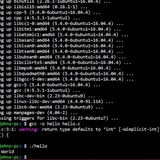
Custom bash prompt turned into launcher
I initially put this as a reply to a previous thread but it did not go where I wanted, so here it is instead for what it is worth.
I currently have about 800 aliases in 35 bashrc-xxx files pointing to various folders, noscripts and programs.
Gdrive link: https://drive.google.com/drive/folders/1hTfNvUvI9zRla9nB6WhEyQa2EmGfd\_ol?usp=drive\_link
My goal is to have a generic launcher that will work on any linux distro using bash. Just double click on an alias to copy then paste and enter.
I like the ability to view many aliases without scrolling.
Vektor
https://redd.it/1e4ovv1
@r_bash
I initially put this as a reply to a previous thread but it did not go where I wanted, so here it is instead for what it is worth.
I currently have about 800 aliases in 35 bashrc-xxx files pointing to various folders, noscripts and programs.
Gdrive link: https://drive.google.com/drive/folders/1hTfNvUvI9zRla9nB6WhEyQa2EmGfd\_ol?usp=drive\_link
My goal is to have a generic launcher that will work on any linux distro using bash. Just double click on an alias to copy then paste and enter.
I like the ability to view many aliases without scrolling.
Vektor
https://redd.it/1e4ovv1
@r_bash
Bash completion for a "passthrough" Git command?
I have a simple git extension that I use to set the global gitconfig at execution time. It has a few subcommands of its own, but the main use case is for commands that take the form
```
git profile PROFILE_NAME [git-command] [git-command-args]
```
This particular execution path is really just an alias for
```
GIT_CONFIG_GLOBAL=/path/to/PROFILE-NAME/config git PROFILE_NAME [git-command] [git-command-args]
```
Easy enough.
The hard part is Bash completion. If "$2" is a profile name, then the remaining args should simply be forwarded on to Git. I'm using the completions provided by the Git project (cf. [here](https://github.com/git/git/blob/5dd5007f8936f8d37cf95119e83039bd9237a3c5/contrib/completion/git-completion.bash)), and I don't fully grok the code therein but my understanding is that the entry point to wrap the Git command itself from within another completion routing (i.e., not just calling `complete`) is `__git_func_wrap __git_main`.
Hence my intended approach would be something like this. (Note: I'm aware that this completion currently only supports invocations of the form `git <plugin-name>` syntax, not the single-word `git-<plugin-name>`. Not bugged for the moment.)
_git_profile() {
local -r cur="${COMP_WORDS[COMP_CWORD]}"
local -ar profiles=("$(___git_profile_get_profiles "$cur")")
local -ar subcmds=("$(___git_profile_get_subcmds "$cur")")
local -ar word_opts=("${profiles[@]}" "${subcmds[@]}")
case $COMP_CWORD in
1) ;;
2)
__gitcomp "${word_opts[*]}"
;;
*)
local profile_arg=${COMP_WORDS[2]}
# Has the user specified a subcommand supported directly by this plugin?
# All our subcommands currently don't accept args, so bail out here
if ! _git_profile_arg_in "$profile_arg" "${subcmds[@]}"; then
return
fi
# Have they instead specified a config profile?
if ! _git_profile_arg_in "$profile_arg" "${profiles[@]}"; then
return
fi
local -r profile="$profile_arg"
local -r cmd_suffix="-profile"
COMP_WORDS=('git' "${COMP_WORDS[@]:3}")
COMP_LINE="${COMP_WORDS[*]}"
COMP_CWORD=$((COMP_CWORD - 2))
COMP_POINT=$((COMP_POINT - ${#profile} - ${#cmd_suffix} - 1)) # -1 for the space between $1 and $2
GIT_CONFIG_GLOBAL="${GIT_PROFILE_CONFIG_HOME:-${HOME}/.config/git/profiles%/}/${profile}" \
__git_func_wrap __git_main
;;
esac
}
Tl;dr:
* Grab the one arg we care about.
* If it's a subcommand of my noscript, nothing left to do.
* If it's not a known config profile, nothing left to do.
* If it *is* a known profile, then rebuild the command line to be parsed by Git completion such that it reads `git [git-command] [git-command-args]` from Git's point of view (with the caveat that it will use the specified custom config for any commands that read from or write to global config).
When I enter `git` into a terminal and press <TAB> twice, with this completion included in `$HOME/.local/share/bash-completions/`:
* `profile` is populated as a Git subcommand and can be autocompleted from partial segments (e.g., `git p`)
When I enter `git profile` and press <TAB> twice:
* all subcommands supported by the noscript and config profile directories are listed and can be autocompleted from partial segments (e.g., `git a` + <TAB> twice offers the 'add' command and the 'aaaaa' profile as completion options)
When I enter `git profile aaaaa`, where `aaaaa` is a Git config profile and press <TAB> twice:
* a long list of what appear to be all known Git commands is listed (including `profile`, but I'll solve that another day)
* when subsequently typing any character, whether or not it is the first letter of any known Git commands, and then pressing <TAB> twice, no completion options are offered
* This includes hypens, so I don't get completion for any top-level options
This is where the problem arises. I've found an entry point to expose available Git commands, but
I have a simple git extension that I use to set the global gitconfig at execution time. It has a few subcommands of its own, but the main use case is for commands that take the form
```
git profile PROFILE_NAME [git-command] [git-command-args]
```
This particular execution path is really just an alias for
```
GIT_CONFIG_GLOBAL=/path/to/PROFILE-NAME/config git PROFILE_NAME [git-command] [git-command-args]
```
Easy enough.
The hard part is Bash completion. If "$2" is a profile name, then the remaining args should simply be forwarded on to Git. I'm using the completions provided by the Git project (cf. [here](https://github.com/git/git/blob/5dd5007f8936f8d37cf95119e83039bd9237a3c5/contrib/completion/git-completion.bash)), and I don't fully grok the code therein but my understanding is that the entry point to wrap the Git command itself from within another completion routing (i.e., not just calling `complete`) is `__git_func_wrap __git_main`.
Hence my intended approach would be something like this. (Note: I'm aware that this completion currently only supports invocations of the form `git <plugin-name>` syntax, not the single-word `git-<plugin-name>`. Not bugged for the moment.)
_git_profile() {
local -r cur="${COMP_WORDS[COMP_CWORD]}"
local -ar profiles=("$(___git_profile_get_profiles "$cur")")
local -ar subcmds=("$(___git_profile_get_subcmds "$cur")")
local -ar word_opts=("${profiles[@]}" "${subcmds[@]}")
case $COMP_CWORD in
1) ;;
2)
__gitcomp "${word_opts[*]}"
;;
*)
local profile_arg=${COMP_WORDS[2]}
# Has the user specified a subcommand supported directly by this plugin?
# All our subcommands currently don't accept args, so bail out here
if ! _git_profile_arg_in "$profile_arg" "${subcmds[@]}"; then
return
fi
# Have they instead specified a config profile?
if ! _git_profile_arg_in "$profile_arg" "${profiles[@]}"; then
return
fi
local -r profile="$profile_arg"
local -r cmd_suffix="-profile"
COMP_WORDS=('git' "${COMP_WORDS[@]:3}")
COMP_LINE="${COMP_WORDS[*]}"
COMP_CWORD=$((COMP_CWORD - 2))
COMP_POINT=$((COMP_POINT - ${#profile} - ${#cmd_suffix} - 1)) # -1 for the space between $1 and $2
GIT_CONFIG_GLOBAL="${GIT_PROFILE_CONFIG_HOME:-${HOME}/.config/git/profiles%/}/${profile}" \
__git_func_wrap __git_main
;;
esac
}
Tl;dr:
* Grab the one arg we care about.
* If it's a subcommand of my noscript, nothing left to do.
* If it's not a known config profile, nothing left to do.
* If it *is* a known profile, then rebuild the command line to be parsed by Git completion such that it reads `git [git-command] [git-command-args]` from Git's point of view (with the caveat that it will use the specified custom config for any commands that read from or write to global config).
When I enter `git` into a terminal and press <TAB> twice, with this completion included in `$HOME/.local/share/bash-completions/`:
* `profile` is populated as a Git subcommand and can be autocompleted from partial segments (e.g., `git p`)
When I enter `git profile` and press <TAB> twice:
* all subcommands supported by the noscript and config profile directories are listed and can be autocompleted from partial segments (e.g., `git a` + <TAB> twice offers the 'add' command and the 'aaaaa' profile as completion options)
When I enter `git profile aaaaa`, where `aaaaa` is a Git config profile and press <TAB> twice:
* a long list of what appear to be all known Git commands is listed (including `profile`, but I'll solve that another day)
* when subsequently typing any character, whether or not it is the first letter of any known Git commands, and then pressing <TAB> twice, no completion options are offered
* This includes hypens, so I don't get completion for any top-level options
This is where the problem arises. I've found an entry point to expose available Git commands, but
GitHub
git/contrib/completion/git-completion.bash at 5dd5007f8936f8d37cf95119e83039bd9237a3c5 · git/git
Git Source Code Mirror - This is a publish-only repository but pull requests can be turned into patches to the mailing list via GitGitGadget (https://gitgitgadget.github.io/). Please follow Documen...
either there are subsequent steps required to expose additional completions and support partial command words via the `__git_func_wrap` approach, or `__git_func_wrap` is the wrong entry point.
I've experimented with a few additional functions, such as `__gitcomp` inside of the function`, and using __gitcomplete` and the triple-underscored `___gitcomplete` as invocations in the completion noscript (outside of the function). To use `__gitcomp` correctly seems to entail that I'd have to simply reimplement support for most or all Git commands, and as I understand it, nothing like `__gitcomplete` should need to be invoked for a noscript named according to the `git-cmd` syntax. Basically, I'm un-systematically trying functions that look like they address the use case, because I'm not totally clear *what* the correct approach is here.
Any insight anyone can offer is appreciated. Not looking for a comprehensive solution, just a nudge in the right direction, including a better TFM than the completion code itself is possible. (Fwiw, I'm familiar with the general Bash completion docs.)
https://redd.it/1e4r2k5
@r_bash
I've experimented with a few additional functions, such as `__gitcomp` inside of the function`, and using __gitcomplete` and the triple-underscored `___gitcomplete` as invocations in the completion noscript (outside of the function). To use `__gitcomp` correctly seems to entail that I'd have to simply reimplement support for most or all Git commands, and as I understand it, nothing like `__gitcomplete` should need to be invoked for a noscript named according to the `git-cmd` syntax. Basically, I'm un-systematically trying functions that look like they address the use case, because I'm not totally clear *what* the correct approach is here.
Any insight anyone can offer is appreciated. Not looking for a comprehensive solution, just a nudge in the right direction, including a better TFM than the completion code itself is possible. (Fwiw, I'm familiar with the general Bash completion docs.)
https://redd.it/1e4r2k5
@r_bash
Reddit
From the bash community on Reddit: Bash completion for a "passthrough" Git command?
Explore this post and more from the bash community
Stuck trying to get a find cmd to echo No File Found when a file is not found
for SOURCE in "${SOURCES@}"; do
## Set file path
FILEPATH="${ORIGIN}/${SOURCE}/EIB/"
echo " "
echo "Searching for ${SOURCE} file..."
echo " "
FILESFOUND=()
find "${FILEPATH}" -type f -print0 | while IFS= read -r -d '' file; do
FILESFOUND+=("$file")
FILENAME=$(basename "$file")
echo "THIS WOULD BE WHERE THE SCRIPT CP FILE"
done
if ${#FILES_FOUND[@} -eq 0 ]; then
echo "No File Found in ${FILEPATH}"
continue
if
done
I have tried a couple ways to do this, setting FILES\FOUND to false and then true inside the while loop, using the array(seen in the code above), moving the if statement inside the while loop. The latter didn't out out No File Found when a file was found, the other ways put No File Found when a file was found.
Since the while loop is creating a subshell, the variable that is being set outside it I don't think is being updated correctly
https://redd.it/1e4t4vm
@r_bash
for SOURCE in "${SOURCES@}"; do
## Set file path
FILEPATH="${ORIGIN}/${SOURCE}/EIB/"
echo " "
echo "Searching for ${SOURCE} file..."
echo " "
FILESFOUND=()
find "${FILEPATH}" -type f -print0 | while IFS= read -r -d '' file; do
FILESFOUND+=("$file")
FILENAME=$(basename "$file")
echo "THIS WOULD BE WHERE THE SCRIPT CP FILE"
done
if ${#FILES_FOUND[@} -eq 0 ]; then
echo "No File Found in ${FILEPATH}"
continue
if
done
I have tried a couple ways to do this, setting FILES\FOUND to false and then true inside the while loop, using the array(seen in the code above), moving the if statement inside the while loop. The latter didn't out out No File Found when a file was found, the other ways put No File Found when a file was found.
Since the while loop is creating a subshell, the variable that is being set outside it I don't think is being updated correctly
https://redd.it/1e4t4vm
@r_bash
Reddit
From the bash community on Reddit
Explore this post and more from the bash community
looking for a bash configuration
Hi guys does anyone have any good bash configurations or recommendations that I could implement on my Ubuntu 24.04 machine? Any help or advice appreciated
https://redd.it/1e5ddvr
@r_bash
Hi guys does anyone have any good bash configurations or recommendations that I could implement on my Ubuntu 24.04 machine? Any help or advice appreciated
https://redd.it/1e5ddvr
@r_bash
Reddit
From the bash community on Reddit
Explore this post and more from the bash community
HTTP request in coreVM
Anyone know what coreVM is? I hope so because I'm doing a cybersecurity midterm in college and I've been stuck on this question for 2 days:
Use one PC of the first network as a webserver and make an HTTP request from another PC of the second network to this webserver. Get a Wireshark capture of the overall HTTP interaction and explain this thoroughly. (15%)
Is there a command in /bin/sh and bash I can use to make an HTTP request? Thank you.
https://redd.it/1e5emh4
@r_bash
Anyone know what coreVM is? I hope so because I'm doing a cybersecurity midterm in college and I've been stuck on this question for 2 days:
Use one PC of the first network as a webserver and make an HTTP request from another PC of the second network to this webserver. Get a Wireshark capture of the overall HTTP interaction and explain this thoroughly. (15%)
Is there a command in /bin/sh and bash I can use to make an HTTP request? Thank you.
https://redd.it/1e5emh4
@r_bash
Reddit
From the bash community on Reddit
Explore this post and more from the bash community
Can someone check this noscript is it safe to run,
HELLO, I am new to linux currently using MXLinux which is debian basied,, i tell chatgpt to write noscript that remove unused linux kernals and headers. Please review if it is safe to run.
#!/bin/bash
# Get the latest kernel version
latest_version=$(uname -r)
# List all installed kernels and headers
kernel_list=$(dpkg -l | grep linux-image | awk '{print $2}')
headers_list=$(dpkg -l | grep linux-headers | awk '{print $2}')
# Iterate over the kernel list, remove all but the latest version
for kernel in $kernel_list; do
if [ $kernel != "linux-image-${latest_version}" \]; then
sudo apt-get purge -y $kernel
fi
done
# Iterate over the headers list, remove all but the latest version
for headers in $headers_list; do
if [ $headers != "linux-headers-${latest_version}" \]; then
sudo apt-get purge -y $headers
fi
done
# Update grub
sudo update-grub
https://redd.it/1e5g8mu
@r_bash
HELLO, I am new to linux currently using MXLinux which is debian basied,, i tell chatgpt to write noscript that remove unused linux kernals and headers. Please review if it is safe to run.
#!/bin/bash
# Get the latest kernel version
latest_version=$(uname -r)
# List all installed kernels and headers
kernel_list=$(dpkg -l | grep linux-image | awk '{print $2}')
headers_list=$(dpkg -l | grep linux-headers | awk '{print $2}')
# Iterate over the kernel list, remove all but the latest version
for kernel in $kernel_list; do
if [ $kernel != "linux-image-${latest_version}" \]; then
sudo apt-get purge -y $kernel
fi
done
# Iterate over the headers list, remove all but the latest version
for headers in $headers_list; do
if [ $headers != "linux-headers-${latest_version}" \]; then
sudo apt-get purge -y $headers
fi
done
# Update grub
sudo update-grub
https://redd.it/1e5g8mu
@r_bash
Reddit
From the bash community on Reddit
Explore this post and more from the bash community
Bash Question
Hii,
Good afternoon, would there be a more efficient or optimal way to do the following?
#!/usr/bin/env bash
foo(){
local FULLPATH="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin"
local _path=""
local -A _fullPath=()
while IFS="" read -d ":" _path ; do
_fullPath[$_path]=""
done <<< ${FULLPATH}:
while IFS="" read -d ":" _path ; do
[[ -v _fullPath[$_path] ]] || _fullPath[$_path]=""
done <<< ${PATH}:
declare -p _fullPath
}
foo
I would like you to tell me if you see something unnecessary or what you would do differently, both logically and syntactically.
I think for example that it does not make much sense to declare a variable and then pass it to an array through a loop, it would be better to directly put the contents of the variable `FULLPATH` as elements in the array `_fullPath`, no?
The truth is that the objective of this is simply that when the noscript is executed, it adds to the user's PATH, the paths that already had the `PATH` variable in addition to those that are present as value in the `FULLPATH` variable.
I do this because I have a noscript that I want to run from the crontab of a user but I realized that it gives error because the `PATH` variable from crontab is very short and does not understand the paths where the binaries used in the noscript are located.
Possibly there is another way to do it simpler, simpler or optimal, if you are so kind I would like you to give me your ideas and also if there is a better way to do the above, I have seen that the default behavior of read is to read up to a line break, then I could not use `IFS` and I had to use `-d “:”` for the delimiter to be a colon, I do not know if you could do that differently.
I have also opted to use an associative array instead of doing:
IFS=“:” read -ra _fullPath <<< $PATH
Then I could use `[[ -v ... ]]` to check if the array keys are defined instead of making a nested loop to check the existence of the elements of an array in another one, I don't know if this would be more efficient or not.
Thanks in advance 😊
https://redd.it/1e5koxt
@r_bash
Hii,
Good afternoon, would there be a more efficient or optimal way to do the following?
#!/usr/bin/env bash
foo(){
local FULLPATH="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin"
local _path=""
local -A _fullPath=()
while IFS="" read -d ":" _path ; do
_fullPath[$_path]=""
done <<< ${FULLPATH}:
while IFS="" read -d ":" _path ; do
[[ -v _fullPath[$_path] ]] || _fullPath[$_path]=""
done <<< ${PATH}:
declare -p _fullPath
}
foo
I would like you to tell me if you see something unnecessary or what you would do differently, both logically and syntactically.
I think for example that it does not make much sense to declare a variable and then pass it to an array through a loop, it would be better to directly put the contents of the variable `FULLPATH` as elements in the array `_fullPath`, no?
The truth is that the objective of this is simply that when the noscript is executed, it adds to the user's PATH, the paths that already had the `PATH` variable in addition to those that are present as value in the `FULLPATH` variable.
I do this because I have a noscript that I want to run from the crontab of a user but I realized that it gives error because the `PATH` variable from crontab is very short and does not understand the paths where the binaries used in the noscript are located.
Possibly there is another way to do it simpler, simpler or optimal, if you are so kind I would like you to give me your ideas and also if there is a better way to do the above, I have seen that the default behavior of read is to read up to a line break, then I could not use `IFS` and I had to use `-d “:”` for the delimiter to be a colon, I do not know if you could do that differently.
I have also opted to use an associative array instead of doing:
IFS=“:” read -ra _fullPath <<< $PATH
Then I could use `[[ -v ... ]]` to check if the array keys are defined instead of making a nested loop to check the existence of the elements of an array in another one, I don't know if this would be more efficient or not.
Thanks in advance 😊
https://redd.it/1e5koxt
@r_bash
Reddit
From the bash community on Reddit
Explore this post and more from the bash community
Django API not auto-starting
I'm finalizing a Django API deployment on AWS EC2, and using this noscript to start the app:
The problem is the API isn't auto-starting. As far as I can tell everything's installed correctly. I'm able to connect to the EC2 instance terminal, and enter the following commands manually, and the API is accessible:
As soon as I close the AWS EC2 terminal connection, the API is no longer accessible. I thought
How can I set this up so the API is accessible after I disconnect from the EC2 instance terminal?
https://redd.it/1e5yxzp
@r_bash
I'm finalizing a Django API deployment on AWS EC2, and using this noscript to start the app:
#!/usr/bin/env bash
set -e
PROJECT_MAIN_DIR_NAME="SBY-backend"
# Validate variables
if [ -z "$PROJECT_MAIN_DIR_NAME" ]; then
echo "Error: PROJECT_MAIN_DIR_NAME is not set. Please set it to your project directory name." >&2
exit 1
fi
# Change ownership to ubuntu user
sudo chown -R ubuntu:ubuntu "/home/ubuntu/$PROJECT_MAIN_DIR_NAME"
# Change directory to the project main directory
cd "/home/ubuntu/$PROJECT_MAIN_DIR_NAME"
# Activate virtual environment
source "/home/ubuntu/$PROJECT_MAIN_DIR_NAME/venv/bin/activate"
# Restart Gunicorn and Nginx services
sudo service gunicorn restart
sudo service nginx restart
# Start API
cd $PROJECT_MAIN_DIR_NAME/
python3 manage.py runserver 0.0.0.0:8000
The problem is the API isn't auto-starting. As far as I can tell everything's installed correctly. I'm able to connect to the EC2 instance terminal, and enter the following commands manually, and the API is accessible:
~$ source /home/ubuntu/SBY-backend/venv/bin/activate
~$ cd SBY-backend/
~/SBY-backend$ python3 manage.py runserver 0.0.0.0:8000
As soon as I close the AWS EC2 terminal connection, the API is no longer accessible. I thought
nginx was supposed to help keep the server running.How can I set this up so the API is accessible after I disconnect from the EC2 instance terminal?
https://redd.it/1e5yxzp
@r_bash
Reddit
From the bash community on Reddit
Explore this post and more from the bash community
Asciiquarium with planets
Hey yall! Was thinking of making a "planetarium" for the CLI, something along the lines of asciiquarium but, yk, planets and orbits. Idk if asciiquarium is the right thing to compare to, as it basically will be a sorta randomly generated solar system, but it's what gave me the idea. Does something like this already exist, and if so, what's it called? (Except from globe, ik that one)
https://redd.it/1e6f2nm
@r_bash
Hey yall! Was thinking of making a "planetarium" for the CLI, something along the lines of asciiquarium but, yk, planets and orbits. Idk if asciiquarium is the right thing to compare to, as it basically will be a sorta randomly generated solar system, but it's what gave me the idea. Does something like this already exist, and if so, what's it called? (Except from globe, ik that one)
https://redd.it/1e6f2nm
@r_bash
Reddit
From the bash community on Reddit
Explore this post and more from the bash community
Why can my command embedded in a noscript only able to be executed when typed in the terminal?
Cross posting from ask ubuntu
I wrote a noscript to get sequences corresponding to some id's.
# Process each genome ID in array
for id in "${genome_ids[@]}"; do
echo "Processing genome ID: $id"
# Construct the command
command="p3-genome-fasta --protein $id"
# Execute the command
$command
Example output: Processing genome ID: 1000289.10 p3-genome-fasta --protein 1000289.10 . at /usr/share/bvbrc-cli/deployment/plbin/p3-genome-fasta.pl line 47.
It says there's an error, but when I copy and paste the command printed to the screen, it works?
Related code from p3-genome-fasta.pl
# Get the genome ID.
my ($genomeID) = @ARGV;
if (! $genomeID) {
die "No genome ID specified.";
} elsif (! ($genomeID =~ /^\d+\.\d+$/)) {
die "Invalid genome ID $genomeID."; <<<<< line 47
}
https://redd.it/1e6kmmr
@r_bash
Cross posting from ask ubuntu
I wrote a noscript to get sequences corresponding to some id's.
# Process each genome ID in array
for id in "${genome_ids[@]}"; do
echo "Processing genome ID: $id"
# Construct the command
command="p3-genome-fasta --protein $id"
# Execute the command
$command
Example output: Processing genome ID: 1000289.10 p3-genome-fasta --protein 1000289.10 . at /usr/share/bvbrc-cli/deployment/plbin/p3-genome-fasta.pl line 47.
It says there's an error, but when I copy and paste the command printed to the screen, it works?
Related code from p3-genome-fasta.pl
# Get the genome ID.
my ($genomeID) = @ARGV;
if (! $genomeID) {
die "No genome ID specified.";
} elsif (! ($genomeID =~ /^\d+\.\d+$/)) {
die "Invalid genome ID $genomeID."; <<<<< line 47
}
https://redd.it/1e6kmmr
@r_bash
Reddit
From the bash community on Reddit
Explore this post and more from the bash community
ffmpeg make video from image sequence with decreasing speed
Is there an option to do this?
I took screenshots, each one moved further to the left than the previous one by 10 px. For now I have managed to generate an animated gif, but I would like to make a video in which the speed decreases
https://redd.it/1e77ho2
@r_bash
Is there an option to do this?
I took screenshots, each one moved further to the left than the previous one by 10 px. For now I have managed to generate an animated gif, but I would like to make a video in which the speed decreases
https://redd.it/1e77ho2
@r_bash
Reddit
From the bash community on Reddit
Explore this post and more from the bash community
grep command guidance
Not sure if this is the best place for this but here goes:
I'm trying to build an implementation of grep by following that codecrafters (step by step project building guide, for those who don't know) thing and the current step is having to implement the `+` pattern, which is supposed to match a certain thing one or more time.
I went through the man page for grep and this is all that's written there too, that it matches the previous pattern one or more times.
Here's what I'm curious about. Does this pattern take into account the next normal pattern? For ex, if my pattern is "\\w+abc", would it match on the input "xyzabc" (under my reasoning, \\w+ carries on until it keeps matching, but the + pattern stops matching in case the next pattern also matches (the next pattern here being the literal "a"). Am I right, or does \\w+ consume all alphanumeric characters?
https://redd.it/1e78yi9
@r_bash
Not sure if this is the best place for this but here goes:
I'm trying to build an implementation of grep by following that codecrafters (step by step project building guide, for those who don't know) thing and the current step is having to implement the `+` pattern, which is supposed to match a certain thing one or more time.
I went through the man page for grep and this is all that's written there too, that it matches the previous pattern one or more times.
Here's what I'm curious about. Does this pattern take into account the next normal pattern? For ex, if my pattern is "\\w+abc", would it match on the input "xyzabc" (under my reasoning, \\w+ carries on until it keeps matching, but the + pattern stops matching in case the next pattern also matches (the next pattern here being the literal "a"). Am I right, or does \\w+ consume all alphanumeric characters?
https://redd.it/1e78yi9
@r_bash
Reddit
From the bash community on Reddit
Explore this post and more from the bash community
Question on using <su -c>, I’m missing something here on how the command is getting interpreted.
When I run the following command (logged in as root) I am presented with a “-sh: ./app: Permission denied”.
su -c “./app” - foo
However, when I specify additional instructions here it works.
su -c “cd /home/foo && ./app” - foo
If im already in the directory why wouldn’t the above command work? Is the su executing this command from a different location than where im currently sitting in?
https://redd.it/1e79cfd
@r_bash
When I run the following command (logged in as root) I am presented with a “-sh: ./app: Permission denied”.
su -c “./app” - foo
However, when I specify additional instructions here it works.
su -c “cd /home/foo && ./app” - foo
If im already in the directory why wouldn’t the above command work? Is the su executing this command from a different location than where im currently sitting in?
https://redd.it/1e79cfd
@r_bash
Reddit
From the bash community on Reddit
Explore this post and more from the bash community
Bash/Freecodecamp
#!/bin/bash
# Program to tell a persons fortune
echo -e "\n~~ Fortune Teller ~~\n"
RESPONSES=("Yes" "No" "Maybe" "Outlook good" "Don't count on it" "Ask again later")
N=$(( RANDOM % 6 ))
function GET_FORTUNE() {
if [[ ! $1 ]]
then
echo Ask a yes or no question:
else
echo Try again. Make sure it ends with a question mark:
fi
read QUESTION
}
GET_FORTUNE
until [[ $QUESTION =~ \?$ ]]
do
GET_FORTUNE again
done
echo -e "\n$RESPONSES[$N]"
Hi I am go through this pj in Freecodecamp and cannot understand what it means here:
If [[ ! $1 ]]
Does ! mean negation and $1 mean 1st argument? But if I dont pass any argument then the coding still run out the same result. Can anyone explain?
https://redd.it/1e7mw69
@r_bash
#!/bin/bash
# Program to tell a persons fortune
echo -e "\n~~ Fortune Teller ~~\n"
RESPONSES=("Yes" "No" "Maybe" "Outlook good" "Don't count on it" "Ask again later")
N=$(( RANDOM % 6 ))
function GET_FORTUNE() {
if [[ ! $1 ]]
then
echo Ask a yes or no question:
else
echo Try again. Make sure it ends with a question mark:
fi
read QUESTION
}
GET_FORTUNE
until [[ $QUESTION =~ \?$ ]]
do
GET_FORTUNE again
done
echo -e "\n$RESPONSES[$N]"
Hi I am go through this pj in Freecodecamp and cannot understand what it means here:
If [[ ! $1 ]]
Does ! mean negation and $1 mean 1st argument? But if I dont pass any argument then the coding still run out the same result. Can anyone explain?
https://redd.it/1e7mw69
@r_bash
Reddit
From the bash community on Reddit
Explore this post and more from the bash community
Bash syntax
Hi does anyone can explain what this condition means?
If [ ! $1 ]
Thanks
https://redd.it/1e7n73w
@r_bash
Hi does anyone can explain what this condition means?
If [ ! $1 ]
Thanks
https://redd.it/1e7n73w
@r_bash
Reddit
From the bash community on Reddit
Explore this post and more from the bash community
Advanced Terminal Tips and Tricks
https://www.bitsand.cloud/posts/terminal-tips/
https://redd.it/1e7qaks
@r_bash
https://www.bitsand.cloud/posts/terminal-tips/
https://redd.it/1e7qaks
@r_bash
Working on a bash completion library, including a function to delete a compword from the scope-local command line. What edge cases am I missing?
Title of post.
A common pattern for me lately is to extend existing commands like `pass` and `git`, both of which have functionality to pick up extension command executables by naming convention and run their respective completion routines. My use case is a bit unique in that many of my extensions accept their own args and then pass through to other existing subcommands of the wrapped command. E.g., I'm currently working on updating my [pw](https://github.com/marcxjo/pw) noscript to run according to the following syntax:
pass store ssh github.com/me
`pw` is just a wrapper that sets the `PASSWORD_STORE_DIR` envar to allow completion of an alternative password store. Hence `pw` and `pass store` are completely equivalent, and either provide passthrough to existing `pass` commands.
To facilitate this and other noscripts I've written, I'm working on a small extension library for `bash-completion` to handle my specific use cases, the foundation of which is a function to enable removing a compword from the compline*. The idea is that, in order to handle `pass` completion in the scenario above, since `pass` has no knowledge of the `store` keyword or its arg, in order to handle passthrough to `pass` I'd forward a compline that simply does not contain these words.
At least in my head, the algorithm is simple: to remove a single word `$n` from `COMP_*`:
COMP_WORD=( "${COMP_WORD[@]:0:n}" "${COMP_WORD[@]:n+1}")
COMP_LINE="${COMP_WORD[*]}"
COMP_CWORD=$((COMP_CWORD - 1))
COMP_POINT=$((COMP_POINT - ${whitespace_before_argn} - ${#n} - ${whitespace_after_argn} + 1))
Note that the intent in `COMP_POINT` would be to collapse all extraneous spaces flanking the deleted `$n` to a single whitespace. I feel like they're may be an edge case I'm missing in doing so, but not totally sure. What, if anything, am I missing to ensure that this works as intended in the general case? What weird behaviors or surprising inputs does this algorithm fail to consider? As always, any and all insight is appreciated.
\* Really, a local copy of the compline, but that's neither here nor there
https://redd.it/1e7xlis
@r_bash
Title of post.
A common pattern for me lately is to extend existing commands like `pass` and `git`, both of which have functionality to pick up extension command executables by naming convention and run their respective completion routines. My use case is a bit unique in that many of my extensions accept their own args and then pass through to other existing subcommands of the wrapped command. E.g., I'm currently working on updating my [pw](https://github.com/marcxjo/pw) noscript to run according to the following syntax:
pass store ssh github.com/me
`pw` is just a wrapper that sets the `PASSWORD_STORE_DIR` envar to allow completion of an alternative password store. Hence `pw` and `pass store` are completely equivalent, and either provide passthrough to existing `pass` commands.
To facilitate this and other noscripts I've written, I'm working on a small extension library for `bash-completion` to handle my specific use cases, the foundation of which is a function to enable removing a compword from the compline*. The idea is that, in order to handle `pass` completion in the scenario above, since `pass` has no knowledge of the `store` keyword or its arg, in order to handle passthrough to `pass` I'd forward a compline that simply does not contain these words.
At least in my head, the algorithm is simple: to remove a single word `$n` from `COMP_*`:
COMP_WORD=( "${COMP_WORD[@]:0:n}" "${COMP_WORD[@]:n+1}")
COMP_LINE="${COMP_WORD[*]}"
COMP_CWORD=$((COMP_CWORD - 1))
COMP_POINT=$((COMP_POINT - ${whitespace_before_argn} - ${#n} - ${whitespace_after_argn} + 1))
Note that the intent in `COMP_POINT` would be to collapse all extraneous spaces flanking the deleted `$n` to a single whitespace. I feel like they're may be an edge case I'm missing in doing so, but not totally sure. What, if anything, am I missing to ensure that this works as intended in the general case? What weird behaviors or surprising inputs does this algorithm fail to consider? As always, any and all insight is appreciated.
\* Really, a local copy of the compline, but that's neither here nor there
https://redd.it/1e7xlis
@r_bash
GitHub
GitHub - marcxjo/pw: GNU Password Store Wrapper for Easy Multi-Store Handling
GNU Password Store Wrapper for Easy Multi-Store Handling - marcxjo/pw
Setting Up RAID with Caching on Ubuntu
### Purpose
I came up with this noscript which I then modified to be more universal so more people could use it without having to change a ton of stuff (unless you are not on Ubuntu then you might have to).
### Script execution
- Updates package lists and installs necessary packages (
- Rescans SCSI and NVMe buses.
- Partitions the specified disks.
- Creates a RAID array with the specified RAID type and disks.
- Initializes the RAID array as a cache device.
- Attaches the cache to the main RAID array.
- Creates an ext4 filesystem on the cached RAID array.
- Mounts the RAID array and updates
- Provides detailed feedback and error handling throughout the process.
#### User Variables
-
-
-
-
#### Usage Instructions
1. Set the RAID Types and Disks: Open the noscript and set the
2. Save the Script: Save the noscript to a file, for example,
3. Make the Script Executable:
4. View Help Menu: Run the noscript with the
5. Run the Script as Root or with
#### Example Configuration
### Sourcing the noscript
You can get the noscript on GitHub here
https://redd.it/1e84grh
@r_bash
### Purpose
I came up with this noscript which I then modified to be more universal so more people could use it without having to change a ton of stuff (unless you are not on Ubuntu then you might have to).
### Script execution
- Updates package lists and installs necessary packages (
mdadm, lvm2, bcache-tools, nvme-cli).- Rescans SCSI and NVMe buses.
- Partitions the specified disks.
- Creates a RAID array with the specified RAID type and disks.
- Initializes the RAID array as a cache device.
- Attaches the cache to the main RAID array.
- Creates an ext4 filesystem on the cached RAID array.
- Mounts the RAID array and updates
/etc/fstab to ensure it mounts at boot.- Provides detailed feedback and error handling throughout the process.
#### User Variables
-
MAIN_RAID_TYPE : RAID type for the main RAID array (e.g., 10).-
CACHE_RAID_TYPE : RAID type for the caching RAID array (e.g., 0).-
MAIN_RAID_DISKS : Array of disks for the main RAID array (e.g., /dev/sdc /dev/sdd /dev/sde /dev/sdf).-
CACHE_RAID_DISKS : Array of disks for the caching RAID array (e.g., /dev/nvme1n1 /dev/nvme2n1).#### Usage Instructions
1. Set the RAID Types and Disks: Open the noscript and set the
MAIN_RAID_TYPE, CACHE_RAID_TYPE, MAIN_RAID_DISKS, and CACHE_RAID_DISKS variables at the top of the noscript.2. Save the Script: Save the noscript to a file, for example,
setup_raid_with_cache.sh.3. Make the Script Executable:
chmod +x setup_raid_with_cache.sh
4. View Help Menu: Run the noscript with the
--help or -h option to view the help menu:sudo ./setup_raid_with_cache.sh --help
5. Run the Script as Root or with
sudo:sudo ./setup_raid_with_cache.sh
#### Example Configuration
MAIN_RAID_TYPE=10
CACHE_RAID_TYPE=0
MAIN_RAID_DISKS=(/dev/sdc /dev/sdd /dev/sde /dev/sdf)
CACHE_RAID_DISKS=(/dev/nvme1n1 /dev/nvme2n1)
sudo ./setup_raid_with_cache.sh
### Sourcing the noscript
You can get the noscript on GitHub here
https://redd.it/1e84grh
@r_bash
GitHub
noscript-repo/Bash/Misc/System/setup_raid_with_cache.sh at main · slyfox1186/noscript-repo
My personal noscript repository with multiple languages supported. AHK v1+v2 | BASH | BATCH | JSON | PERL | POWERSHELL | PYTHON | WINDOWS REGISTRY | XML - slyfox1186/noscript-repo
Best Bash Learning Resources?
Hello there,
an intermediate software engineering student here
i want some good and beginner friendly bash sources to learn from
Note: i prefer reading that watching videos, so books/articles would be greatly appreciated.
https://redd.it/1e86doo
@r_bash
Hello there,
an intermediate software engineering student here
i want some good and beginner friendly bash sources to learn from
Note: i prefer reading that watching videos, so books/articles would be greatly appreciated.
https://redd.it/1e86doo
@r_bash
Reddit
From the bash community on Reddit
Explore this post and more from the bash community
Maelstrom: Open-Source Stress Test Tool for Your APIs
Hey Reddit!
I just open-sourced on MIT license a new stress test tool ("**Maelstrom**"), that was useful to me. It’s lightweight and designed to be efficient for testing API endpoints with configurable parameters. Here are some of its key features:
* **Customizable Parameters**: Set the number of requests, concurrency level, retry limits, and more.
* **Detailed Logging**: Keep track of HTTP status codes and response times.
* **Email Notifications**: Get summaries of test results via email (optional).
* **Graceful Shutdown**: Handles interruptions smoothly.
* **Latency Metrics**: Helps understand average latency of APIs
* **Graceful Shutdown**: Handles interruptions smoothly.
* **Multi-threaded by design**: Simulates multi-threaded concurrent requests to API Endpoints
GitHub: [https://github.com/twentyone24/maelstrom](https://github.com/twentyone24/maelstrom)
Check it out if you’re interested. I’d love to hear any feedback or suggestions!
Cheers! Thanks for your time :-)
https://redd.it/1e8glqo
@r_bash
Hey Reddit!
I just open-sourced on MIT license a new stress test tool ("**Maelstrom**"), that was useful to me. It’s lightweight and designed to be efficient for testing API endpoints with configurable parameters. Here are some of its key features:
* **Customizable Parameters**: Set the number of requests, concurrency level, retry limits, and more.
* **Detailed Logging**: Keep track of HTTP status codes and response times.
* **Email Notifications**: Get summaries of test results via email (optional).
* **Graceful Shutdown**: Handles interruptions smoothly.
* **Latency Metrics**: Helps understand average latency of APIs
* **Graceful Shutdown**: Handles interruptions smoothly.
* **Multi-threaded by design**: Simulates multi-threaded concurrent requests to API Endpoints
GitHub: [https://github.com/twentyone24/maelstrom](https://github.com/twentyone24/maelstrom)
Check it out if you’re interested. I’d love to hear any feedback or suggestions!
Cheers! Thanks for your time :-)
https://redd.it/1e8glqo
@r_bash
GitHub
GitHub - twentyone24/maelstrom: stress-test your API reliability on concurrent threads, with latency metrics.
stress-test your API reliability on concurrent threads, with latency metrics. - twentyone24/maelstrom