l "@" m
r = "@" r
}
}
return l r
}
BEGIN {
EOF = "EOF"
if (ARGC == 1)
dofile("/dev/stdin")
else if (ARGC >= 2) {
for (i = 1; i < ARGC; i++)
dofile(ARGV[i])
} else
error("usage: m1 [fname...]")
}
# This noscript is excavated out of the M1.awk macro processor by Jon L. Bentley.
#M1 was documented in the 1997 sedawk book by Dale Dougherty & Arnold Robbins (ISBN 1-56592-225-5)
#but may have been written earlier.
#.P
# This noscript was adapted from the 1997 sedawk book by Dale Dougherty & Arnold Robbins (ISBN 1-56592-225-5)
# 131.191.66.141:8181/UNIX_BS/sedawk/examples/ch13/m1.pdf (download from
#<a href="http://lawker.googlecode.com/svn/fridge/share/pdf/m1.pdf">LAWKER</a>).
# Author Jon L. Bentley. (Of "Programming Pearls" fame.)
https://redd.it/12jv83a
@r_bash
Sometimes it is nice to collate all the noscripts that is at play,
in order to make it easier to inspect, or to share with someone
maybe after some final editing.
This noscript, is an adaption of the `soelim` noscript for collating
`troff` sources, for bash, it understands `.` and `source`, and also
nested files, and that cycles of nested files are bad!
This version doesn't read the path and looks for sources any other
place than in the current folder, tildes are expanded into the home-
folder however.
#!/bin/awk -f
# McUsr 2023 Mostly stolen from Jon Bently's m1.awk
# Vim licence
# bashelim instead of soelim V.0.0.0
# Collates the bashcript presented on the command line
# with all sourced files, for debugging purposes.
# Tildexpands any paths.but doesn't look through the path
# to find files without pathname besides the current folder.
BEGIN {
RS="\n"
hp=ENVIRON["HOME"]
}
function error(s) {
print "m1 error: " s | "cat 1>&2"; exit 1
}
function dofile(fname, savefile, savebuffer, newstring) {
if (fname in activefiles)
error("recursively reading file: " fname)
activefiles[fname] = 1
savefile = file; file = fname
savebuffer = buffer; buffer = ""
while (readline() != EOF) {
if (/^[ \t]*source[ \t]/) {
if (NF != 2) error("bad source line")
sub("~",hp,$2)
dofile(dosubs($2))
} else if (/^[ \t]*\.[ \t]/) {
if (NF != 2) error("bad source line")
sub("~",hp,$2)
dofile(dosubs($2))
} else
print $0
}
close(fname)
delete activefiles[fname]
file = savefile
buffer = savebuffer
}
# readline
#Put next input line into global string "buffer".
#Return "EOF" or "" (null string).
function readline( i, status) {
status = ""
if (buffer != "") {
i = index(buffer, "\n")
$0 = substr(buffer, 1, i-1)
buffer = substr(buffer, i+1)
} else {
# Hume: special case for non v10: if (file == "/dev/stdin")
if (getline <file <= 0)
status = EOF
}
# Hack: allow @Mname at start of line w/o closing @
if ($0 ~ /^@[A-Z][a-zA-Z0-9]*[ \t]*$/)
sub(/[ \t]*$/, "@")
return status
}
function dosubs(s, l, r, i, m) {
if (index(s, "@") == 0)
return s
l = "" # Left of current pos; ready for output
r = s # Right of current; unexamined at this time
while ((i = index(r, "@")) != 0) {
l = l substr(r, 1, i-1)
r = substr(r, i+1) # Currently scanning @
i = index(r, "@")
if (i == 0) {
l = l "@"
break
}
m = substr(r, 1, i-1)
r = substr(r, i+1)
if (m in symtab) {
r = symtab[m] r
} else {
l = l "@" m
r = "@" r
}
}
return l r
}
BEGIN {
EOF = "EOF"
if (ARGC == 1)
dofile("/dev/stdin")
else if (ARGC >= 2) {
for (i = 1; i < ARGC; i++)
dofile(ARGV[i])
} else
error("usage: m1 [fname...]")
}
# This noscript is excavated out of the M1.awk macro processor by Jon L. Bentley.
#M1 was documented in the 1997 sedawk book by Dale Dougherty & Arnold Robbins (ISBN 1-56592-225-5)
#but may have been written earlier.
#.P
# This noscript was adapted from the 1997 sedawk book by Dale Dougherty & Arnold Robbins (ISBN 1-56592-225-5)
# 131.191.66.141:8181/UNIX_BS/sedawk/examples/ch13/m1.pdf (download from
#<a href="http://lawker.googlecode.com/svn/fridge/share/pdf/m1.pdf">LAWKER</a>).
# Author Jon L. Bentley. (Of "Programming Pearls" fame.)
https://redd.it/12jv83a
@r_bash
New release of bkt, a subprocess caching utility
Hi all, I recently cut a new release of `bkt` with some additional functionality. Notably, it's now possible to include a file's last-modified time in the cache key, thereby invalidating the cache if the file changes.
Wait, what is
Another way I use
$ curl http://some.api/data/a | jq '.foo'
$ curl http://some.api/data/a | jq '.foo.bar'
$ curl http://some.api/data/b | jq '.foo.bar.baz'
Which is obviously wasteful and slow. You could write the output to a file and then pipe that to
Instead, using `bkt` ensures each request is only sent once and all subsequent calls return locally cached results:
$ bkt --ttl=1d -- curl http://some.api/data/a | jq '.foo'
$ bkt --ttl=1d -- curl http://some.api/data/a | jq '.foo.bar'
$ bkt --ttl=1d -- curl http://some.api/data/b | jq '.foo.bar.baz'
If you haven't used it before give it a spin! If you find it useful please share how you're using `bkt` so others can benefit :)
https://redd.it/12ke9i3
@r_bash
Hi all, I recently cut a new release of `bkt` with some additional functionality. Notably, it's now possible to include a file's last-modified time in the cache key, thereby invalidating the cache if the file changes.
Wait, what is
bkt?bkt is a subprocess caching utility you can use to persist a command's output so that subsequent invocations are fast. As an example, I use bkt heavily in my shell prompt to speed up the information it displays.Another way I use
bkt often is to simplify and speed up iterating on command pipelines that are slow to run. For example, if you're using jq to play around with a JSON response you might do something like this:$ curl http://some.api/data/a | jq '.foo'
$ curl http://some.api/data/a | jq '.foo.bar'
$ curl http://some.api/data/b | jq '.foo.bar.baz'
Which is obviously wasteful and slow. You could write the output to a file and then pipe that to
jq, but you often end up juggling multiple response files and it get's tedious quickly.Instead, using `bkt` ensures each request is only sent once and all subsequent calls return locally cached results:
$ bkt --ttl=1d -- curl http://some.api/data/a | jq '.foo'
$ bkt --ttl=1d -- curl http://some.api/data/a | jq '.foo.bar'
$ bkt --ttl=1d -- curl http://some.api/data/b | jq '.foo.bar.baz'
If you haven't used it before give it a spin! If you find it useful please share how you're using `bkt` so others can benefit :)
https://redd.it/12ke9i3
@r_bash
GitHub
Release 0.6.0 · dimo414/bkt
What's Changed
Support environment variables BKT_TTL, BKT_SCOPE, and BKT_CACHE_DIR as alternatives for flags --ttl, --scope, and --cache-dir, respectively (#15).
Added support for keying the c...
Support environment variables BKT_TTL, BKT_SCOPE, and BKT_CACHE_DIR as alternatives for flags --ttl, --scope, and --cache-dir, respectively (#15).
Added support for keying the c...