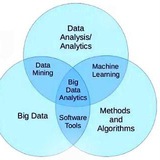
Процесс анализа данных:
Содержание
• 1 Определение проблемы
• 2 Извлечение данных
• 3 Подготовка данных
• 4 Изучение данных/визуализация
• 5 Предсказательная (предиктивная) модель
• 6 Проверка модели
• 7 Развертывание (деплой)
◦ 7.1 Обучение Python и Data Science
Анализ данных можно описать как процесс, состоящий из нескольких шагов, в которых сырые данные превращаются и обрабатываются с целью создать визуализации и сделать предсказания на основе математической модели
Читать далее
Содержание
• 1 Определение проблемы
• 2 Извлечение данных
• 3 Подготовка данных
• 4 Изучение данных/визуализация
• 5 Предсказательная (предиктивная) модель
• 6 Проверка модели
• 7 Развертывание (деплой)
◦ 7.1 Обучение Python и Data Science
Анализ данных можно описать как процесс, состоящий из нескольких шагов, в которых сырые данные превращаются и обрабатываются с целью создать визуализации и сделать предсказания на основе математической модели
Читать далее
👍4
Оценка эффективности процесса найма с помощью анализа данных
Мы все знаем, что IT-индустрия является одной из самых динамичных и развивающихся отраслей нашего времени. С формированием новых технологий и постоянным ростом числа IT-шников на рынке появляются новые вызовы и задачи, вызывающие интенсивный спрос на высококвалифицированных профессионалов в сфере рекрутинга. Это означает, что нам всем нужно постоянно улучшать нашу работу в рекрутинге, применяя новые методы и аналитические подходы.
Одним из таких методов является оценка эффективности процесса найма с помощью анализа данных. Эта техника оказывается …
https://habr.com/ru/companies/otus/articles/738288/
Мы все знаем, что IT-индустрия является одной из самых динамичных и развивающихся отраслей нашего времени. С формированием новых технологий и постоянным ростом числа IT-шников на рынке появляются новые вызовы и задачи, вызывающие интенсивный спрос на высококвалифицированных профессионалов в сфере рекрутинга. Это означает, что нам всем нужно постоянно улучшать нашу работу в рекрутинге, применяя новые методы и аналитические подходы.
Одним из таких методов является оценка эффективности процесса найма с помощью анализа данных. Эта техника оказывается …
https://habr.com/ru/companies/otus/articles/738288/
Хабр
Оценка эффективности процесса найма с помощью анализа данных
Автор статьи: Артем Михайлов Мы все знаем, что IT-индустрия является одной из самых динамичных и развивающихся отраслей нашего времени. С формированием новых технологий и постоянным ростом числа...
🔥4
PYTHON ANOVA test на Python – погружаемся в дисперсионный анализ.
В данном руководстве мы подробно обсудим анализ данных, в частности дисперсионный анализ (ANOVA), а также процесс его выполнения на языке программирования Python. ANOVA обычно используются в читать руководство
В данном руководстве мы подробно обсудим анализ данных, в частности дисперсионный анализ (ANOVA), а также процесс его выполнения на языке программирования Python. ANOVA обычно используются в читать руководство
👍4
Топ-38 вопросов для собеседования с аналитиком данных
Какие обязанности возлагаются на аналитиков данных?
Этот вопрос просит потенциальных аналитиков подумать о том, что будет входить в их обязанности в роли аналитика данных. К этому типу вопросов можно подготовиться, внимательно изучив описание вакансии перед собеседованием и найдя в нем несколько навыков, которые соответствуют вашим собственным.
Пример: Аналитики данных координируют поддержку всех данных и их функций, выполняют аудит данных и другие услуги для клиентов, они используют статистические инструменты для получения информации из бизнес-данных, которая поддерживает и поощряет ответственное принятие корпоративных решений.
Использование Больших Данных помогает
Читать далее
Какие обязанности возлагаются на аналитиков данных?
Этот вопрос просит потенциальных аналитиков подумать о том, что будет входить в их обязанности в роли аналитика данных. К этому типу вопросов можно подготовиться, внимательно изучив описание вакансии перед собеседованием и найдя в нем несколько навыков, которые соответствуют вашим собственным.
Пример: Аналитики данных координируют поддержку всех данных и их функций, выполняют аудит данных и другие услуги для клиентов, они используют статистические инструменты для получения информации из бизнес-данных, которая поддерживает и поощряет ответственное принятие корпоративных решений.
Использование Больших Данных помогает
Читать далее
👍5
PySpark для аналитика. Как выгружать данные с помощью toPandas и его альтернатив.
Александр Ледовский является тимлид команды аналитики и DS, строит рекламные аукционы в Авито. В работе активно использует Apache Spark. Одна из типовых задач аналитика — посчитать что-то на pySpark, а потом выгрузить это. Например:
Читать далее
Александр Ледовский является тимлид команды аналитики и DS, строит рекламные аукционы в Авито. В работе активно использует Apache Spark. Одна из типовых задач аналитика — посчитать что-то на pySpark, а потом выгрузить это. Например:
Читать далее
👍4
Введение в PySpark
Python считается из основных языков программирования в областях Data Science и Big Data, не удивительно, что Apache Spark предлагает интерфейс и для него. Data Scientist’ы, которые знают Python, могут запросто производить параллельные вычисления PySpark.
Читайте в нашей статье об инициализации Spark-приложения в Python, различии между Pandas и PySpark, доступных форматов для чтения и записи, а также интеграция с базами данных.
Читать
Python считается из основных языков программирования в областях Data Science и Big Data, не удивительно, что Apache Spark предлагает интерфейс и для него. Data Scientist’ы, которые знают Python, могут запросто производить параллельные вычисления PySpark.
Читайте в нашей статье об инициализации Spark-приложения в Python, различии между Pandas и PySpark, доступных форматов для чтения и записи, а также интеграция с базами данных.
Читать
👍3
Pyspark. Анализ больших данных, когда Pandas не достаточно
Pandas - одна из наиболее используемых библиотек Python с открытым исходным кодом для работы со структурированными табличными данными для анализа.
Однако он не поддерживает распределенную обработку, поэтому вам всегда придется увеличивать ресурсы, когда вам понадобится дополнительная мощность для поддержки растущих данных.
И всегда наступит момент, когда ресурсов станет недостаточно. В данной статье мы рассмотрим, как PySpark выручает в условиях нехватки мощностей для обработки данных.
https://habr.com/ru/articles/708468/
Pandas - одна из наиболее используемых библиотек Python с открытым исходным кодом для работы со структурированными табличными данными для анализа.
Однако он не поддерживает распределенную обработку, поэтому вам всегда придется увеличивать ресурсы, когда вам понадобится дополнительная мощность для поддержки растущих данных.
И всегда наступит момент, когда ресурсов станет недостаточно. В данной статье мы рассмотрим, как PySpark выручает в условиях нехватки мощностей для обработки данных.
https://habr.com/ru/articles/708468/
Хабр
Pyspark. Анализ больших данных, когда Pandas не достаточно
Pandas - одна из наиболее используемых библиотек Python с открытым исходным кодом для работы со структурированными табличными данными для анализа. Однако он не поддерживает распределенную обработку,...
👍3👌3
Руководство по PySpark для начинающих
Spark предоставляет API для Scala, Java, Python и R. Система поддерживает повторное использование кода между рабочими задачами, пакетную обработку данных, интерактивные запросы, аналитику в реальном времени, машинное обучение и вычисления на графах. Она использует кэширование в памяти и оптимизированное выполнение запросов к данным любого размера.
У нее нет одной собственной файловой системы, такой как Hadoop Distributed File System (HDFS), вместо этого Spark поддерживает множество популярных файловых систем, таких как HDFS, HBase, Cassandra, Amazon S3, Amazon Redshift, Couchbase и т. д.
https://pythonru.com/biblioteki/pyspark-dlja-nachinajushhih
Spark предоставляет API для Scala, Java, Python и R. Система поддерживает повторное использование кода между рабочими задачами, пакетную обработку данных, интерактивные запросы, аналитику в реальном времени, машинное обучение и вычисления на графах. Она использует кэширование в памяти и оптимизированное выполнение запросов к данным любого размера.
У нее нет одной собственной файловой системы, такой как Hadoop Distributed File System (HDFS), вместо этого Spark поддерживает множество популярных файловых систем, таких как HDFS, HBase, Cassandra, Amazon S3, Amazon Redshift, Couchbase и т. д.
https://pythonru.com/biblioteki/pyspark-dlja-nachinajushhih
PythonRu
Введение в PySpark для начинающих с примерами в Colab
PySpark — это API Apache Spark, который представляет собой систему с открытым исходным кодом, применяемую для распределенной обработки больших данных.
👍5
Книга "Аналитическая культура. От сбора данных до бизнес-результатов"
Подробное пошаговое руководство по внедрению Data-driven-культуры в компании — от сбора данных и наглядных отчетов до анализа и обоснованных решений.
Чтобы стать data-driven-компанией, недостаточно наладить сбор «больших данных» или собрать команду аналитиков. Нужна эффективная культура работы с данными, внедренная на всех уровнях.
Эта практичная книга показывает, какие процессы нужно внедрять повсеместно — от аналитиков и менеджмента до высшего руководства и совета директоров — чтобы создать такую культуру.
Карл Андерсон рассказывает о цепочке аналитической ценности, которая поможет строить предиктивные бизнес-модели — от сбора данных и анализа до идей и конкретных обоснованных действий.
Читать книгу
#книги 📚
Подробное пошаговое руководство по внедрению Data-driven-культуры в компании — от сбора данных и наглядных отчетов до анализа и обоснованных решений.
Чтобы стать data-driven-компанией, недостаточно наладить сбор «больших данных» или собрать команду аналитиков. Нужна эффективная культура работы с данными, внедренная на всех уровнях.
Эта практичная книга показывает, какие процессы нужно внедрять повсеместно — от аналитиков и менеджмента до высшего руководства и совета директоров — чтобы создать такую культуру.
Карл Андерсон рассказывает о цепочке аналитической ценности, которая поможет строить предиктивные бизнес-модели — от сбора данных и анализа до идей и конкретных обоснованных действий.
Читать книгу
#книги 📚
👍6
Нечеткое сравнение строк как метод обнаружения и исправления ошибок
https://vc.ru/newtechaudit/598664-nechetkoe-sravnenie-strok-kak-metod-obnaruzheniya-i-ispravleniya-oshibok
https://vc.ru/newtechaudit/598664-nechetkoe-sravnenie-strok-kak-metod-obnaruzheniya-i-ispravleniya-oshibok
vc.ru
Нечеткое сравнение строк как метод обнаружения и исправления ошибок — NTA на vc.ru
Привет, VC!
👍4👌2
Как создать и удалить таблицы в Apache Hadoop c использованием PySpark
https://vc.ru/newtechaudit/531170-kak-sozdat-i-udalit-tablicy-v-apache-hadoop-c-ispolzovaniem-pyspark
https://vc.ru/newtechaudit/531170-kak-sozdat-i-udalit-tablicy-v-apache-hadoop-c-ispolzovaniem-pyspark
vc.ru
Как создать и удалить таблицы в Apache Hadoop c использованием PySpark — NTA на vc.ru
Сегодня я расскажу, как затратив минимум усилий при работе с большими данными, справиться с задачей создания таблиц с нужными параметрами, а также, как удалить сразу большое количество потерявших актуальность таблиц.
👌5
Как превратить данные в продукт: выжать из данных максимум благодаря принципам продакт-менеджмента
Многие компании хотят, чтобы их технологии были не просто затратами, а конкурентными преимуществами. Это в том числе касается технологий работы с данными. Часто такое стремление выражается словами «Мы хотим воспринимать данные как продукт». Команда VK Cloud перевела статью, которая поможет применить принципы продакт-менеджмента к управлению дата-продуктами компании.
Читать далее
Многие компании хотят, чтобы их технологии были не просто затратами, а конкурентными преимуществами. Это в том числе касается технологий работы с данными. Часто такое стремление выражается словами «Мы хотим воспринимать данные как продукт». Команда VK Cloud перевела статью, которая поможет применить принципы продакт-менеджмента к управлению дата-продуктами компании.
Читать далее
👍5
Анализировать данные — это как варить пиво. Почему дата-анализ и пивоварение — одно и то же с техноизнанки
Читать
Читать
Хабр
Анализировать данные — это как варить пиво. Почему дата-анализ и пивоварение — одно и то же с техноизнанки
Три года я был эстонским пивоваром: придумывал рецепты и сам варил. Когда начал изучать Python, SQL и анализ данных, понял, что между подготовкой данных и подготовкой сусла много общего: оказывается,...
👍5
Как и зачем аналитику проводить UX тесты. Часть первая
https://habr.com/ru/companies/koshelek/articles/734714/
https://habr.com/ru/companies/koshelek/articles/734714/
Хабр
Как и зачем аналитику проводить UX тесты. Часть первая
Привет, Хабр! Меня зовут Настя Московкина, и я работаю руководителем Отдела бизнес и системного анализа в приложении «Кошелёк». Сегодня поговорим о том, как аналитик может повлиять на повышение...
👍5
Разбор: Google Analytics и Яндекс.Метрика для эффективной разметки сайтов
https://habr.com/ru/companies/agima/articles/742802/
https://habr.com/ru/companies/agima/articles/742802/
👍5
Как и зачем аналитику проводить UX тесты. Часть вторая
https://habr.com/ru/companies/koshelek/articles/737392/
https://habr.com/ru/companies/koshelek/articles/737392/
Хабр
Как и зачем аналитику проводить UX тесты. Часть вторая
Привет, Хабр! На связи всё ещё Настя Московкина, руководитель Отдела анализа в приложении «Кошелёк». В предыдущей статье мы по косточкам разобрали процесс подготовки к UX тестированию своими силами, а...
👍4🔥1
Книга «Python для data science»
Книга предназначена для разработчиков, желающим лучше понять возможности Python по обработке и анализу данных. Возможно, вы работаете в компании, которая хочет использовать данные для улучшения бизнес-процессов, принятия более обоснованных решений и привлечения большего количества покупателей.
Или, может быть, вы хотите создать собственное приложение на основе данных или просто расширить знания о применении Python в области data science.
Читать далее
Книга предназначена для разработчиков, желающим лучше понять возможности Python по обработке и анализу данных. Возможно, вы работаете в компании, которая хочет использовать данные для улучшения бизнес-процессов, принятия более обоснованных решений и привлечения большего количества покупателей.
Или, может быть, вы хотите создать собственное приложение на основе данных или просто расширить знания о применении Python в области data science.
Читать далее
🔥5
Dagster и Great Expectations: Интеграция без боли
Great Expectations позволяет определить так называемые ожидания от ваших данных, то есть задать правила и условия, которым данные должны соответствовать.
Dagster, с другой стороны, это платформа с открытым исходным кодом для управления данными, которая позволяет создавать, тестировать и развертывать пайплайны данных. Написан на python, что позволяет пользователям гибко настраивать и расширять его функциональность.
https://habr.com/ru/articles/746874/
Great Expectations позволяет определить так называемые ожидания от ваших данных, то есть задать правила и условия, которым данные должны соответствовать.
Dagster, с другой стороны, это платформа с открытым исходным кодом для управления данными, которая позволяет создавать, тестировать и развертывать пайплайны данных. Написан на python, что позволяет пользователям гибко настраивать и расширять его функциональность.
https://habr.com/ru/articles/746874/
Хабр
Dagster и Great Expectations: Интеграция без боли
Меня зовут Артем Шнайдер, и я занимаюсь DataScience в Бланке. Сегодня я хочу рассказать вам о том, как можно интегрировать два мощных инструмента – Dagster и Great Expectations . Great Expectations...
🔥3