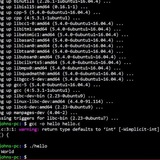
How to extract certain text from local html files in ubuntu
I have several HTML files saved locally. How can I extract numbers that start with "-" from all of them and save each number in a separate line in a new file? For example, the numbers are formatted like this: - 74345. I want each of these numbers to be placed on a new line in the output file.
https://redd.it/1djqcjs
@r_bash
I have several HTML files saved locally. How can I extract numbers that start with "-" from all of them and save each number in a separate line in a new file? For example, the numbers are formatted like this: - 74345. I want each of these numbers to be placed on a new line in the output file.
https://redd.it/1djqcjs
@r_bash
Reddit
From the bash community on Reddit
Explore this post and more from the bash community
source file counter variable
My post keeps getting removed for my code.
My source file has 4 line is such as
img_1=file1
img_2=file2
I'm trying to write a noscript with a counter to "ls -lh $img_1".... be easier to explain if I could post my code
https://redd.it/1dl8zkx
@r_bash
My post keeps getting removed for my code.
My source file has 4 line is such as
img_1=file1
img_2=file2
I'm trying to write a noscript with a counter to "ls -lh $img_1".... be easier to explain if I could post my code
https://redd.it/1dl8zkx
@r_bash
Reddit
From the bash community on Reddit
Explore this post and more from the bash community
Need Help Sorting Files by Hashing in Bash Script
I've been trying to sort files in a folder by comparing them to a source directory using BLAKE2 hashing on my unraid server. The noscript should move matching files from the destination directory to a new folder. However, it keeps saying "Destination file not found" even though the files exist.
### Here’s the noscript:
```bash
#!/bin/bash
# Directories
source_dir="/path/to/source_directory"
destination_dir="/path/to/destination_directory"
move_to_dir="/path/to/move_to_directory"
# Log file
log_file="/path/to/logs/move_files.log"
# Function to calculate BLAKE2 hash
calculate_hash() {
/usr/bin/python3 -c 'import hashlib, sys; h = hashlib.blake2b(); h.update(sys.stdin.buffer.read()); print(h.hexdigest())'
}
# Ensure destination directory exists
mkdir -p "$move_to_dir"
# Iterate through files in source directory and subdirectories
find "$source_dir" -type f -print0 | while IFS= read -r -d '' source_file; do
# Print source file for debugging
echo "Source File: $source_file"
# Calculate hash of the file in the source directory
source_hash=$(calculate_hash < "$source_file")
# Calculate relative path for destination file
relative_path="${source_file#$source_dir}"
destination_file="$destination_dir/$relative_path"
# Print destination file for debugging
echo "Destination File: $destination_file"
# Check if destination file exists
if [ -f "$destination_file" ]; then
# Print hash calculation details for debugging
echo "Calculating hashes..."
destination_hash=$(calculate_hash < "$destination_file")
# Log hashes for debugging
echo "$(date +"%Y-%m-%d %H:%M:%S") - Source Hash: $source_hash, Destination Hash: $destination_hash" >> "$log_file"
# Compare hashes
if [ "$source_hash" == "$destination_hash" ]; then
# Move the file to the new directory
mv "$destination_file" "$move_to_dir/"
# Log the move
echo "$(date +"%Y-%m-%d %H:%M:%S") - Moved: $destination_file" >> "$log_file"
fi
else
echo "Destination file not found: $destination_file"
fi
done
echo "Comparison and move process completed."
https://redd.it/1dm775e
@r_bash
I've been trying to sort files in a folder by comparing them to a source directory using BLAKE2 hashing on my unraid server. The noscript should move matching files from the destination directory to a new folder. However, it keeps saying "Destination file not found" even though the files exist.
### Here’s the noscript:
```bash
#!/bin/bash
# Directories
source_dir="/path/to/source_directory"
destination_dir="/path/to/destination_directory"
move_to_dir="/path/to/move_to_directory"
# Log file
log_file="/path/to/logs/move_files.log"
# Function to calculate BLAKE2 hash
calculate_hash() {
/usr/bin/python3 -c 'import hashlib, sys; h = hashlib.blake2b(); h.update(sys.stdin.buffer.read()); print(h.hexdigest())'
}
# Ensure destination directory exists
mkdir -p "$move_to_dir"
# Iterate through files in source directory and subdirectories
find "$source_dir" -type f -print0 | while IFS= read -r -d '' source_file; do
# Print source file for debugging
echo "Source File: $source_file"
# Calculate hash of the file in the source directory
source_hash=$(calculate_hash < "$source_file")
# Calculate relative path for destination file
relative_path="${source_file#$source_dir}"
destination_file="$destination_dir/$relative_path"
# Print destination file for debugging
echo "Destination File: $destination_file"
# Check if destination file exists
if [ -f "$destination_file" ]; then
# Print hash calculation details for debugging
echo "Calculating hashes..."
destination_hash=$(calculate_hash < "$destination_file")
# Log hashes for debugging
echo "$(date +"%Y-%m-%d %H:%M:%S") - Source Hash: $source_hash, Destination Hash: $destination_hash" >> "$log_file"
# Compare hashes
if [ "$source_hash" == "$destination_hash" ]; then
# Move the file to the new directory
mv "$destination_file" "$move_to_dir/"
# Log the move
echo "$(date +"%Y-%m-%d %H:%M:%S") - Moved: $destination_file" >> "$log_file"
fi
else
echo "Destination file not found: $destination_file"
fi
done
echo "Comparison and move process completed."
https://redd.it/1dm775e
@r_bash
Reddit
From the bash community on Reddit
Explore this post and more from the bash community
learning file permissions, what is the "owner" "group" and "other"?
hello i'm trying to learn and understand file permissions in bash, and to what i understand there are 3 "categories" in bash?
owner, group and other?
what do these things mean? what does owner mean? is that strictly the user that made the file or can the owner of a file give ownership of that file to another user?
what are groups?
and what are "other"? what does that mean?
thank you
https://redd.it/1dmfkes
@r_bash
hello i'm trying to learn and understand file permissions in bash, and to what i understand there are 3 "categories" in bash?
owner, group and other?
what do these things mean? what does owner mean? is that strictly the user that made the file or can the owner of a file give ownership of that file to another user?
what are groups?
and what are "other"? what does that mean?
thank you
https://redd.it/1dmfkes
@r_bash
Reddit
From the bash community on Reddit
Explore this post and more from the bash community
What's the most elegant way to achieve this?
So I have a wine program I'd like to run and also a wine prefix I'd like to run that program in. Both have long paths.
Should I alias them both in .bash_aliases, then call them within a noscript and call it a day? Preferably something I could also bind to a key easily.
Sorry if this question is dumb.
https://redd.it/1dmzfe9
@r_bash
So I have a wine program I'd like to run and also a wine prefix I'd like to run that program in. Both have long paths.
Should I alias them both in .bash_aliases, then call them within a noscript and call it a day? Preferably something I could also bind to a key easily.
Sorry if this question is dumb.
https://redd.it/1dmzfe9
@r_bash
Reddit
From the bash community on Reddit
Explore this post and more from the bash community
bashbro - New Software Release (rework of bashttpd)
Newly released
https://github.com/victrixsoft/bashbro/
https://redd.it/1dndldo
@r_bash
Newly released
bashbro - it's Bash-based web file browser that allows you to remotely browse, stream, view documents and save files via your web browser. Super easy to use, try it!! https://github.com/victrixsoft/bashbro/
https://redd.it/1dndldo
@r_bash
GitHub
GitHub - victrixsoft/bashbro: A Bash-based web file browser. Allowing you to browse, view and transfer files via your web browser.
A Bash-based web file browser. Allowing you to browse, view and transfer files via your web browser. - victrixsoft/bashbro
Counterintuitive word splitting
I've recently already made a post about word splitting, however, this seems to be another unrelated issue that I again can't seem to find any answers. Consider this setup:
$ #!/bin/bash
$ # version 5.2.26
$ IFS=" :" # space (ifs-whitespace), colon (ifs-non-whitespace)
$ A=" ::word:: " # spaces, colon, "word", colon, spaces
$ printf "'%s'\n" $A
''
''
'word'
''
As you can see, printf got 4 arguments, as opposed to 3, what I would've expected. First, I though my previous post might be related, however, adding another instance of `$A` to the end makes it 8 arguments, exactly double, so it's not related to stripping trailing "null arguments".
Why does this happen? Is there a sentence in the man page that explains this behavior (I couldn't parse it from the section about word splitting :'D)
Edit: I tested the following bourne-like shells:
bash
bash -o posix
dash
ksh
mksh
yash
yash -o posix
posh (policy-compliant ordinary shell)
pbosh (schilytools)
mrsh (by Simon Ser)
ALL of them do it exactly the same, except mrsh (it's doing what I expected). However, mrsh is quite niche and rather a hobby project by someone, so I wouldn't take that as any authority.
https://redd.it/1dnqswy
@r_bash
I've recently already made a post about word splitting, however, this seems to be another unrelated issue that I again can't seem to find any answers. Consider this setup:
$ #!/bin/bash
$ # version 5.2.26
$ IFS=" :" # space (ifs-whitespace), colon (ifs-non-whitespace)
$ A=" ::word:: " # spaces, colon, "word", colon, spaces
$ printf "'%s'\n" $A
''
''
'word'
''
As you can see, printf got 4 arguments, as opposed to 3, what I would've expected. First, I though my previous post might be related, however, adding another instance of `$A` to the end makes it 8 arguments, exactly double, so it's not related to stripping trailing "null arguments".
Why does this happen? Is there a sentence in the man page that explains this behavior (I couldn't parse it from the section about word splitting :'D)
Edit: I tested the following bourne-like shells:
bash
bash -o posix
dash
ksh
mksh
yash
yash -o posix
posh (policy-compliant ordinary shell)
pbosh (schilytools)
mrsh (by Simon Ser)
ALL of them do it exactly the same, except mrsh (it's doing what I expected). However, mrsh is quite niche and rather a hobby project by someone, so I wouldn't take that as any authority.
https://redd.it/1dnqswy
@r_bash
Reddit
From the bash community on Reddit
Explore this post and more from the bash community
Question about stream redirection / file denoscriptors
**TL;DR - In bash, what is the significance of the `-` character in the following expression?: `${@}"; echo "${?}" 1>&3-;`**
Problem denoscription:
While trying to find a way to capture stderr, stdout, and return code to separate variables, I came across a solution [on this stackoverflow post](https://stackoverflow.com/questions/11027679/capture-stdout-and-stderr-into-different-variables).. I am mostly looking at the section labeled "**6. Preserving the exit status with sanitization – unbreakable (rewritten)**" which has this:
{
IFS=$'\n' read -r -d '' CAPTURED_STDOUT;
IFS=$'\n' read -r -d '' CAPTURED_STDERR;
(IFS=$'\n' read -r -d '' _ERRNO_; exit ${_ERRNO_});
} < <((printf '\0%s\0%d\0' "$(((({ some_command; echo "${?}" 1>&3-; } | tr -d '\0' 1>&4-) 4>&2- 2>&1- | tr -d '\0' 1>&4-) 3>&1- | exit "$(cat)") 4>&1-)" "${?}" 1>&2) 2>&1)
It seems to work ok. although I am making my own alterations. I've read through the post a couple times and mostly understand what's going on (short version is some trickery using redirection to different denoscriptors and reformatting output with `NUL` / `\0` so that `read` can pull it into the appropriate variables).
I get that e.g. `1>&3-; ` is redirecting from file denoscriptor 1 to file denoscriptor 3, `1>&4-` is redirecting from file denoscriptor 1 to file denoscriptor 4, and so on. But I've never seen stream redirection examples with a trailing hyphen before and I don't really understand the significance of having a `-` following `1>&3` etc. I have been hitting ddg and searx for the last 30 minutes and still coming up empty-handed.
Any idea what am I missing? Is there any functional difference between using `1>&3-; ` vs `1>&3; ` or is it just a coding style thing?
https://redd.it/1dnxehx
@r_bash
**TL;DR - In bash, what is the significance of the `-` character in the following expression?: `${@}"; echo "${?}" 1>&3-;`**
Problem denoscription:
While trying to find a way to capture stderr, stdout, and return code to separate variables, I came across a solution [on this stackoverflow post](https://stackoverflow.com/questions/11027679/capture-stdout-and-stderr-into-different-variables).. I am mostly looking at the section labeled "**6. Preserving the exit status with sanitization – unbreakable (rewritten)**" which has this:
{
IFS=$'\n' read -r -d '' CAPTURED_STDOUT;
IFS=$'\n' read -r -d '' CAPTURED_STDERR;
(IFS=$'\n' read -r -d '' _ERRNO_; exit ${_ERRNO_});
} < <((printf '\0%s\0%d\0' "$(((({ some_command; echo "${?}" 1>&3-; } | tr -d '\0' 1>&4-) 4>&2- 2>&1- | tr -d '\0' 1>&4-) 3>&1- | exit "$(cat)") 4>&1-)" "${?}" 1>&2) 2>&1)
It seems to work ok. although I am making my own alterations. I've read through the post a couple times and mostly understand what's going on (short version is some trickery using redirection to different denoscriptors and reformatting output with `NUL` / `\0` so that `read` can pull it into the appropriate variables).
I get that e.g. `1>&3-; ` is redirecting from file denoscriptor 1 to file denoscriptor 3, `1>&4-` is redirecting from file denoscriptor 1 to file denoscriptor 4, and so on. But I've never seen stream redirection examples with a trailing hyphen before and I don't really understand the significance of having a `-` following `1>&3` etc. I have been hitting ddg and searx for the last 30 minutes and still coming up empty-handed.
Any idea what am I missing? Is there any functional difference between using `1>&3-; ` vs `1>&3; ` or is it just a coding style thing?
https://redd.it/1dnxehx
@r_bash
Stack Overflow
Capture stdout and stderr into different variables
Is it possible to store or capture stdout and stderr in different variables, without using a temp file? Right now I do this to get stdout in out and stderr in err when running some_command, but I'...
Differences between (MacOS) 3.2.57 and 5.x?
Hi, folks. I'm sure this has been asked before. I've been doing searches but keep bumping up against posts about ZSH or how to upgrade with Brew.
Unfortunately, I'm in a bit of a tight spot. I have not found an answer to what I need and am hoping someone can point me in the right direction.
I wrote a BASH noscript that is fairly sophisticated. Nothing too crazy though. Lots of functions, a few run-of-the-mill commands like find, sort, uniq, awk. Keywords like 'local' and 'read.'
It works on my laptop (Windows running BASH 5.2.21 under Cygwin - I'm not allowed to run WSL) and runs perfectly on a Linux host. Idk the BASH version on the Linux side (and logging into it is a PITA which is why I'm not checking) but it's a modern Linux so probably 5.x. I handed the noscript to a coworker who ran my noscript on his MacOS laptop and found it didn't work. 🤦
Sigh. So, now I need to try to figure out what BASH feature I'm using that's not compatible with 3.x. I can't tell all my coworkers to upgrade BASH just so my noscript will work. I don't have time to make my noscript compatible with ZSH. I'm probably the only one in the dept NOT running MacOS. I'm starting to remember why 🤣😬
If anybody has ideas of where I can look for guidance on what features to avoid when making a BASH noscript work on MacOS, I'd appreciate it. Maybe 4.0 and 5.0 release notes on what features were introduced?
Is variable expansion ${} incompatible or running a subprocess with $() instead of backticks?
I wish I could share the noscript but I would be violating rules doing that.
Thanks in advance
https://redd.it/1doc89p
@r_bash
Hi, folks. I'm sure this has been asked before. I've been doing searches but keep bumping up against posts about ZSH or how to upgrade with Brew.
Unfortunately, I'm in a bit of a tight spot. I have not found an answer to what I need and am hoping someone can point me in the right direction.
I wrote a BASH noscript that is fairly sophisticated. Nothing too crazy though. Lots of functions, a few run-of-the-mill commands like find, sort, uniq, awk. Keywords like 'local' and 'read.'
It works on my laptop (Windows running BASH 5.2.21 under Cygwin - I'm not allowed to run WSL) and runs perfectly on a Linux host. Idk the BASH version on the Linux side (and logging into it is a PITA which is why I'm not checking) but it's a modern Linux so probably 5.x. I handed the noscript to a coworker who ran my noscript on his MacOS laptop and found it didn't work. 🤦
Sigh. So, now I need to try to figure out what BASH feature I'm using that's not compatible with 3.x. I can't tell all my coworkers to upgrade BASH just so my noscript will work. I don't have time to make my noscript compatible with ZSH. I'm probably the only one in the dept NOT running MacOS. I'm starting to remember why 🤣😬
If anybody has ideas of where I can look for guidance on what features to avoid when making a BASH noscript work on MacOS, I'd appreciate it. Maybe 4.0 and 5.0 release notes on what features were introduced?
Is variable expansion ${} incompatible or running a subprocess with $() instead of backticks?
I wish I could share the noscript but I would be violating rules doing that.
Thanks in advance
https://redd.it/1doc89p
@r_bash
Reddit
From the bash community on Reddit
Explore this post and more from the bash community
RAG in bash for MongoDB Atlas
Hi everyone, I made a small bash noscript (based on a JS noscript) that allows you do turn data/insights into AI and then query it directly in the terminal.
https://github.com/farspeak/farspeak-cli
https://preview.redd.it/pojyoheqlr8d1.png?width=1600&format=png&auto=webp&s=961b13e6f43af6c23a5fe326590968b683b2b1d5
Please let me know what you think
https://redd.it/1dodphp
@r_bash
Hi everyone, I made a small bash noscript (based on a JS noscript) that allows you do turn data/insights into AI and then query it directly in the terminal.
https://github.com/farspeak/farspeak-cli
https://preview.redd.it/pojyoheqlr8d1.png?width=1600&format=png&auto=webp&s=961b13e6f43af6c23a5fe326590968b683b2b1d5
Please let me know what you think
https://redd.it/1dodphp
@r_bash
GitHub
GitHub - farspeak/farspeak-cli
Contribute to farspeak/farspeak-cli development by creating an account on GitHub.
Does anyone know of a good way to read raw hexadecimal / uint data using only bash builtins?
Im trying to figure out a way to convert integers to/from their raw hex/uint form.
Bash stores integers as ascii, meaning that each byte provides 10 numbers and N bytes of data allows you to represent numbers up to of `10^N - 1`. With hex/uint, all possible bit combinations represent integers, meaning each byte provides 256 numbers and N bytes of data allows you to represent numbers up to `256^N - 1`.
In practice, this means that (on average) it takes ~60% less space to store a given integer (since they are being stored `log(256)/log(10) = ~2.4` times more efficiently).
Ive figured out a pure-bash way to convert integers (between 0 and `2^64 - 1` to their raw hex/uint values:
shopt -s extglob
shopt -s patsub_replacement
dec2uint () {
local a b nn;
for nn in "$@"; do
printf -v a '%x' "$nn";
printf -v b '\\x%s' ${a//@([0-9a-f])@([0-9a-f])/& };
printf "$b";
done
}
We can check that this does infact work by determining the number associated with some hex string, feeding that number to `dec2uint` and piping the output to xxd (or hexdump), which should show the hex we started with
# echo $(( 16#1234567890abcdef ))
1311768467294899695
# dec2uint 1311768467294899695 | xxd
00000000: 1234 5678 90ab cdef .4Vx....
In this case, the number that usually takes 19 bytes to represent instead takes only 8 bytes.
# printf 1311768467294899695 | wc -c
19
# dec2uint 1311768467294899695 | wc -c
8
***
At any rate, Im am trying to figure out how to do the reverse operation, speciffically the functionality that is provided by xxd (or by hexdump) in the above example, efficiently using only bash builtins...If I can figure this out then it is easy to convert back to the number using printf.
Anyone know of a way to get bash to read raw hex/uint data?
https://redd.it/1dor7ss
@r_bash
Im trying to figure out a way to convert integers to/from their raw hex/uint form.
Bash stores integers as ascii, meaning that each byte provides 10 numbers and N bytes of data allows you to represent numbers up to of `10^N - 1`. With hex/uint, all possible bit combinations represent integers, meaning each byte provides 256 numbers and N bytes of data allows you to represent numbers up to `256^N - 1`.
In practice, this means that (on average) it takes ~60% less space to store a given integer (since they are being stored `log(256)/log(10) = ~2.4` times more efficiently).
Ive figured out a pure-bash way to convert integers (between 0 and `2^64 - 1` to their raw hex/uint values:
shopt -s extglob
shopt -s patsub_replacement
dec2uint () {
local a b nn;
for nn in "$@"; do
printf -v a '%x' "$nn";
printf -v b '\\x%s' ${a//@([0-9a-f])@([0-9a-f])/& };
printf "$b";
done
}
We can check that this does infact work by determining the number associated with some hex string, feeding that number to `dec2uint` and piping the output to xxd (or hexdump), which should show the hex we started with
# echo $(( 16#1234567890abcdef ))
1311768467294899695
# dec2uint 1311768467294899695 | xxd
00000000: 1234 5678 90ab cdef .4Vx....
In this case, the number that usually takes 19 bytes to represent instead takes only 8 bytes.
# printf 1311768467294899695 | wc -c
19
# dec2uint 1311768467294899695 | wc -c
8
***
At any rate, Im am trying to figure out how to do the reverse operation, speciffically the functionality that is provided by xxd (or by hexdump) in the above example, efficiently using only bash builtins...If I can figure this out then it is easy to convert back to the number using printf.
Anyone know of a way to get bash to read raw hex/uint data?
https://redd.it/1dor7ss
@r_bash
Reddit
From the bash community on Reddit
Explore this post and more from the bash community
Is it possible to prevent debugfs printing it's version?
Is there any way to not have debugfs printing it's version before outputting the result of the command?
This noscript always outputs "
#!/bin/bash
file="/var/packages/Python3/INFO"
getcreatetime(){
# Get crtime or otime
inode=$(ls -i "$1" | awk '{print $1}')
filesys=$(df "$1" | grep '/' | awk '{print $1}')
readarray -t dbugfs < <(debugfs -R "stat <${inode}>" "$filesys")
echo "array line count: ${#dbugfs@}" # debug
for d in "${dbugfs@}"; do
echo "$d" | grep -E 'ctime|atime|mtime|crtime|otime'
done
}
getcreatetime "$file"
The noscript output:
# /volume1/noscripts/getcreatetime.sh
debugfs 1.44.1 (24-Mar-2018)
array line count: 15
ctime: 0x66348478:bc1cbfa4 -- Fri May 3 16:30:16 2024
atime: 0x6608e06d:0d3cf508 -- Sun Mar 31 15:02:53 2024
mtime: 0x65beb80c:054935ac -- Sun Feb 4 09:02:52 2024
crtime: 0x6607eb8f:2e7278fb -- Tue Jul 20 16:02:55 2432
​
https://redd.it/1dou64x
@r_bash
Is there any way to not have debugfs printing it's version before outputting the result of the command?
This noscript always outputs "
debugfs 1.44.1 (24-Mar-2018)" on the first line:#!/bin/bash
file="/var/packages/Python3/INFO"
getcreatetime(){
# Get crtime or otime
inode=$(ls -i "$1" | awk '{print $1}')
filesys=$(df "$1" | grep '/' | awk '{print $1}')
readarray -t dbugfs < <(debugfs -R "stat <${inode}>" "$filesys")
echo "array line count: ${#dbugfs@}" # debug
for d in "${dbugfs@}"; do
echo "$d" | grep -E 'ctime|atime|mtime|crtime|otime'
done
}
getcreatetime "$file"
The noscript output:
# /volume1/noscripts/getcreatetime.sh
debugfs 1.44.1 (24-Mar-2018)
array line count: 15
ctime: 0x66348478:bc1cbfa4 -- Fri May 3 16:30:16 2024
atime: 0x6608e06d:0d3cf508 -- Sun Mar 31 15:02:53 2024
mtime: 0x65beb80c:054935ac -- Sun Feb 4 09:02:52 2024
crtime: 0x6607eb8f:2e7278fb -- Tue Jul 20 16:02:55 2432
​
https://redd.it/1dou64x
@r_bash
Reddit
From the bash community on Reddit
Explore this post and more from the bash community
Command result in terminal
Hi
I'm tryimg to use fzf inside a directory and the result should be pasted onto the command-line( not as a stdout, but should be available in the terminal)
I have something like this
#!/bin/bash
test() {
FZF_DEFAULT_OPTS_FILE='' fzf "$@" |
while read -r item; do
printf '%q ' "$item" # escape special chars
done
}
bind -m emacs-standard '"\C-t": " \C-b\C-k \C-u`test`\e\C-e\er\C-a\C-y\C-h\C-e\e \C-y\ey\C-x\C-x\C-f"'
Which is working, but i don't want to use the bind.
I want just to run the noscript from command line.
So instead of the bind i want only the call to test function.
In this case the result is simply printed to the screen.
Thank you.
https://redd.it/1douatw
@r_bash
Hi
I'm tryimg to use fzf inside a directory and the result should be pasted onto the command-line( not as a stdout, but should be available in the terminal)
I have something like this
#!/bin/bash
test() {
FZF_DEFAULT_OPTS_FILE='' fzf "$@" |
while read -r item; do
printf '%q ' "$item" # escape special chars
done
}
bind -m emacs-standard '"\C-t": " \C-b\C-k \C-u`test`\e\C-e\er\C-a\C-y\C-h\C-e\e \C-y\ey\C-x\C-x\C-f"'
Which is working, but i don't want to use the bind.
I want just to run the noscript from command line.
So instead of the bind i want only the call to test function.
In this case the result is simply printed to the screen.
Thank you.
https://redd.it/1douatw
@r_bash
Reddit
From the bash community on Reddit
Explore this post and more from the bash community
Jesus i need help with this 4 year journey
Disclaimer: I do not have admin password, i cant enter bios, and i cant use certain process that require admin on cmd.
Background info: Norton family is a child monotoring software that i want to bypass, i have tried over, and over again, for 4 years, nothing has worked on the internet. Norton family has a range of things you can do in it, like set time limits on a user, and restrict websites (i've bypassed restricted websites with a vpn), norton can also monitor data and send it to my dad. There is also an application called norton 360 that is like an antivirus thing, and its so annoying because it will just remove applications even though its not even a virus. Time restrictions work like this: every 5 seconds there will be a pop up window saying "you have reached your time limit" or something like that and you will be logged out and have to enter your password and it repeats, so last night i was playing with task manager, and decided to end task on one of the norton family processes, and it worked! the pop up didnt happen.... But i realised it would make a new process of the one i ended and i would have to keep ending the task.
*What i need done (if you want to help)*:
Can someone make a software that will kill a proccess in my task manager called "Norton Family", the problem is:, When i do it manually i have to keep doing it every 5 seconds, so its kinda annoying.There are two proccess that are called norton family, the one i want to end the process with is the one without the drop down box (actually it might have a drop down box but we'll get to that later on). There should be a drop down box in the Norton Family process, and inside it there should be a gear icon that says "Norton Family", thats the process i dont want to end, but in the other process also called "Norton family" there should be no drop down box, thats the one i want to end, BUT i've noticed that the first time i end the Norton family application without the drop down box it will end for 5 seconds, before making a new process of itself and then i have a few seconds to end it before the pop up window.But when that new process is made again after i end the old one there is now a drop down box, and inside it theres a thing called "Norton family" (Again) that has a window icon, that thing inside the drop down box is just a window on my pc that says norton family needs a restart, i always click no, lol, so pretty harmless.
By the way, the reason i want to end a specific task of Norton family is because if i try to end the task with the drop down box that has a gear icon in it, it will just say you need admin privileges where as the other one wont say that.
If you have any questions feel free to ask, and i also have norton 360 on my laptop
https://redd.it/1dp844f
@r_bash
Disclaimer: I do not have admin password, i cant enter bios, and i cant use certain process that require admin on cmd.
Background info: Norton family is a child monotoring software that i want to bypass, i have tried over, and over again, for 4 years, nothing has worked on the internet. Norton family has a range of things you can do in it, like set time limits on a user, and restrict websites (i've bypassed restricted websites with a vpn), norton can also monitor data and send it to my dad. There is also an application called norton 360 that is like an antivirus thing, and its so annoying because it will just remove applications even though its not even a virus. Time restrictions work like this: every 5 seconds there will be a pop up window saying "you have reached your time limit" or something like that and you will be logged out and have to enter your password and it repeats, so last night i was playing with task manager, and decided to end task on one of the norton family processes, and it worked! the pop up didnt happen.... But i realised it would make a new process of the one i ended and i would have to keep ending the task.
*What i need done (if you want to help)*:
Can someone make a software that will kill a proccess in my task manager called "Norton Family", the problem is:, When i do it manually i have to keep doing it every 5 seconds, so its kinda annoying.There are two proccess that are called norton family, the one i want to end the process with is the one without the drop down box (actually it might have a drop down box but we'll get to that later on). There should be a drop down box in the Norton Family process, and inside it there should be a gear icon that says "Norton Family", thats the process i dont want to end, but in the other process also called "Norton family" there should be no drop down box, thats the one i want to end, BUT i've noticed that the first time i end the Norton family application without the drop down box it will end for 5 seconds, before making a new process of itself and then i have a few seconds to end it before the pop up window.But when that new process is made again after i end the old one there is now a drop down box, and inside it theres a thing called "Norton family" (Again) that has a window icon, that thing inside the drop down box is just a window on my pc that says norton family needs a restart, i always click no, lol, so pretty harmless.
By the way, the reason i want to end a specific task of Norton family is because if i try to end the task with the drop down box that has a gear icon in it, it will just say you need admin privileges where as the other one wont say that.
If you have any questions feel free to ask, and i also have norton 360 on my laptop
https://redd.it/1dp844f
@r_bash
Reddit
From the bash community on Reddit
Explore this post and more from the bash community
how do you put human format in command identify for file size?
Hi, I use the comand identify (from IamgeMagic version6, the old version built-in at Lubuntu OS).
I'd like to retrieve in Vim the output of this command with file size in Kb or Mb, like using the flag -h in ls -lh ...
the command that I use in Vim is this:
r !identify -format "\%f [\%m \%xx\%hPixels \%[size]ytes] \n" path/to/*
this comand only shows %[size]ytes like this 444323bytes
I'd like to see 444.323Mbytes
The command work well fine and I understand the command, I only need what letter should and where put it in the command.
help man identify in C L I and https://www.imagemagick.org/noscript/identify.php
Thank you so much and Regards!
https://redd.it/1dpgw7j
@r_bash
Hi, I use the comand identify (from IamgeMagic version6, the old version built-in at Lubuntu OS).
I'd like to retrieve in Vim the output of this command with file size in Kb or Mb, like using the flag -h in ls -lh ...
the command that I use in Vim is this:
r !identify -format "\%f [\%m \%xx\%hPixels \%[size]ytes] \n" path/to/*
this comand only shows %[size]ytes like this 444323bytes
I'd like to see 444.323Mbytes
The command work well fine and I understand the command, I only need what letter should and where put it in the command.
help man identify in C L I and https://www.imagemagick.org/noscript/identify.php
Thank you so much and Regards!
https://redd.it/1dpgw7j
@r_bash
ImageMagick
ImageMagick | Command-line Tools: Identify
ImageMagick is a powerful open-source software suite for creating, editing, converting, and manipulating images in over 200 formats. Ideal for developers, designers, and researchers.
Is bash good for the task I need?
Hi everyone,
I need to parse a directory structure and store each symlink in an array as a "source destination" pair, so each entry in the array will look like this:
source-a.png dest-a.png, source-b.png dest-b.png, source-c.png dest-c.png, ... and so on 1000 more entries
Once I have this array, I need to create a second array but now instead of parsing a directory tree, read out similar source-destination pair information from a file instead. After both arrays are filled, I need to compare them to identify which elements are missing or have been added.
The idea is that if I remove a source-destination pair (source-a.png dest-a.png) from the file, the next time the noscript runs, it removes the source-destination symlink from the filesystem as well. So, the point is to keep the symlinks on the filesystem in sync with the information from the file. That's why I need two arrays.
Given that there might be 1000 entries in both arrays, is it practical to do this with Bash, or should I consider implementing it in Go, which is a language I'm more familiar with than Python? I heard that Bash is slow when it comes to comparing two arrays.
Any suggestions appreciated.
https://redd.it/1dpqa09
@r_bash
Hi everyone,
I need to parse a directory structure and store each symlink in an array as a "source destination" pair, so each entry in the array will look like this:
source-a.png dest-a.png, source-b.png dest-b.png, source-c.png dest-c.png, ... and so on 1000 more entries
Once I have this array, I need to create a second array but now instead of parsing a directory tree, read out similar source-destination pair information from a file instead. After both arrays are filled, I need to compare them to identify which elements are missing or have been added.
The idea is that if I remove a source-destination pair (source-a.png dest-a.png) from the file, the next time the noscript runs, it removes the source-destination symlink from the filesystem as well. So, the point is to keep the symlinks on the filesystem in sync with the information from the file. That's why I need two arrays.
Given that there might be 1000 entries in both arrays, is it practical to do this with Bash, or should I consider implementing it in Go, which is a language I'm more familiar with than Python? I heard that Bash is slow when it comes to comparing two arrays.
Any suggestions appreciated.
https://redd.it/1dpqa09
@r_bash
Reddit
From the bash community on Reddit
Explore this post and more from the bash community
Where to Implement noscripts and how to manage them?
I have a noscript I made (my first), but want to know
1. Where to store it (I've read this is the best location:
2. How to manage them with Github and across multiple machines
I'm looking into Ansible for automating my environment setup (current machine is dying plus I anticipate a new job soon). And I just figured out GNU Stow for dotfiles. So in writing my first noscript (well it was actually my second time writing it), as well as the fact that I'll likely have 2 new machines to setup soon, I need to understand properly managing noscripts & between machines.
My problems:
1.) if I put noscript files on Github I believe they must be in a directory (for example:
2.). There is already a lot of crap in
I've already figured out:
1. How to get rid of my noscript's extension (.sh) by making this the first line:
2. how to make it so that you don't need to whole file address by putting it in a directory that is known to my PATH.
I am sorry I if this is a dumb question - honestly I'm far enough in my career I should already know this but I went through a bootcamp and have some knowledge gaps like this I'm working to fill.
I realize I'm probably over-thinking this. And should just add my personal noscripts to
Any help appreciated. Will post to a few relevant communities.
In summary:
1. Where to store personal noscripts
2. How to manage them with Github and across multiple machines
3. Any thoughts on managing noscripts with Ansible or similar?
https://redd.it/1dq0obx
@r_bash
I have a noscript I made (my first), but want to know
1. Where to store it (I've read this is the best location:
/usr/local/bin )2. How to manage them with Github and across multiple machines
I'm looking into Ansible for automating my environment setup (current machine is dying plus I anticipate a new job soon). And I just figured out GNU Stow for dotfiles. So in writing my first noscript (well it was actually my second time writing it), as well as the fact that I'll likely have 2 new machines to setup soon, I need to understand properly managing noscripts & between machines.
My problems:
1.) if I put noscript files on Github I believe they must be in a directory (for example:
noscripts ). The problem is I've read that user noscripts should be stored at /usr/local/bin not /usr/local/bin/noscripts for example.2.). There is already a lot of crap in
/usr/local/bin and I am wary of adding it all to Github/source control for fear of fouling something up.I've already figured out:
1. How to get rid of my noscript's extension (.sh) by making this the first line:
#!/bin/bash plus runningchmod +x2. how to make it so that you don't need to whole file address by putting it in a directory that is known to my PATH.
I am sorry I if this is a dumb question - honestly I'm far enough in my career I should already know this but I went through a bootcamp and have some knowledge gaps like this I'm working to fill.
I realize I'm probably over-thinking this. And should just add my personal noscripts to
/usr/local/bin/noscripts , add it to my path, and make the "noscripts" directory my git repo.Any help appreciated. Will post to a few relevant communities.
In summary:
1. Where to store personal noscripts
2. How to manage them with Github and across multiple machines
3. Any thoughts on managing noscripts with Ansible or similar?
https://redd.it/1dq0obx
@r_bash
Reddit
From the bash community on Reddit
Explore this post and more from the bash community