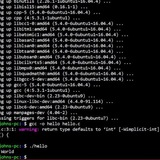
using parenthesis for execution
Is there any advantage or disadvantage to using parenthesis for the following execution of the "find" command:
as opposed to using the same command without the parenthesis like so:
Both seem to produce the same result, so don't fully understand the parenthesis in the first "find". I am trying to make sure that I understand when and when not to use the parenthesis considering that it can affect the flow of evaluation. Just thought in this example it would not have mattered.
thanks for the help
https://redd.it/1ml3au5
@r_bash
Is there any advantage or disadvantage to using parenthesis for the following execution of the "find" command:
sudo find / \( -mtime +30 -iname '*.zip' \) -exec cp {} /home/donnie \;as opposed to using the same command without the parenthesis like so:
sudo find / -mtime +30 -iname '*.zip' -exec cp {} /home/donnie \;Both seem to produce the same result, so don't fully understand the parenthesis in the first "find". I am trying to make sure that I understand when and when not to use the parenthesis considering that it can affect the flow of evaluation. Just thought in this example it would not have mattered.
thanks for the help
https://redd.it/1ml3au5
@r_bash
Reddit
From the bash community on Reddit
Explore this post and more from the bash community
how do we use the flag "-F" (-F from ls -Fla) in find?
Hi, I'd like to know if we can use a "highligt" for dirs in the output of find ./ -name 'something' for diff between dirs and files ...
Thank you and regards!
https://redd.it/1mls1tg
@r_bash
Hi, I'd like to know if we can use a "highligt" for dirs in the output of find ./ -name 'something' for diff between dirs and files ...
Thank you and regards!
https://redd.it/1mls1tg
@r_bash
Reddit
From the bash community on Reddit
Explore this post and more from the bash community
I can't see the advantage of vdir vs. ls -l cmd
**Hi**, I was reading about vdir (https://www.reddit.com/r/vim/comments/1midti4/vidir_and_vipe_command_utilities_that_use_vim/) and reading man vdir it is like ls -l
*What is the use of vdir cmd? what is its advantage?
*Thank you and Regards!*
https://redd.it/1mmknd6
@r_bash
**Hi**, I was reading about vdir (https://www.reddit.com/r/vim/comments/1midti4/vidir_and_vipe_command_utilities_that_use_vim/) and reading man vdir it is like ls -l
*What is the use of vdir cmd? what is its advantage?
*Thank you and Regards!*
https://redd.it/1mmknd6
@r_bash
Reddit
From the vim community on Reddit
Explore this post and more from the vim community
I made pentesting tool in bash can anyone have a look and provide commentary on my work
https://github.com/timeup48/UltimateMacHack/tree/main
https://redd.it/1mmfiqq
@r_bash
https://github.com/timeup48/UltimateMacHack/tree/main
https://redd.it/1mmfiqq
@r_bash
GitHub
GitHub - timeup48/SHADOWM: (SHADOWM) Macbook Web vulnerabilty hacking tool All in one
(SHADOWM) Macbook Web vulnerabilty hacking tool All in one - timeup48/SHADOWM
Is my code good enough?
#NO slashes ( / ) at the end of the string!
startFolder="/media/sam/T7/Windows recovered files"
destinationFolder="/media/sam/T7/Windows sorted files"
#double check file extensions
#should NOT have a period ( . ) at the start
extensions=("png" "jpg" "py" "pyc" "noscript" "txt" "mp4" "ogg" "java")
declare -A counters
for extension in "${extensions@}"
do
mkdir -p "$destinationFolder/$extension"
counters$extension=0
done
folders=$(ls "$startFolder")
arrFolders=()
for folder in $folders;do
arrFolders+=($folder)
done
folderAmount=${#arrFolders@}
echo $folderAmount folders
completed=0
for folder in $folders;do
completed=$((completed+1))
percentage=$(((completed100)/folderAmount))
files=$(ls "$startFolder/$folder")
for file in $files;do
for extension in "${extensions[@]}";do
if [[ $file == ".$extension" ]];then
filePath="$startFolder/$folder/$file"
number="${counters[$extension]}"
destPath="$destinationFolder/$extension/$number.$extension"
echo -n -e "\r\e[0K$completed/$folderAmount $percentage% $filePath -> $destPath"
mv "$filePath" "$destPath"
counters[$extension]=$((counters[$extension]+1))
break
fi
done
done
done
echo #NO slashes ( / ) at the end of the string!
startFolder="/media/sam/T7/Windows recovered files"
destinationFolder="/media/sam/T7/Windows sorted files"
#double check file extensions
#should NOT have a period ( . ) at the start
extensions=("png" "jpg" "py" "pyc" "noscript" "txt" "mp4" "ogg" "java")
declare -A counters
for extension in "${extensions[@]}"
do
mkdir -p "$destinationFolder/$extension"
counters[$extension]=0
done
folders=$(ls "$startFolder")
arrFolders=()
for folder in $folders;do
arrFolders+=($folder)
done
folderAmount=${#arrFolders[@]}
echo $folderAmount folders
completed=0
for folder in $folders;do
completed=$((completed+1))
percentage=$(((completed100)/folderAmount))
files=$(ls "$startFolder/$folder")
for file in $files;do
for extension in "${extensions@}";do
if [ $file == *".$extension"* ];then
filePath="$startFolder/$folder/$file"
number="${counters$extension}"
destPath="$destinationFolder/$extension/$number.$extension"
echo -n -e "\r\e0K$completed/$folderAmount $percentage% $filePath -> $destPath"
mv "$filePath" "$destPath"
counters[$extension=$((counters$extension+1))
break
fi
done
done
done
echo
It organized the folders generated by PhotoRec (salvaging files from a corrupt filesystem).
The code isn't very user friendly, but it gets the job done (although slowly)
I have released it on GitHub with additional instructions: https://github.com/justbanana9999/Arrange-by-file-type-PhotoRec-
https://redd.it/1mno9dm
@r_bash
#NO slashes ( / ) at the end of the string!
startFolder="/media/sam/T7/Windows recovered files"
destinationFolder="/media/sam/T7/Windows sorted files"
#double check file extensions
#should NOT have a period ( . ) at the start
extensions=("png" "jpg" "py" "pyc" "noscript" "txt" "mp4" "ogg" "java")
declare -A counters
for extension in "${extensions@}"
do
mkdir -p "$destinationFolder/$extension"
counters$extension=0
done
folders=$(ls "$startFolder")
arrFolders=()
for folder in $folders;do
arrFolders+=($folder)
done
folderAmount=${#arrFolders@}
echo $folderAmount folders
completed=0
for folder in $folders;do
completed=$((completed+1))
percentage=$(((completed100)/folderAmount))
files=$(ls "$startFolder/$folder")
for file in $files;do
for extension in "${extensions[@]}";do
if [[ $file == ".$extension" ]];then
filePath="$startFolder/$folder/$file"
number="${counters[$extension]}"
destPath="$destinationFolder/$extension/$number.$extension"
echo -n -e "\r\e[0K$completed/$folderAmount $percentage% $filePath -> $destPath"
mv "$filePath" "$destPath"
counters[$extension]=$((counters[$extension]+1))
break
fi
done
done
done
echo #NO slashes ( / ) at the end of the string!
startFolder="/media/sam/T7/Windows recovered files"
destinationFolder="/media/sam/T7/Windows sorted files"
#double check file extensions
#should NOT have a period ( . ) at the start
extensions=("png" "jpg" "py" "pyc" "noscript" "txt" "mp4" "ogg" "java")
declare -A counters
for extension in "${extensions[@]}"
do
mkdir -p "$destinationFolder/$extension"
counters[$extension]=0
done
folders=$(ls "$startFolder")
arrFolders=()
for folder in $folders;do
arrFolders+=($folder)
done
folderAmount=${#arrFolders[@]}
echo $folderAmount folders
completed=0
for folder in $folders;do
completed=$((completed+1))
percentage=$(((completed100)/folderAmount))
files=$(ls "$startFolder/$folder")
for file in $files;do
for extension in "${extensions@}";do
if [ $file == *".$extension"* ];then
filePath="$startFolder/$folder/$file"
number="${counters$extension}"
destPath="$destinationFolder/$extension/$number.$extension"
echo -n -e "\r\e0K$completed/$folderAmount $percentage% $filePath -> $destPath"
mv "$filePath" "$destPath"
counters[$extension=$((counters$extension+1))
break
fi
done
done
done
echo
It organized the folders generated by PhotoRec (salvaging files from a corrupt filesystem).
The code isn't very user friendly, but it gets the job done (although slowly)
I have released it on GitHub with additional instructions: https://github.com/justbanana9999/Arrange-by-file-type-PhotoRec-
https://redd.it/1mno9dm
@r_bash
GitHub
GitHub - justbanana9999/Arrange-by-file-type-PhotoRec-: Organize files generated by PhotoRec into a new directory.
Organize files generated by PhotoRec into a new directory. - justbanana9999/Arrange-by-file-type-PhotoRec-
timep: a next-gen time-profiler and flamegraph-generator for bash code
`timep` is a **time p**rofiler for bash code that will give you a per-command execution time breakdown of any bash noscript or function.
Unlike other profilers, `timep` records both wall-clock time and cpu time (via a loadable builtin that is base64 encoded in the noscript and automatically sets itself up when you source timep.bash). Also unlike other profilers, `timep also recovers and hierarchially records metadata on subshell and function nesting, allowing it to recreate the full call-stack tree for that bash code.
***
**BASH-NATIVE FLAMEGRAPHS**
If you call `timep` with the `--flame` flag, it will automatically generate a BASH-NATIVE flamegraph .noscript image (where each top-level block represents the wall-clock time spent on a particular command, and all the lower level blocks represent the combined time spent in the parent subshells/functions...this is not a perf flamegraph showing syscalls). Furthermore, Ive added a new colorscheme to the flamegraph generation noscript that will:
1. color things that take up more time with hotter colors (normal flamegraph coloring is "random but consistent for a given function name")
2. desaturate commands with low cpu time/ wall time ratio (e.g., wait, sleep, blocking reads, etc)
3. empirically remap the colors using a runtime-weighted CDF so that the colorscale is evenly used in the flamegraph and so extremes dont dominate the coloring
4. multiple flamegraphs are stacked vertically in the same noscript image.
[HERE](https://raw.githubusercontent.com/jkool702/timep/main/TESTS/FORKRUN/flamegraphs/flamegraph.ALL.noscript) is an example of what they look like (details near the bottom of this post).
***
**USAGE**
To use `timep`, download and source the `timep.bash` file from the github repo, then just add `timep` before whatever you want to profile. `timep` handles everything else, including (when needed) redirecting stdin to whatever is being profiled. ZERO changes need to be made to the code you want to profile. Example usage:
. timep.bash
timep someFunc <input_file
timep --flame /path/to/someScript.bash
timep -c 'command1' 'command2'
`timep` will create 2 time profiles for you - one that has every single command and full metadata, and one that combines commands repeated in loops and only shows run count + total runtime for each command. By default the 2nd one is shown, but this is configurable via thge '-o' flag and both profiles are always saved to disk.
For more info refer to the README on github and the comments at the top of timep.bash.
**DEPENDENCIES**: the major dependencies are bash 5+ and a mounted procfs. Various common commandline tools (sed, grep, cat, tail, ...) are required as well. This basically means you have to be running linux for timep to work.
* bash 5+ is required because timep fundamentally works by recording `$EPOCHREALTIME` timestamps. In theory you could probably replace each `${EPOCHREALTIME}` with `$(date +"%s.%6N")` to get it to run at bash 4, but it would be considerably less accurate and less efficient.
* mounted procfs it required to read several things (PPID, PGID, TPID, CTTY, PCOMM) from `/proc/<pid>/stat`. `timep` needs these to correctly re-create the call-stack tree. It *might* be possible to get these things from external tools, which would (at the cost of efficiency) allow `timep` to be used outsude of linux. But this would be a considerable undertaking.
***
**EXAMPLES**
Heres an example of the type of output timep generates.
```
testfunc() { f() { echo "f: $*"; }
g() ( echo "g: $*"; )
h() { echo "h: $*"; ff "$@"; gg "$@"; }
echo 0
{ echo 1; }
( echo 2 )
echo 3 &
{ echo 4; } &
echo 5 | cat | tee
for (( kk=6; kk<10; kk++ )); do
echo $kk
h $kk
for jj in {1..3}; do
f $kk $jj
g $kk $jj
done
done
}
timep testfunc
gives
LINE.DEPTH.CMD NUMBER COMBINED WALL-CLOCK TIME COMBINED CPU TIME COMMAND
`timep` is a **time p**rofiler for bash code that will give you a per-command execution time breakdown of any bash noscript or function.
Unlike other profilers, `timep` records both wall-clock time and cpu time (via a loadable builtin that is base64 encoded in the noscript and automatically sets itself up when you source timep.bash). Also unlike other profilers, `timep also recovers and hierarchially records metadata on subshell and function nesting, allowing it to recreate the full call-stack tree for that bash code.
***
**BASH-NATIVE FLAMEGRAPHS**
If you call `timep` with the `--flame` flag, it will automatically generate a BASH-NATIVE flamegraph .noscript image (where each top-level block represents the wall-clock time spent on a particular command, and all the lower level blocks represent the combined time spent in the parent subshells/functions...this is not a perf flamegraph showing syscalls). Furthermore, Ive added a new colorscheme to the flamegraph generation noscript that will:
1. color things that take up more time with hotter colors (normal flamegraph coloring is "random but consistent for a given function name")
2. desaturate commands with low cpu time/ wall time ratio (e.g., wait, sleep, blocking reads, etc)
3. empirically remap the colors using a runtime-weighted CDF so that the colorscale is evenly used in the flamegraph and so extremes dont dominate the coloring
4. multiple flamegraphs are stacked vertically in the same noscript image.
[HERE](https://raw.githubusercontent.com/jkool702/timep/main/TESTS/FORKRUN/flamegraphs/flamegraph.ALL.noscript) is an example of what they look like (details near the bottom of this post).
***
**USAGE**
To use `timep`, download and source the `timep.bash` file from the github repo, then just add `timep` before whatever you want to profile. `timep` handles everything else, including (when needed) redirecting stdin to whatever is being profiled. ZERO changes need to be made to the code you want to profile. Example usage:
. timep.bash
timep someFunc <input_file
timep --flame /path/to/someScript.bash
timep -c 'command1' 'command2'
`timep` will create 2 time profiles for you - one that has every single command and full metadata, and one that combines commands repeated in loops and only shows run count + total runtime for each command. By default the 2nd one is shown, but this is configurable via thge '-o' flag and both profiles are always saved to disk.
For more info refer to the README on github and the comments at the top of timep.bash.
**DEPENDENCIES**: the major dependencies are bash 5+ and a mounted procfs. Various common commandline tools (sed, grep, cat, tail, ...) are required as well. This basically means you have to be running linux for timep to work.
* bash 5+ is required because timep fundamentally works by recording `$EPOCHREALTIME` timestamps. In theory you could probably replace each `${EPOCHREALTIME}` with `$(date +"%s.%6N")` to get it to run at bash 4, but it would be considerably less accurate and less efficient.
* mounted procfs it required to read several things (PPID, PGID, TPID, CTTY, PCOMM) from `/proc/<pid>/stat`. `timep` needs these to correctly re-create the call-stack tree. It *might* be possible to get these things from external tools, which would (at the cost of efficiency) allow `timep` to be used outsude of linux. But this would be a considerable undertaking.
***
**EXAMPLES**
Heres an example of the type of output timep generates.
```
testfunc() { f() { echo "f: $*"; }
g() ( echo "g: $*"; )
h() { echo "h: $*"; ff "$@"; gg "$@"; }
echo 0
{ echo 1; }
( echo 2 )
echo 3 &
{ echo 4; } &
echo 5 | cat | tee
for (( kk=6; kk<10; kk++ )); do
echo $kk
h $kk
for jj in {1..3}; do
f $kk $jj
g $kk $jj
done
done
}
timep testfunc
gives
LINE.DEPTH.CMD NUMBER COMBINED WALL-CLOCK TIME COMBINED CPU TIME COMMAND
<line>.<depth>.<cmd>: ( time | cur depth % | total % ) ( time | cur depth % | total % ) (count) <command>
_____________________ ________________________________ ________________________________ ____________________________________
9.0.0: ( 0.025939s |100.00% ) ( 0.024928s |100.00% ) (1x) << (FUNCTION): main.testfunc "${@}" >>
├─ 1.1.0: ( 0.000062s | 0.23% ) ( 0.000075s | 0.30% ) (1x) ├─ testfunc "${@}"
│ │
│ 8.1.0: ( 0.000068s | 0.26% ) ( 0.000081s | 0.32% ) (1x) │ echo 0
│ │
│ 9.1.0: ( 0.000989s | 3.81% ) ( 0.000892s | 3.57% ) (1x) │ echo 1
│ │
│ 10.1.0: ( 0.000073s | 0.28% ) ( 0.000088s | 0.35% ) (1x) │ << (SUBSHELL) >>
│ └─ 10.2.0: ( 0.000073s |100.00% | 0.28% ) ( 0.000088s |100.00% | 0.35% ) (1x) │ └─ echo 2
│ │
│ 11.1.0: ( 0.000507s | 1.95% ) ( 0.000525s | 2.10% ) (1x) │ echo 3 (&)
│ │
│ 12.1.0: ( 0.003416s | 13.16% ) ( 0.000001s | 0.00% ) (1x) │ << (BACKGROUND FORK) >>
│ └─ 12.2.0: ( 0.000297s |100.00% | 1.14% ) ( 0.000341s |100.00% | 1.36% ) (1x) │ └─ echo 4
│ │
│ 13.1.0: ( 0.000432s | 1.66% ) ( 0.000447s | 1.79% ) (1x) │ echo 5
│ │
│ 13.1.1: ( 0.000362s | 1.39% ) ( 0.000376s | 1.50% ) (1x) │ cat
│ │
│ 13.1.2: ( 0.003441s | 13.26% ) ( 0.006943s | 27.85% ) (1x) │ tee | ((kk=6)) | ((kk<10))
│ │
│ 15.1.0: ( 0.000242s | 0.93% ) ( 0.000295s | 1.18% ) (4x) │ ((kk++ ))
│ │
│ 16.1.0: ( 0.000289s | 1.11% ) ( 0.000344s | 1.37% ) (4x) │ echo $kk
│ │
│ 17.1.0: ( 0.003737s | 3.59% | 14.40% ) ( 0.003476s | 3.48% | 13.94% ) (4x) │ << (FUNCTION): main.testfunc.h $kk >>
│ ├─ 1.2.0: ( 0.000231s | 6.20% | 0.89% ) ( 0.000285s | 8.22% | 1.14% ) (4x) │ ├─ h $kk
│ │ 8.2.0: ( 0.000302s | 8.07% | 1.16% ) ( 0.000376s | 10.84% | 1.50% ) (4x) │ │ echo "h: $*"
│ │ 9.2.0: ( 0.000548s | 14.72% | 2.11% ) ( 0.000656s | 18.96% | 2.63% ) (4x) │ │ << (FUNCTION): main.testfunc.h.f "$@" >>
│ │ ├─ 1.3.0: ( 0.000232s | 42.57% | 0.89% ) ( 0.000287s |
_____________________ ________________________________ ________________________________ ____________________________________
9.0.0: ( 0.025939s |100.00% ) ( 0.024928s |100.00% ) (1x) << (FUNCTION): main.testfunc "${@}" >>
├─ 1.1.0: ( 0.000062s | 0.23% ) ( 0.000075s | 0.30% ) (1x) ├─ testfunc "${@}"
│ │
│ 8.1.0: ( 0.000068s | 0.26% ) ( 0.000081s | 0.32% ) (1x) │ echo 0
│ │
│ 9.1.0: ( 0.000989s | 3.81% ) ( 0.000892s | 3.57% ) (1x) │ echo 1
│ │
│ 10.1.0: ( 0.000073s | 0.28% ) ( 0.000088s | 0.35% ) (1x) │ << (SUBSHELL) >>
│ └─ 10.2.0: ( 0.000073s |100.00% | 0.28% ) ( 0.000088s |100.00% | 0.35% ) (1x) │ └─ echo 2
│ │
│ 11.1.0: ( 0.000507s | 1.95% ) ( 0.000525s | 2.10% ) (1x) │ echo 3 (&)
│ │
│ 12.1.0: ( 0.003416s | 13.16% ) ( 0.000001s | 0.00% ) (1x) │ << (BACKGROUND FORK) >>
│ └─ 12.2.0: ( 0.000297s |100.00% | 1.14% ) ( 0.000341s |100.00% | 1.36% ) (1x) │ └─ echo 4
│ │
│ 13.1.0: ( 0.000432s | 1.66% ) ( 0.000447s | 1.79% ) (1x) │ echo 5
│ │
│ 13.1.1: ( 0.000362s | 1.39% ) ( 0.000376s | 1.50% ) (1x) │ cat
│ │
│ 13.1.2: ( 0.003441s | 13.26% ) ( 0.006943s | 27.85% ) (1x) │ tee | ((kk=6)) | ((kk<10))
│ │
│ 15.1.0: ( 0.000242s | 0.93% ) ( 0.000295s | 1.18% ) (4x) │ ((kk++ ))
│ │
│ 16.1.0: ( 0.000289s | 1.11% ) ( 0.000344s | 1.37% ) (4x) │ echo $kk
│ │
│ 17.1.0: ( 0.003737s | 3.59% | 14.40% ) ( 0.003476s | 3.48% | 13.94% ) (4x) │ << (FUNCTION): main.testfunc.h $kk >>
│ ├─ 1.2.0: ( 0.000231s | 6.20% | 0.89% ) ( 0.000285s | 8.22% | 1.14% ) (4x) │ ├─ h $kk
│ │ 8.2.0: ( 0.000302s | 8.07% | 1.16% ) ( 0.000376s | 10.84% | 1.50% ) (4x) │ │ echo "h: $*"
│ │ 9.2.0: ( 0.000548s | 14.72% | 2.11% ) ( 0.000656s | 18.96% | 2.63% ) (4x) │ │ << (FUNCTION): main.testfunc.h.f "$@" >>
│ │ ├─ 1.3.0: ( 0.000232s | 42.57% | 0.89% ) ( 0.000287s |
43.92% | 1.15% ) (4x) │ │ ├─ f "$@"
│ │ └─ 8.3.0: ( 0.000316s | 57.41% | 1.21% ) ( 0.000369s | 56.06% | 1.48% ) (4x) │ │ └─ echo "f: $*"
│ │ 10.2.0: ( 0.002656s | 70.98% | 10.23% ) ( 0.002159s | 61.94% | 8.66% ) (4x) │ │ << (FUNCTION): main.testfunc.h.g "$@" >>
│ │ ├─ 1.3.0: ( 0.002308s | 86.90% | 8.89% ) ( 0.001753s | 81.17% | 7.03% ) (4x) │ │ ├─ g "$@"
│ │ │ 408.3.0: ( 0.000348s | 13.08% | 1.34% ) ( 0.000406s | 18.81% | 1.62% ) (4x) │ │ │ << (SUBSHELL) >>
│ └─ └─ └─ 408.4.0: ( 0.000348s |100.00% | 1.34% ) ( 0.000406s |100.00% | 1.62% ) (4x) │ └─ └─ └─ echo "g: $*"
│ │
│ 18.1.0: ( 0.000716s | 2.76% ) ( 0.000873s | 3.50% ) (12x) │ for jj in {1..3}
│ │
│ 19.1.0: ( 0.001597s | 0.50% | 6.15% ) ( 0.001907s | 0.63% | 7.65% ) (12x) │ << (FUNCTION): main.testfunc.f $kk $jj >>
│ ├─ 1.2.0: ( 0.000693s | 43.40% | 2.67% ) ( 0.000844s | 44.26% | 3.38% ) (12x) │ ├─ f $kk $jj
│ └─ 8.2.0: ( 0.000904s | 56.58% | 3.48% ) ( 0.001063s | 55.72% | 4.26% ) (12x) │ └─ echo "f: $*"
│ │
│ 20.1.0: ( 0.009758s | 3.12% | 37.61% ) ( 0.008306s | 2.77% | 33.31% ) (12x) │ << (FUNCTION): main.testfunc.g $kk $jj >>
│ ├─ 1.2.0: ( 0.008494s | 86.78% | 32.74% ) ( 0.006829s | 81.25% | 27.39% ) (12x) │ ├─ g $kk $jj
│ │ 408.2.0: ( 0.001264s | 13.20% | 4.87% ) ( 0.001477s | 18.73% | 5.92% ) (12x) │ │ << (SUBSHELL) >>
└─ └─ └─ 408.3.0: ( 0.001264s |100.00% | 4.87% ) ( 0.001477s |100.00% | 5.92% ) (12x) └─ └─ └─ └─ echo "g: $*"
TOTAL RUN TIME: 0.025939s
TOTAL CPU TIME: 0.024928s
A example on a complex real code: some of you here may have heard of another one of my projects: [forkrun](https://github.com/jkool702/forkrun). It is a tool that runs code for you in parallel using bash coprocs. i used timep on forkrun computing 13 different checksums of a bunch (~620k) of small files (~14gb total) on a ramdisk...twice (in total ~16.1 million checksums on 384 gb worth of (repeated) data). I figure this is a good test, since not only is forkrun a technically challenging code to profile, but it is a highly parallel workload. On my 14c/28t i9-7940x this run (with 28 active workers), on average, used just under 23 cores worth of CPU time. the exact code to setup this test is below:
mount | grep -F '/mnt/ramdisk' | grep -q 'tmpfs' || sudo mount -t tmpfs tmpfs /mnt/ramdisk
mkdir -p /mnt/ramdisk/usr
rsync -a --max-size=$((1<<22)) /usr/* /mnt/ramdisk/usr
find /mnt/ramdisk/usr -type f >/mnt/ramdisk/flist
find /mnt/ramdisk/usr -type f -print0 >/mnt/ramdisk/flist0
ff() {
sha1sum "${@}"
sha256sum "${@}"
sha512sum "${@}"
sha224sum "${@}"
sha384sum "${@}"
md5sum "${@}"
sum -s "${@}"
sum -r "${@}"
cksum "${@}"
b2sum "${@}"
cksum -a sm3 "${@}"
xxhsum "${@}"
xxhsum -H3 "${@}"
}
export -f ff
timep --flame -c 'forkrun ff </mnt/ramdisk/flist >/dev/null' 'forkrun -z ff </mnt/ramdisk/flist0 >/dev/null;'
[HERE IS THE TIME PROFILE](https://github.com/jkool702/timep/blob/main/TESTS/FORKRUN/out.profile) and [HERE IS THE FLAMEGRAPH](https://raw.githubusercontent.com/jkool702/timep/main/TESTS/FORKRUN/flamegraphs/flamegraph.ALL.noscript) it generated. (note: to make it zoom in when you click it you'll probably need to download it then open it). You can see
│ │ └─ 8.3.0: ( 0.000316s | 57.41% | 1.21% ) ( 0.000369s | 56.06% | 1.48% ) (4x) │ │ └─ echo "f: $*"
│ │ 10.2.0: ( 0.002656s | 70.98% | 10.23% ) ( 0.002159s | 61.94% | 8.66% ) (4x) │ │ << (FUNCTION): main.testfunc.h.g "$@" >>
│ │ ├─ 1.3.0: ( 0.002308s | 86.90% | 8.89% ) ( 0.001753s | 81.17% | 7.03% ) (4x) │ │ ├─ g "$@"
│ │ │ 408.3.0: ( 0.000348s | 13.08% | 1.34% ) ( 0.000406s | 18.81% | 1.62% ) (4x) │ │ │ << (SUBSHELL) >>
│ └─ └─ └─ 408.4.0: ( 0.000348s |100.00% | 1.34% ) ( 0.000406s |100.00% | 1.62% ) (4x) │ └─ └─ └─ echo "g: $*"
│ │
│ 18.1.0: ( 0.000716s | 2.76% ) ( 0.000873s | 3.50% ) (12x) │ for jj in {1..3}
│ │
│ 19.1.0: ( 0.001597s | 0.50% | 6.15% ) ( 0.001907s | 0.63% | 7.65% ) (12x) │ << (FUNCTION): main.testfunc.f $kk $jj >>
│ ├─ 1.2.0: ( 0.000693s | 43.40% | 2.67% ) ( 0.000844s | 44.26% | 3.38% ) (12x) │ ├─ f $kk $jj
│ └─ 8.2.0: ( 0.000904s | 56.58% | 3.48% ) ( 0.001063s | 55.72% | 4.26% ) (12x) │ └─ echo "f: $*"
│ │
│ 20.1.0: ( 0.009758s | 3.12% | 37.61% ) ( 0.008306s | 2.77% | 33.31% ) (12x) │ << (FUNCTION): main.testfunc.g $kk $jj >>
│ ├─ 1.2.0: ( 0.008494s | 86.78% | 32.74% ) ( 0.006829s | 81.25% | 27.39% ) (12x) │ ├─ g $kk $jj
│ │ 408.2.0: ( 0.001264s | 13.20% | 4.87% ) ( 0.001477s | 18.73% | 5.92% ) (12x) │ │ << (SUBSHELL) >>
└─ └─ └─ 408.3.0: ( 0.001264s |100.00% | 4.87% ) ( 0.001477s |100.00% | 5.92% ) (12x) └─ └─ └─ └─ echo "g: $*"
TOTAL RUN TIME: 0.025939s
TOTAL CPU TIME: 0.024928s
A example on a complex real code: some of you here may have heard of another one of my projects: [forkrun](https://github.com/jkool702/forkrun). It is a tool that runs code for you in parallel using bash coprocs. i used timep on forkrun computing 13 different checksums of a bunch (~620k) of small files (~14gb total) on a ramdisk...twice (in total ~16.1 million checksums on 384 gb worth of (repeated) data). I figure this is a good test, since not only is forkrun a technically challenging code to profile, but it is a highly parallel workload. On my 14c/28t i9-7940x this run (with 28 active workers), on average, used just under 23 cores worth of CPU time. the exact code to setup this test is below:
mount | grep -F '/mnt/ramdisk' | grep -q 'tmpfs' || sudo mount -t tmpfs tmpfs /mnt/ramdisk
mkdir -p /mnt/ramdisk/usr
rsync -a --max-size=$((1<<22)) /usr/* /mnt/ramdisk/usr
find /mnt/ramdisk/usr -type f >/mnt/ramdisk/flist
find /mnt/ramdisk/usr -type f -print0 >/mnt/ramdisk/flist0
ff() {
sha1sum "${@}"
sha256sum "${@}"
sha512sum "${@}"
sha224sum "${@}"
sha384sum "${@}"
md5sum "${@}"
sum -s "${@}"
sum -r "${@}"
cksum "${@}"
b2sum "${@}"
cksum -a sm3 "${@}"
xxhsum "${@}"
xxhsum -H3 "${@}"
}
export -f ff
timep --flame -c 'forkrun ff </mnt/ramdisk/flist >/dev/null' 'forkrun -z ff </mnt/ramdisk/flist0 >/dev/null;'
[HERE IS THE TIME PROFILE](https://github.com/jkool702/timep/blob/main/TESTS/FORKRUN/out.profile) and [HERE IS THE FLAMEGRAPH](https://raw.githubusercontent.com/jkool702/timep/main/TESTS/FORKRUN/flamegraphs/flamegraph.ALL.noscript) it generated. (note: to make it zoom in when you click it you'll probably need to download it then open it). You can see
GitHub
GitHub - jkool702/forkrun: runs multiple inputs through a noscript/function in parallel using bash coprocs
runs multiple inputs through a noscript/function in parallel using bash coprocs - jkool702/forkrun
both runs, and for each run you can see all 28 workers (2nd layer from top) (all running in parallel) and for each worker you can see the 13 checksum algs (top layer), plus the function calls / subshell parent processes.
***
**ACCURACY**
The above examp[le highlights just how accurate timep's timings are. It computed a total combined CPU time of 1004.846468 seconds. It got that by summing together the cpu time from each of the ~65000 individual bash commands that the above test ram. When i ran the exact same test without timep (using both `time` and `perf stat` I consistently got between 1006 seconds and 1008 seconds total (sys+user) cpu time. meaning error in the combined CPU time was under 0.5%.
Its also worth noting that the profiling run itself (not counting post-processing) only took about 8% longer (both in CPU time and wall clock time). so overhead is fairly low to start with, and is very well corrected for in the output timing.
***
BUGS: I spent a LOT of effort to ensure that `timep` works for virtually any bash code. That said, bash does a bunch of weird stuff internally that makes that difficult.
There are a few known bugs (in particular in sequences of deeply nested subshells and background forks) where timep's output is subtly off in some trivial way (see README for details). There are probably some edge cases that ive missed as well. If you notice timep incorrectly profiling some particular code please let me know (comment here, or issue on github) and, if possible, ill do my best to fix it.
***
Hope you all find this useful! Let me know any thoughts / questions / comments below!
https://redd.it/1ml7l60
@r_bash
***
**ACCURACY**
The above examp[le highlights just how accurate timep's timings are. It computed a total combined CPU time of 1004.846468 seconds. It got that by summing together the cpu time from each of the ~65000 individual bash commands that the above test ram. When i ran the exact same test without timep (using both `time` and `perf stat` I consistently got between 1006 seconds and 1008 seconds total (sys+user) cpu time. meaning error in the combined CPU time was under 0.5%.
Its also worth noting that the profiling run itself (not counting post-processing) only took about 8% longer (both in CPU time and wall clock time). so overhead is fairly low to start with, and is very well corrected for in the output timing.
***
BUGS: I spent a LOT of effort to ensure that `timep` works for virtually any bash code. That said, bash does a bunch of weird stuff internally that makes that difficult.
There are a few known bugs (in particular in sequences of deeply nested subshells and background forks) where timep's output is subtly off in some trivial way (see README for details). There are probably some edge cases that ive missed as well. If you notice timep incorrectly profiling some particular code please let me know (comment here, or issue on github) and, if possible, ill do my best to fix it.
***
Hope you all find this useful! Let me know any thoughts / questions / comments below!
https://redd.it/1ml7l60
@r_bash
Reddit
From the bash community on Reddit
Explore this post and more from the bash community
gh-f and latest fzf releases
gh-f is the gh cli extension that seamlessly integrates with fzf! I have recently polished the look, including features from the latest fzf release (headers and footers), together with minor performance refactoring.
https://i.redd.it/a7ugs9aawuif1.gif
There are many more features available as shown in the gif: hop by the repository and have a look!
Link to the repository
https://redd.it/1mphk6z
@r_bash
gh-f is the gh cli extension that seamlessly integrates with fzf! I have recently polished the look, including features from the latest fzf release (headers and footers), together with minor performance refactoring.
https://i.redd.it/a7ugs9aawuif1.gif
There are many more features available as shown in the gif: hop by the repository and have a look!
Link to the repository
https://redd.it/1mphk6z
@r_bash
GitHub
GitHub - gennaro-tedesco/gh-f: 🔎 the ultimate compact fzf gh extension
🔎 the ultimate compact fzf gh extension. Contribute to gennaro-tedesco/gh-f development by creating an account on GitHub.
how do I know actual terminal in use?
Hi, I use Bash CLI but I need to check which terminal (qterminal vs. konsole) is open when vim calls terminal with vim' cmd :terminal an :shell.
these cmd's open terminal but which terminal is open? a cmd in it tells me which, what will be that cmd?
I tested tty cmd and who cmd...
Thank you and Regards!
https://redd.it/1mpvr2k
@r_bash
Hi, I use Bash CLI but I need to check which terminal (qterminal vs. konsole) is open when vim calls terminal with vim' cmd :terminal an :shell.
these cmd's open terminal but which terminal is open? a cmd in it tells me which, what will be that cmd?
I tested tty cmd and who cmd...
Thank you and Regards!
https://redd.it/1mpvr2k
@r_bash
Reddit
From the bash community on Reddit
Explore this post and more from the bash community
Help optimizing my bash noscript for cycling video/static wallpapers with mpvpaper and swww
https://codefile.io/f/ybOplh8ij6
https://redd.it/1mre3iy
@r_bash
https://codefile.io/f/ybOplh8ij6
https://redd.it/1mre3iy
@r_bash
Codefile.io
wallpaper_switch.sh — Codefile
Create collaborative code files online for your technical interviews, pair programming, teaching, etc.
how do you toogle capslock using the cmd setxkbmap?
Hi, I'd like to add an alias for toogle caps. in this way I will can reverse the cmd:
alias M='setxkbmap -option caps:escape'
and put in work the capslock key again doing again capslock and not more escape.
Thank you and regards!
https://redd.it/1mrsu2m
@r_bash
Hi, I'd like to add an alias for toogle caps. in this way I will can reverse the cmd:
alias M='setxkbmap -option caps:escape'
and put in work the capslock key again doing again capslock and not more escape.
Thank you and regards!
https://redd.it/1mrsu2m
@r_bash
Reddit
From the bash community on Reddit
Explore this post and more from the bash community
I created an Fortune 500 enterprise wide product utilizing -only- BASH noscript
Finally some utility from learning BASH. Gonna be honest though, I used AI to remind me syntax. Its been a while since I was a linux admin.
Its an alerting solution for business functions that need immediate support.
That is all. Just feels good to utilize a closet skill.
https://redd.it/1mt89q2
@r_bash
Finally some utility from learning BASH. Gonna be honest though, I used AI to remind me syntax. Its been a while since I was a linux admin.
Its an alerting solution for business functions that need immediate support.
That is all. Just feels good to utilize a closet skill.
https://redd.it/1mt89q2
@r_bash
Reddit
From the bash community on Reddit
Explore this post and more from the bash community